12x Faster Audio Generation Without Discrete Tokens: Kyutai's CALM Framework
What if you could throw away the discrete audio tokens that every major speech AI system relies on, and get both faster AND better audio generation?
Every major audio language model today relies on the same foundation: discrete tokens produced by lossy audio codecs. Higher audio quality demands more tokens through deeper Residual Vector Quantization (RVQ) hierarchies [10], but this imposes a fundamental tradeoff - better fidelity requires proportionally more compute. For edge devices like laptops and phones, this makes high-quality speech and music generation prohibitively expensive.
Building on the Masked Autoregressive (MAR) framework that eliminated vector quantization for image generation [1], researchers from Kyutai have introduced Continuous Audio Language Models (CALM), a fundamentally different approach. Rather than tokenizing audio into discrete codes, CALM generates directly in a continuous latent space using a single-step consistency model [7]. The result is 12.3x faster sampling with higher audio quality than discrete baselines - and a 100M-parameter text-to-speech model called Pocket TTS that runs faster than real-time on a laptop CPU.
The Discrete Token Problem
Current audio generation systems like MusicGen [3] and Moshi [2] encode audio using RVQ-based codecs such as SoundStream [10] or EnCodec. These codecs quantize audio into a finite vocabulary of tokens, introducing lossy compression at each quantization level. To achieve acceptable quality, systems must generate across 8-32 RVQ levels, multiplying the sequence length and computational cost proportionally. CALM sidesteps this entirely by operating in continuous space with a single generation step.
How CALM Works
CALM introduces a three-component architecture that replaces both the discrete codec and the multi-step generation process.
First, a VAE-GAN encoder maps raw audio waveforms into continuous latent vectors (32 dimensions for speech at 12.5 Hz, 128 dimensions for music at 25 Hz). Unlike RVQ-based codecs, this preserves information without quantization loss - achieving a ViSQOL score of 4.01 for music reconstruction compared to 3.63 for a 32-level RVQ-VAE.
Second, a dual-context transformer system captures both long-range structure and local detail. The causal backbone transformer (up to 2.2B parameters for speech) receives noise-augmented latent inputs, following the insight from Pasini et al. [9] that noise injection during training prevents error accumulation at inference. Complementing this, a lightweight short-context transformer (4 layers, 113M parameters) attends to the 10 most recent clean latents (~0.4 seconds) to preserve fine-grained audio detail. Ablation studies demonstrate this dual-context design is critical: removing the short-context transformer increases the Frechet Audio Distance (FAD) from 0.93 to 4.03 - a 77% quality degradation.
Third, a compact MLP-based consistency model head takes the summed context from both transformers and generates the next audio frame in a single step. This replaces the hundreds of denoising steps required by diffusion-based approaches, achieving up to 20x sampler speedup compared to the TrigFlow formulation [6] while maintaining comparable quality. Additional training techniques include Gaussian Temperature Sampling for continuous diversity control, Head Batch Multiplier to amortize backbone computation across noise samples, and Latent Classifier Free Guidance applied on backbone outputs for conditioned generation.
