Voice Search Breaks in Noise: SQuTR Benchmark Reveals the Real Bottleneck
Your voice search system just failed in a noisy cafe. Was it the speech recognition or the retriever that let you down?
Voice search is everywhere—from smart speakers to in-car navigation—yet the systems powering it are evaluated in ways that miss a critical failure mode. ASR benchmarks measure transcription accuracy (word error rate), and information retrieval benchmarks assume perfectly typed queries. Neither captures what happens when a spoken query travels through a noisy cafe, a busy street, or a factory floor before reaching the retrieval engine. Building on earlier work examining how ASR errors degrade passage retrieval [1], a team of researchers from Huazhong University of Science and Technology, the University of Hong Kong, Soochow University, USTC, Wuhan University, Tsinghua University, and the University of Tokyo has introduced SQuTR—the first large-scale benchmark designed to systematically evaluate spoken query retrieval robustness under controlled acoustic noise.
The result that stands out most: a tiny 39M-parameter ASR model paired with a strong dense retriever outperforms a 1.55B-parameter ASR model paired with keyword search by 63.5%. For teams building voice search systems, the retriever matters far more than the speech recognizer.
What SQuTR Measures and Why It Matters
SQuTR bridges two evaluation worlds that have historically operated in isolation. ASR robustness benchmarks like Speech Robust Bench [3] stop at transcription-level metrics—they tell you how many words were misrecognized but not whether the final search results suffered. Text retrieval benchmarks like BEIR [10] and MTEB [8] assume clean typed queries and ignore speech input entirely. SQuTR closes this gap by measuring end-to-end retrieval performance directly from audio input under graded noise conditions.
The benchmark aggregates 37,317 unique queries from six established English and Chinese text retrieval datasets, including FiQA, HotpotQA, Natural Questions, MedicalRetrieval, DuRetrieval, and T2Retrieval. Speech is synthesized using CosyVoice-3 with 200 diverse real speaker voice profiles, and 17 categories of real-world environmental noise from the DEMAND and NOISEX-92 databases are mixed at controlled signal-to-noise ratios (SNR). This produces four acoustic conditions—Clean, Low Noise (20 dB), Medium Noise (10 dB), and High Noise (0 dB)—yielding 149,268 total evaluation instances.
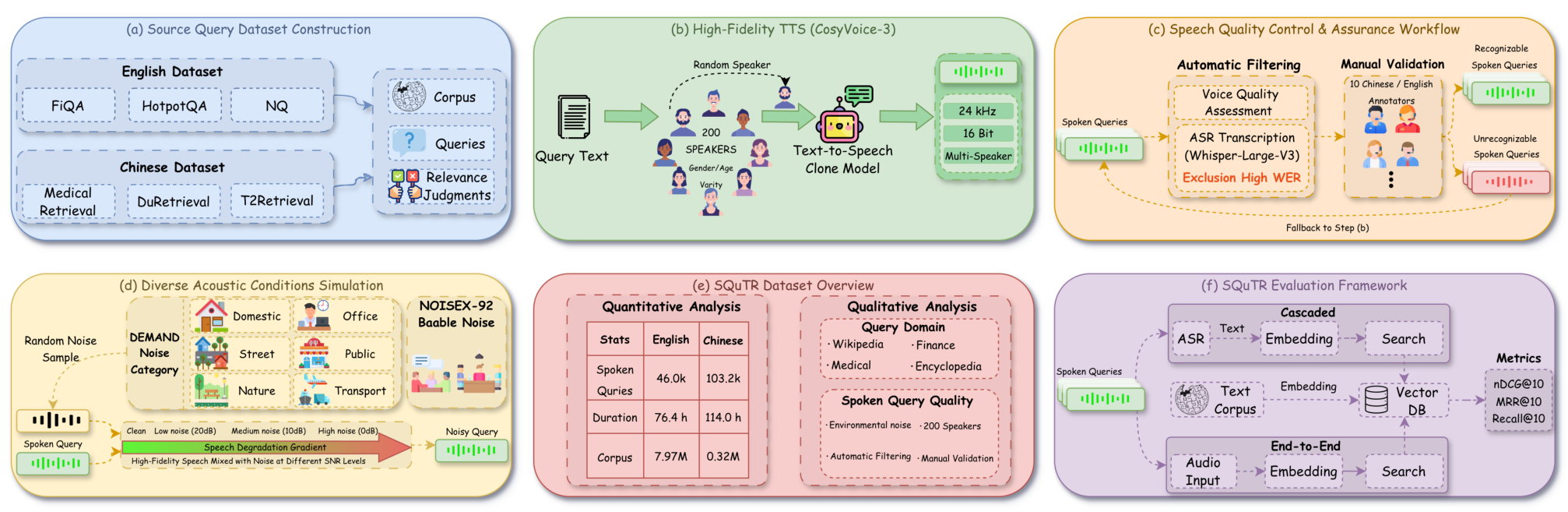 SQuTR PipelineThe complete benchmark pipeline showing query collection from six IR datasets, speech synthesis with 200 speakers, quality control, noise simulation at four acoustic conditions, and the unified evaluation framework for cascaded and end-to-end retrieval.
