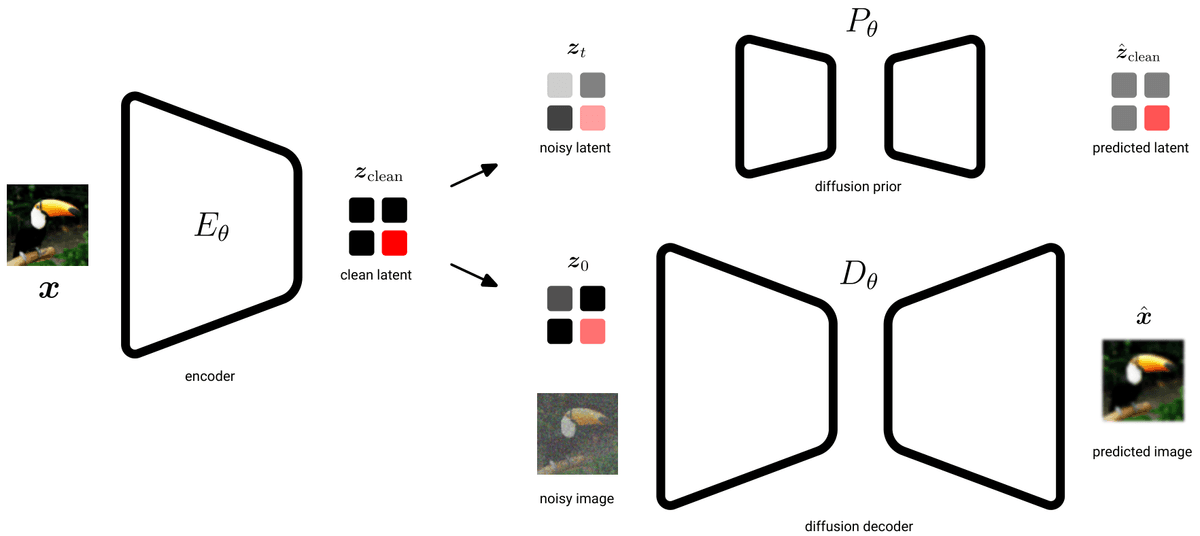
Unified Latents Hits 1.4 FID by Replacing Stable Diffusion's Ad Hoc VAE with a Diffusion PriorFebruary 2026Vision
3.5x Faster Image Generation: DDiT Dynamically Resizes Patches in Diffusion TransformersFebruary 2026Vision
Reasoning Overthinking Solved: SAGE Cuts Tokens 44% While Improving AccuracyFebruary 2026Infrastructure
Baidu Introduces ERNIE 5.0: Trillion-Parameter Unified Multimodal MoE Rivals GPT-5February 2026Vision
175% Faster Prefill with Better Accuracy: ConceptMoE's Adaptive Token Compression for MoEJanuary 2026Infrastructure
2x Faster VLA Inference with 70% Fewer Layers: Shallow-π Distillation for Edge RoboticsJanuary 2026Infrastructure
90% Attention Sparsity with Zero Quality Loss: SALAD Speeds Up Video Diffusion 1.7xJanuary 2026Infrastructure
FP8 Rollout Instability Solved: Jet-RL Unifies Precision for Stable RL TrainingJanuary 2026Infrastructure
Tsinghua Researchers Show Diffusion LLMs Reason Better When You Take Away Their FlexibilityJanuary 2026Infrastructure
97ms First-Packet Latency: Qwen3-TTS Beats ElevenLabs in Voice Cloning Across 10 LanguagesJanuary 2026Voice AI
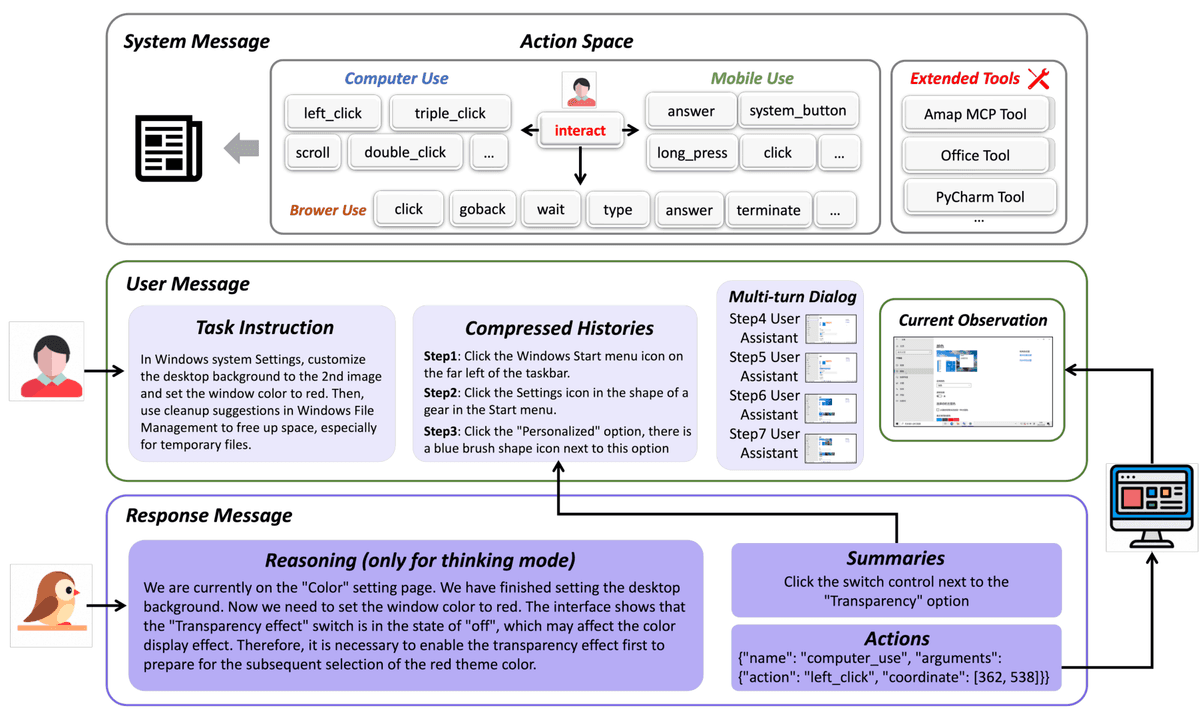
56.7% on OSWorld: EvoCUA's Evolutionary Training Beats Closed-Source Computer Use AgentsJanuary 2026AI Agents
Microsoft's Agent Lightning Decouples RL Training from Agent Logic, Enabling Fine-Tuning of Any AI Agent with Zero Code ChangesJanuary 2026Infrastructure
16x Faster On-Device Video Generation: Qualcomm's ReHyAt Distills Attention in 160 GPU HoursJanuary 2026Vision
6% Better Math Reasoning in Fewer Tokens: Multiplex Thinking Merges Multiple Paths into OneJanuary 2026Infrastructure
Zero Training Data, Full Performance: Dr. Zero Matches Supervised Search AgentsJanuary 2026Infrastructure