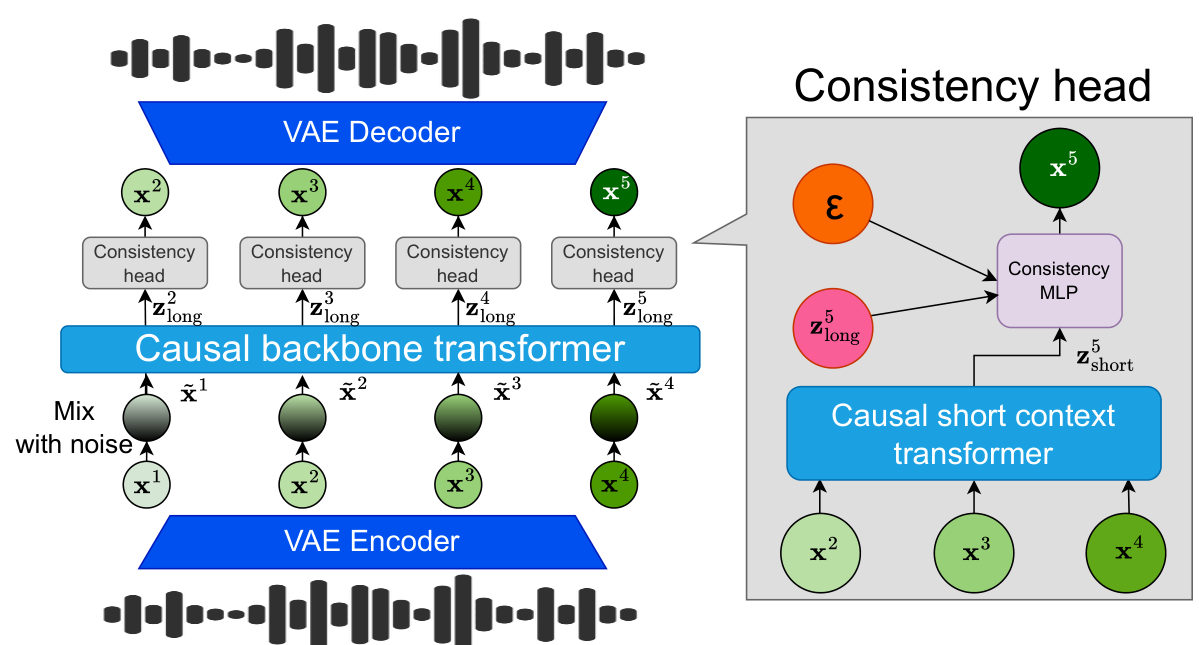 CALM ArchitectureThe full CALM pipeline showing VAE encoding, noise-augmented backbone transformer for long-range context, short-context transformer for local detail, and the single-step consistency MLP head that generates continuous audio frames.
CALM ArchitectureThe full CALM pipeline showing VAE encoding, noise-augmented backbone transformer for long-range context, short-context transformer for local detail, and the single-step consistency MLP head that generates continuous audio frames.
Results: Faster and Better
On speech continuation, CALM with 1-step consistency achieves a 12.3x sampler speedup over the equivalent RQ-Transformer with 8 RVQ levels, while improving acoustic quality MOS from 2.75 to 3.45 (+0.70 points) and meaningfulness Elo from 1870 to 2023 (+153 points).
 Speech Continuation ResultsComparison of CALM Consistency (1-step) versus RQ-Transformer baselines on speech continuation, showing speedup, perplexity, acoustic quality MOS, and meaningfulness Elo. CALM achieves superior quality with 12.3x faster sampling.
Speech Continuation ResultsComparison of CALM Consistency (1-step) versus RQ-Transformer baselines on speech continuation, showing speedup, perplexity, acoustic quality MOS, and meaningfulness Elo. CALM achieves superior quality with 12.3x faster sampling.
For music continuation, CALM achieves 2.2x overall speedup (19.3x sampler speedup) over a 32-RVQ baseline while reducing FAD from 1.06 to 0.83 - a 21.7% quality improvement. The overall speedup is lower than sampler speedup because backbone computation dominates total inference time. The best-quality configuration using 100-step TrigFlow reaches an enjoyment Elo of 1921 versus 1824 for the discrete baseline. For text-to-music generation using CLAP conditioning, CALM achieves a FAD of 2.14 on MusicCaps, competitive with MusicGen Medium (3.40).
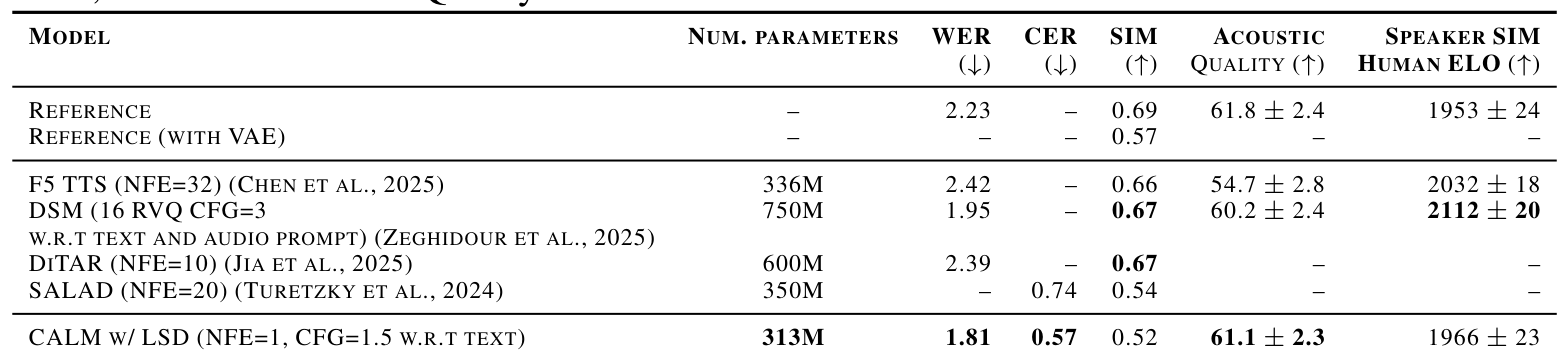
In text-to-speech evaluation, CALM achieves the best word error rate (1.81%) among all compared models, outperforming F5-TTS [4] (2.42%), DiTAR [3] (2.39%), and DSM [8] (1.95%). F5-TTS requires 32 function evaluations via flow matching, while DiTAR uses 10 diffusion steps per token - CALM needs just one. Acoustic quality reaches a MUSHRA score of 61.1, approaching the ground truth reference of 61.8.