SQuTR PipelineThe complete benchmark pipeline showing query collection from six IR datasets, speech synthesis with 200 speakers, quality control, noise simulation at four acoustic conditions, and the unified evaluation framework for cascaded and end-to-end retrieval.
A rigorous multi-stage quality control pipeline ensures data integrity: automated ASR verification filters out poorly synthesized speech (WER threshold ≤ 0.30), dual-LLM consensus scoring from Gemini and GPT judges enforces a minimum quality bar, and 10 bilingual human annotators perform final verification.
Key Finding: The Retriever Is the Real Bottleneck
The most actionable finding from SQuTR's evaluation of 12 retrieval backends and 6+ ASR systems is that retriever quality dominates ASR model size. Whisper-Tiny (39M parameters) paired with Qwen3-Embedding-8B achieves 0.5862 nDCG@10 (Normalized Discounted Cumulative Gain at rank 10, a standard retrieval accuracy metric) on clean English speech—while Whisper-Large-v3 (1.55B parameters) paired with BM25 keyword search reaches only 0.3586. That is a 63.5% advantage for the configuration with the smaller ASR model but the stronger retriever.
This finding has direct deployment implications. As the authors note, "semantic robustness effectively compensates for ASR transcription errors where lexical matching fails." Dense embedding models match on meaning rather than exact keywords, so a misrecognized word is less likely to derail the search.
The Accuracy-Stability Tradeoff
Not all retrieval systems degrade equally under noise. SQuTR introduces an accuracy-stability analysis that plots mean nDCG@10 against standard deviation across noise conditions. BM25 is the most stable system (σ = 0.031), roughly 3.2× more stable than BERT-based dense retrievers like BGE-Base (σ = 0.100)—but at substantially lower absolute accuracy.
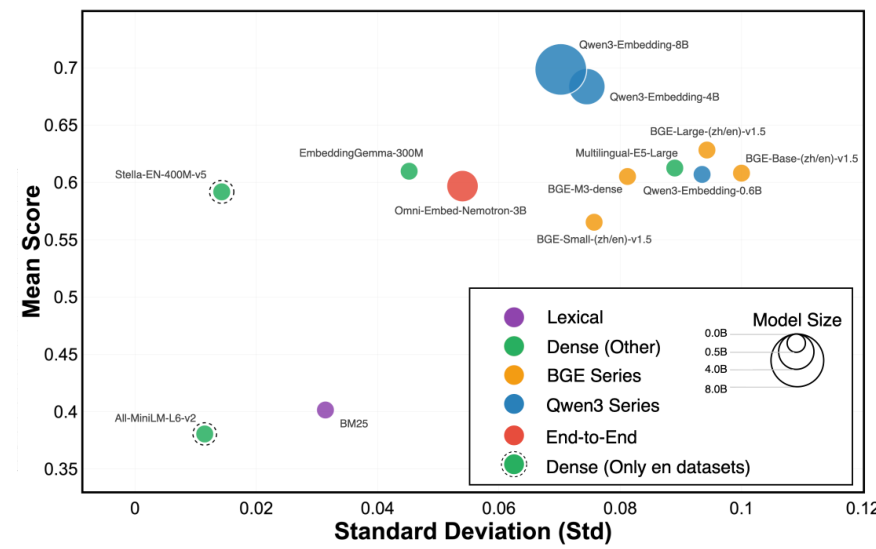 Accuracy vs StabilityScatter plot showing the tradeoff between mean retrieval accuracy (nDCG@10) and stability (standard deviation) across noise conditions, with BM25 as the most stable but least accurate system.
