Even GPT-5 Fails at Discovery: OdysseyArena Exposes the Inductive Bottleneck in LLM Agents
Your LLM agent can follow instructions perfectly -- but can it figure out the rules on its own?
LLM-based agents are being deployed at an accelerating pace across software engineering, scientific research, and business automation. Most of these agents excel at a specific mode of intelligence: following instructions, applying provided rules, and executing multi-step plans within well-defined constraints. But what happens when the rules are hidden and the agent must discover them through trial and error? A new benchmark from researchers at Xi'an Jiaotong University, the University of Hong Kong, and the National University of Singapore reveals a stark answer: even frontier models like GPT-5 and Gemini 3 Pro Preview fundamentally struggle.
Unlike prior agent benchmarks such as AgentBench [1] and WebArena [2], which test how well agents execute tasks when given explicit instructions, OdysseyArena evaluates a different and arguably more important capability: whether agents can inductively learn the hidden dynamics of their environment from experience alone. The results expose what the authors term an "inductive bottleneck" -- a fundamental limitation that scaling alone cannot resolve.
The Deductive-Inductive Divide
The core insight behind OdysseyArena is the distinction between deductive and inductive reasoning in agent settings. In deductive mode, an agent receives the environment's rules upfront and reasons about how to apply them -- the paradigm tested by frameworks like ReAct [3] and Reflexion [4]. In inductive mode, the agent must discover those rules through active exploration, observing the consequences of its actions, and building an internal model of how the environment works. This aligns with the concept of measuring intelligence through skill-acquisition efficiency rather than task-specific performance [5].
Current benchmarks overwhelmingly test the deductive mode. OdysseyArena flips this paradigm by requiring agents to operate without knowing the transition dynamics -- much like how humans navigate novel real-world situations [6].
 OdysseyArena EnvironmentsDemonstrations of the four interactive environments: Turn On Lights (discrete logic), AI Trading (stochastic dynamics), Energy Dispatch (periodic patterns), and Repo System (relational dependencies).
OdysseyArena EnvironmentsDemonstrations of the four interactive environments: Turn On Lights (discrete logic), AI Trading (stochastic dynamics), Energy Dispatch (periodic patterns), and Repo System (relational dependencies).
Four Environments, Four Structural Primitives
The benchmark formalizes environment dynamics as generative state transition functions and decomposes them into four structural primitives, each instantiated as a concrete interactive environment:
Turn On Lights grounds discrete symbolic rules in a network of interdependent light bulbs. Toggling one light may trigger cascading state changes through hidden Boolean logic. The agent must systematically explore to uncover the latent dependency structure -- a task requiring hypothesis testing and causal reasoning.
AI Trading presents continuous stochastic dynamics through a multi-asset portfolio management scenario. Stock prices follow a hidden factor loading matrix obscured by noise, and the agent must disentangle meaningful market signals from random fluctuations to execute profitable long-horizon trading strategies.
Energy Dispatch models periodic temporal patterns in a power grid dispatch problem. Wind and solar efficiency follow cyclical patterns -- analogous to weather-driven seasonal variation -- that the agent must discover by observing discrepancies between planned and actual power output. Repeated budget or demand violations trigger irreversible grid failure, raising the stakes of exploration.
Repo System engages agents in relational graph structures through a software repository management task. The agent must resolve package dependency conflicts by deducing the hidden topology of a compatibility graph, where installing one package can trigger cascading side effects across the environment.
Benchmark Design
OdysseyArena provides two evaluation settings. OdysseyArena-Lite offers 120 standardized tasks (30 per environment) with interaction horizons of 120-200 steps, designed for efficient and reproducible evaluation. OdysseyArena-Challenge extends this to 1,000+ steps per task for stress-testing agent persistence and long-horizon reasoning stability.
A distinctive design choice is the API-based deployment model. Unlike OSWorld [7] (Docker), AndroidWorld (emulator), or ALFWorld (simulator), OdysseyArena requires only API calls to evaluate agents, significantly lowering the barrier to adoption. All task instances use pre-computed temporal trajectories, ensuring deterministic and fully reproducible evaluation across different runs and models.