Pocket TTS, the distilled 100M-parameter model (compressed from a 24-layer teacher down to 6 layers via Latent Distillation), matches DSM [8] (750M parameters) on WER at 1.84% while achieving the best audio quality Elo (2016) among compared systems. It generates speech at 6x real-time speed on an Apple M4 MacBook Air - making it practical for edge deployment without GPU access.
Research Context
This work builds on the MAR framework [1] that first demonstrated autoregressive generation in continuous space for images, and the Moshi architecture [2] from the same research group at Kyutai.
What's genuinely new:
- Replacing diffusion heads with consistency models for audio, achieving comparable quality in 1 step versus 100+ diffusion steps
- Dual-context architecture combining noisy long-term and clean short-term transformers, balancing error robustness with local detail
- Comprehensive application across 4 tasks (speech/music continuation, TTS, text-to-music) with a single framework - prior continuous audio work was limited to TTS only
Compared to DiTAR [3] (the strongest competitor, accepted at ICML 2025), CALM achieves comparable audio quality with 10-43x less compute at inference (1 consistency step versus 10 diffusion steps). For scenarios requiring precise speaker similarity (voice cloning), DiTAR (0.67) significantly outperforms CALM (0.52), suggesting the continuous VAE representation may lose speaker-discriminative spectral information.
Open questions:
- Why does the continuous VAE representation lose speaker-discriminative information (similarity drops to 0.57 through VAE reconstruction alone)?
- Can CALM scale beyond 3B parameters effectively, and what are the scaling laws for continuous audio generation?
- How does the approach handle multi-speaker, overlapping speech, or longer-form generation beyond 30 seconds?
Limitations
Speaker similarity remains CALM's primary weakness: automatic metrics show 0.52 versus 0.66-0.67 for competing approaches, though the VAE reconstruction itself already reduces similarity to 0.57. The consistency model also exhibits an unusual failure mode where quality degrades beyond 10 inference steps (FAD increases from 0.71 at 4 steps to 2.05 at 100 steps). Text-to-music experiments use CLAP conditioning rather than direct text, limiting the fairness of comparisons with systems trained on paired text-music data.
Check out the Paper, GitHub, and HuggingFace model. All credit goes to the researchers.
References
[1] Li, T. et al. (2024). Autoregressive Image Generation without Vector Quantization. NeurIPS 2024 (Spotlight). arXiv
[2] Défossez, A. et al. (2024). Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint. arXiv
[3] Jia, D. et al. (2025). DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation. ICML 2025. arXiv
[4] Chen, Y. et al. (2025). F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. ACL 2025. arXiv
[5] Copet, J. et al. (2023). Simple and Controllable Music Generation (MusicGen). NeurIPS 2023. arXiv
[6] Lu, C. & Song, Y. (2025). Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models. ICLR 2025. arXiv
[7] Song, Y. et al. (2023). Consistency Models. ICML 2023. arXiv
[8] Zeghidour, N. et al. (2025). Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling. NeurIPS 2025. arXiv
[9] Pasini, M. et al. (2024). Continuous autoregressive models with noise augmentation avoid error accumulation. NeurIPS Audio Imagination Workshop 2024. arXiv
[10] Zeghidour, N. et al. (2021). SoundStream: An End-to-End Neural Audio Codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing. arXiv