Accuracy vs StabilityScatter plot showing the tradeoff between mean retrieval accuracy (nDCG@10) and stability (standard deviation) across noise conditions, with BM25 as the most stable but least accurate system.
Scaling model size helps on both dimensions: Qwen3-Embedding-8B achieves both higher accuracy and lower variance (σ = 0.070) compared to its 0.6B variant (σ = 0.094), a 26% reduction in variance. Even the best model, however, cannot match text-only retrieval performance under high noise—Qwen3-Embedding-8B drops from 0.8033 nDCG@10 on clean text to 0.7302 at 0 dB SNR on Chinese, a 9.1% relative decline.
Cascaded vs. End-to-End Systems
Beyond comparing retriever architectures, SQuTR also provides the first controlled comparison between cascaded (ASR + text retriever) and end-to-end retrieval systems under identical noise conditions. The end-to-end model Omni-Embed-Nemotron-3B [6], which maps audio directly to retrieval embeddings, shows competitive stability (σ = 0.054) but lags behind the best cascaded pipelines in absolute performance—reaching 0.6648 nDCG@10 on clean Chinese speech versus 0.7760 for the best cascaded system. Other end-to-end approaches exist—SpeechDPR [2] pioneered end-to-end spoken passage retrieval, and SpeechRAG [5] bypasses ASR for retrieval-augmented generation—but neither was publicly available for evaluation. With Omni-Embed-Nemotron as the sole end-to-end representative, the cascaded vs. end-to-end question remains partially unresolved.
Research Context
This work builds on Sidiropoulos et al. [1], the first systematic study of ASR error propagation to passage retrieval, and Speech Robust Bench [3], which benchmarked ASR robustness with 114 perturbations but stopped at transcription metrics.
One important caveat: SQuTR uses TTS-synthesized speech (CosyVoice-3) rather than real recorded speech. This enables controlled evaluation but means results may not fully capture the disfluencies, accent variation, and recording artifacts present in real-world voice queries. The benchmark also considers only additive noise, leaving reverberation and codec artifacts for future work.
What's genuinely new:
- First benchmark with controlled, graded SNR levels (Clean, 20 dB, 10 dB, 0 dB) for spoken query retrieval
- Bridges the evaluation gap between ASR benchmarks (WER/CER) and IR benchmarks (clean text queries)
- Large-scale bilingual design: 37K+ queries, 149K evaluation instances across English and Chinese
Compared to MSEB [4], the broader NeurIPS 2025 audio benchmark covering 8 tasks and 17 languages, SQuTR is narrower but deeper—offering controlled noise grading that MSEB's retrieval track does not provide. For comprehensive audio evaluation across tasks, MSEB is the better choice; for systematic noise robustness analysis of retrieval systems specifically, SQuTR fills a distinct gap.
Open questions:
- Can noise-aware training of retrievers close the gap between clean and noisy performance without sacrificing clean-condition accuracy?
- How would real recorded speech with natural disfluencies compare to the TTS-generated queries used in this benchmark?
- Can the accuracy-stability tradeoff observed between BM25 and dense retrievers be broken by noise-aware embedding models?
Check out the Paper, GitHub, and Dataset on Hugging Face. All credit goes to the researchers.
References
[1] Sidiropoulos, G. et al. (2022). On the Impact of Speech Recognition Errors in Passage Retrieval for Spoken Question Answering. CIKM 2022. arXiv
[2] Lin, C. et al. (2024). SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering. ICASSP 2024. arXiv
[3] Shah, M. A. et al. (2024). Speech Robust Bench: A Robustness Benchmark For Speech Recognition. arXiv preprint. arXiv
[4] Heigold, G. et al. (2025). Massive Sound Embedding Benchmark (MSEB). NeurIPS 2025 Datasets & Benchmarks. arXiv
[5] Min, D. J. et al. (2025). Speech Retrieval-Augmented Generation without Automatic Speech Recognition. ICASSP 2025. arXiv
[6] Xu, M. et al. (2025). Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video. arXiv preprint. arXiv
[7] Zhang, Y. et al. (2025). Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. arXiv preprint. arXiv
[8] Muennighoff, N. et al. (2023). MTEB: Massive Text Embedding Benchmark. EACL 2023. arXiv
[9] Radford, A. et al. (2022). Robust Speech Recognition via Large-Scale Weak Supervision. arXiv preprint. arXiv
[10] Thakur, N. et al. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. NeurIPS 2021 Datasets & Benchmarks. arXiv