Key Results: The Inductive Gap
Testing across over 15 LLMs (16 configurations spanning proprietary and open-source models) reveals a consistent and dramatic performance gap. Gemini 3 Pro Preview leads with a 44.17% average success rate on Turn On Lights -- but human participants achieve 81.67%. In AI Trading, the top model reaches +67.71% profit compared to +92.55% for humans. The gap widens further in Energy Dispatch, where 12 out of 16 model configurations score exactly 0.00%, and only three commercial models (Gemini 3 Pro Preview at 30.00%, GPT-5 at 23.33%, Gemini 2.5 Pro at 10.83%) achieve non-zero scores.
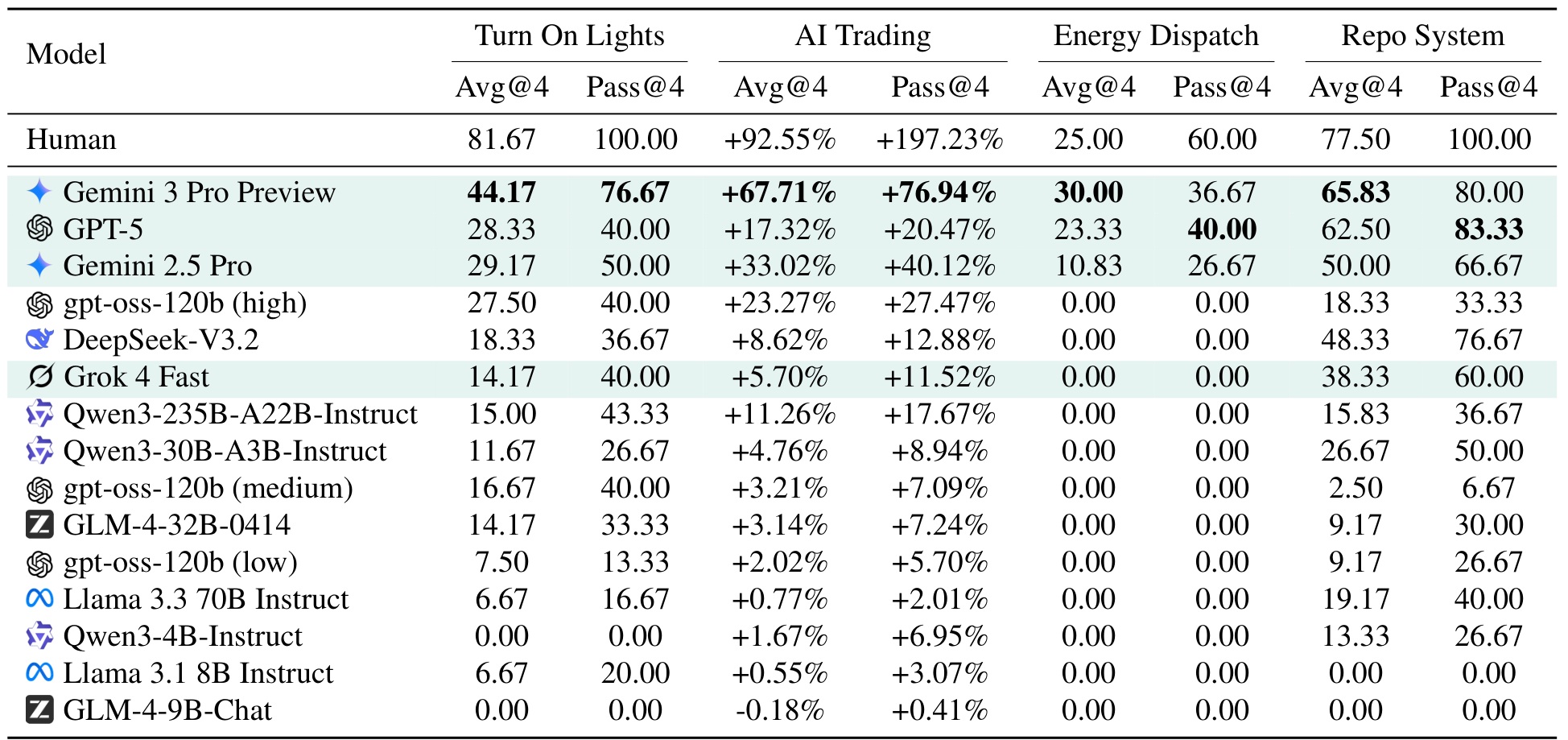 Main ResultsPerformance comparison across all four environments. Gemini 3 Pro Preview leads but all models fall significantly below human performance, with Energy Dispatch proving nearly impossible for current LLMs.
Main ResultsPerformance comparison across all four environments. Gemini 3 Pro Preview leads but all models fall significantly below human performance, with Energy Dispatch proving nearly impossible for current LLMs.
Perhaps the most revealing experiment isolates the inductive bottleneck directly. When provided with the hidden rules explicitly, frontier models achieve near-perfect success on Turn On Lights. Without those rules, performance drops precipitously. This confirms that the difficulty lies not in the task logic itself, but in the capacity to discover that logic autonomously.
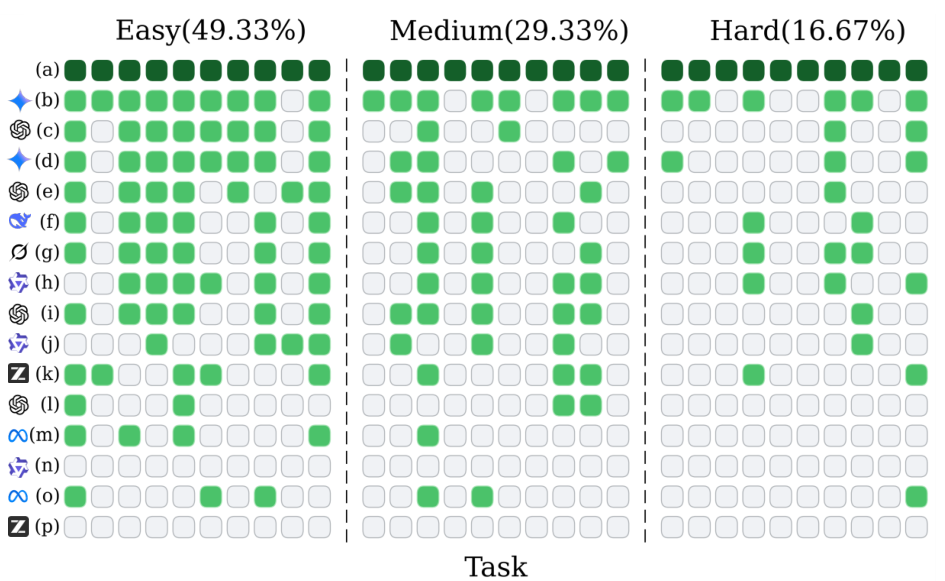 Deductive vs InductiveSuccess rate comparison with and without rules in Turn On Lights, demonstrating that models excel at applying given rules but struggle to discover them independently.
Deductive vs InductiveSuccess rate comparison with and without rules in Turn On Lights, demonstrating that models excel at applying given rules but struggle to discover them independently.
An analysis across difficulty levels reveals a distinct inductive ceiling: while humans solve all 30 Turn On Lights tasks perfectly, the best model (Gemini 3 Pro Preview) solves only 23. Six high-complexity tasks remain unsolved by any tested model, identifying a rigid barrier that current architectures cannot cross regardless of scale.
Failure Modes: Loops and Saturation
The analysis uncovers two systematic failure patterns. First, agents frequently fall into "action loops" -- repeating invalid operations despite receiving negative feedback from the environment. A higher loop ratio directly correlates with lower success rates, indicating that models fail to convert unsuccessful trials into updated hypotheses about the environment's dynamics.
Second, as illustrated in the figure below, increasing the interaction budget beyond an initial exploratory phase yields negligible gains for most models. This performance saturation suggests that the bottleneck is not a lack of interaction opportunities, but a fundamental inability to build coherent internal world models [8] from accumulated experience.
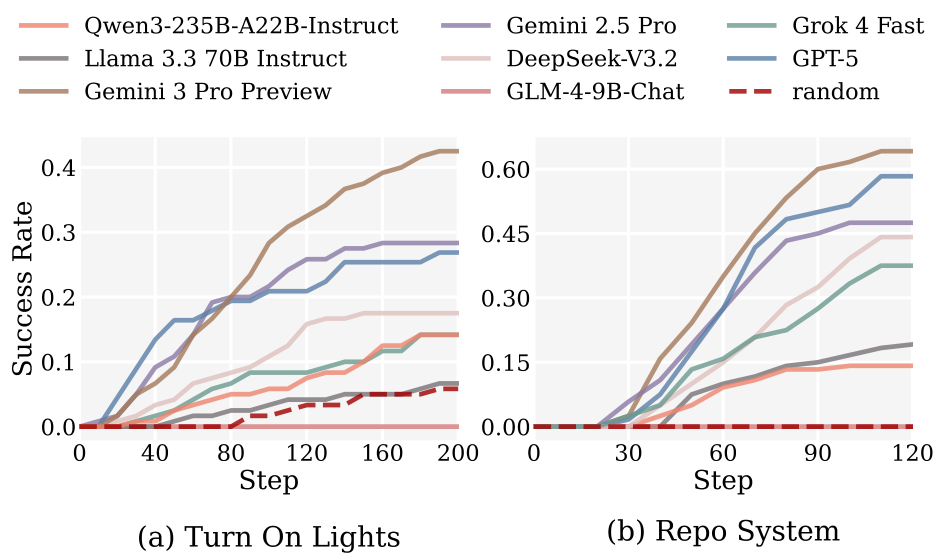 Performance SaturationSuccess rate plotted against interaction step count in Turn On Lights and Repo System, showing that additional steps yield diminishing returns for most models.
Performance SaturationSuccess rate plotted against interaction step count in Turn On Lights and Repo System, showing that additional steps yield diminishing returns for most models.
Research Context
This work extends the agent evaluation landscape established by AgentBench [1] and interactive reasoning benchmarks like MARS [9], which explored inductive reasoning in interactive settings but at shorter horizons. The theoretical framing connects to Chollet's work on measuring intelligence through skill-acquisition efficiency [5] and the world models paradigm [8].
What is genuinely new: OdysseyArena is the first benchmark to systematically isolate inductive reasoning in LLM agents through a formal taxonomy of four structural primitives, with interaction horizons (200-1000+ steps) far exceeding any existing agent benchmark. The deductive-vs-inductive experimental design cleanly demonstrates where the bottleneck lies.
Compared to MARS [9], the closest existing inductive benchmark, OdysseyArena provides cleaner isolation of induction from pre-trained knowledge, supports much longer horizons, and offers lightweight API-based evaluation. For practical deployment readiness testing, deductive benchmarks like WebArena [2] and OSWorld [7] remain better suited.
Open questions: Can the inductive bottleneck be overcome through better agent architectures, or does it require fundamentally different training approaches? How would reinforcement learning agents -- specifically designed for exploration -- perform on these tasks? And would scaling to even larger models begin to close the gap, or is inductive capacity an orthogonal dimension to scale?
Check out the Paper and GitHub repository. All credit goes to the researchers.
References
[1] Liu, X. et al. (2024). AgentBench: Evaluating LLMs as Agents. ICLR 2024. arXiv
[2] Zhou, S. et al. (2024). WebArena: A Realistic Web Environment for Building Autonomous Agents. ICLR 2024. arXiv
[3] Yao, S. et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. Paper
[4] Shinn, N. et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS 2023. Paper
[5] Chollet, F. (2019). On the Measure of Intelligence. arXiv preprint. arXiv
[6] Lake, B. M. et al. (2017). Building Machines That Learn and Think Like People. Behavioral and Brain Sciences. Paper
[7] Xie, T. et al. (2024). OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. NeurIPS 2024. arXiv
[8] Ha, D. & Schmidhuber, J. (2018). Recurrent World Models Facilitate Policy Evolution. NeurIPS 2018. Paper
[9] Tang, X. et al. (2024). MARS: Situated Inductive Reasoning in an Open-World Environment. NeurIPS 2024 Datasets and Benchmarks Track. Paper