Baidu Introduces ERNIE 5.0: Trillion-Parameter Unified Multimodal MoE Rivals GPT-5
Baidu challenges GPT-5 and Gemini 3 Pro with the first publicly documented trillion-parameter model that natively unifies multimodal understanding and generation from scratch.
Most multimodal models today follow a late-fusion approach: take a pre-trained language model and bolt on modality-specific encoders and decoders. While practical, this creates what researchers call the "ability seesaw" problem—improving one modality often degrades another. Building on unified autoregressive frameworks like VILA-U [3] and DeepSeek-V3's MoE innovations [2], Baidu's ERNIE Team introduces ERNIE 5.0, a trillion-parameter foundation model that trains text, image, video, and audio simultaneously from scratch under a single objective.
Unlike GPT-5 [4] and other proprietary models that keep architectural details undisclosed, ERNIE 5.0 provides comprehensive technical documentation of its approach—enabling reproducibility and advancing open research. The result is a model that achieves competitive or superior performance across multiple benchmarks—scoring 74.01 on SimpleQA versus Gemini 3 Pro's [4] 69.33, while maintaining an activation rate below 3% through ultra-sparse mixture-of-experts routing.
Ultra-Sparse MoE Architecture
ERNIE 5.0's core innovation lies in its modality-agnostic expert routing. Rather than manually allocating specific experts to handle text, vision, or audio tokens, the model uses a shared router that dispatches all tokens to a common expert pool based solely on token representations. This design choice enables emergent specialization—the model learns on its own which experts should handle which modalities.
The architecture achieves trillion-parameter capacity with practical inference costs through ultra-sparse activation. With an activation rate below 3%, the model substantially expands its effective capacity without proportional increases in computational overhead. This represents a significant advancement over standard MoE implementations.
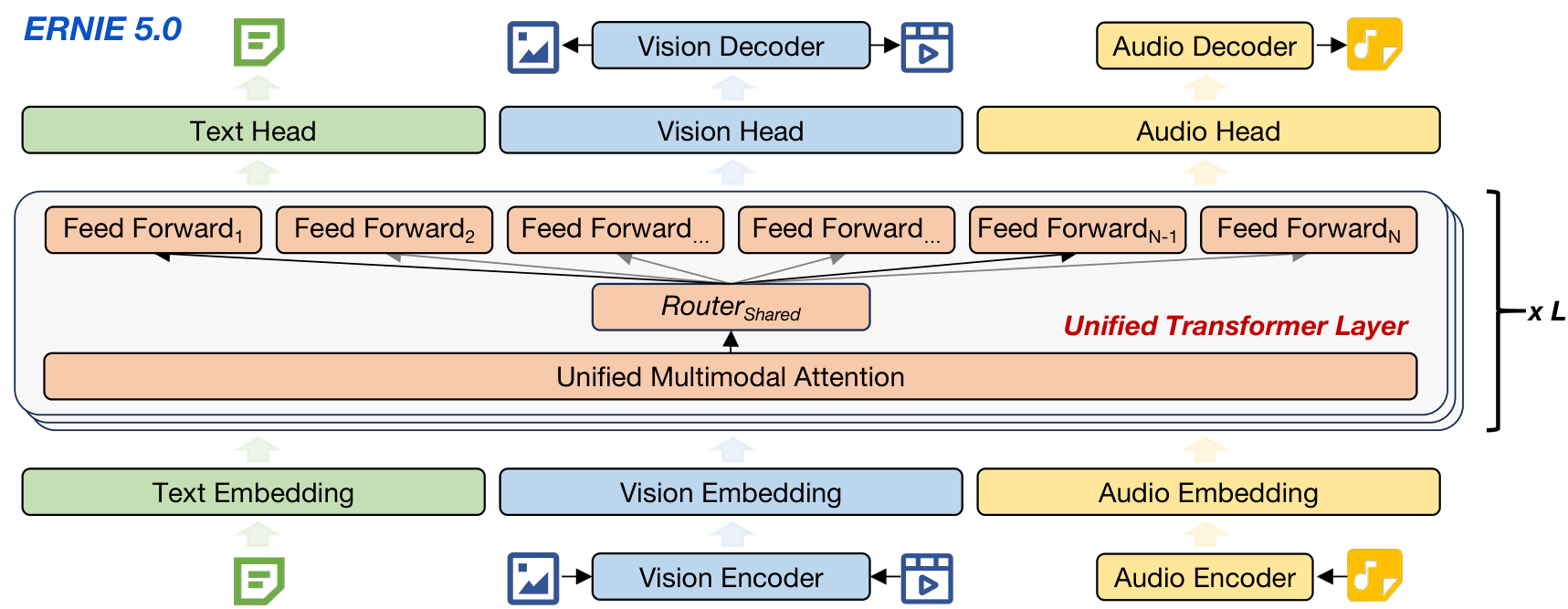 ERNIE 5.0 ArchitectureThe unified autoregressive framework with modality-specific encoders feeding into shared transformer layers with MoE routing and modality-specific output decoders.
ERNIE 5.0 ArchitectureThe unified autoregressive framework with modality-specific encoders feeding into shared transformer layers with MoE routing and modality-specific output decoders.
Unified Autoregressive Training
At the heart of ERNIE 5.0 is a unified "Next-Group-of-Tokens Prediction" objective—a generalized framework where the model predicts the next sequence of tokens regardless of modality, unifying text, vision, and audio generation under one paradigm. Each modality implements this differently:
- Text: Standard next-token prediction enhanced with Multi-Token Prediction (MTP) [8]
- Vision: Next-Frame-and-Scale Prediction (NFSP), treating images as single-frame videos for unified handling
- Audio: Next-Codec Prediction (NCP), distributing audio generation across transformer layers depth-wise
For visual understanding, the model employs a dual-path architecture combining CNN perceptual features with Vision Transformer semantic features through an attention-based patch merger. Visual generation uses multi-scale tokenization that enables autoregressive prediction across both spatial scales and temporal frames, building on the VideoAR paradigm [10].
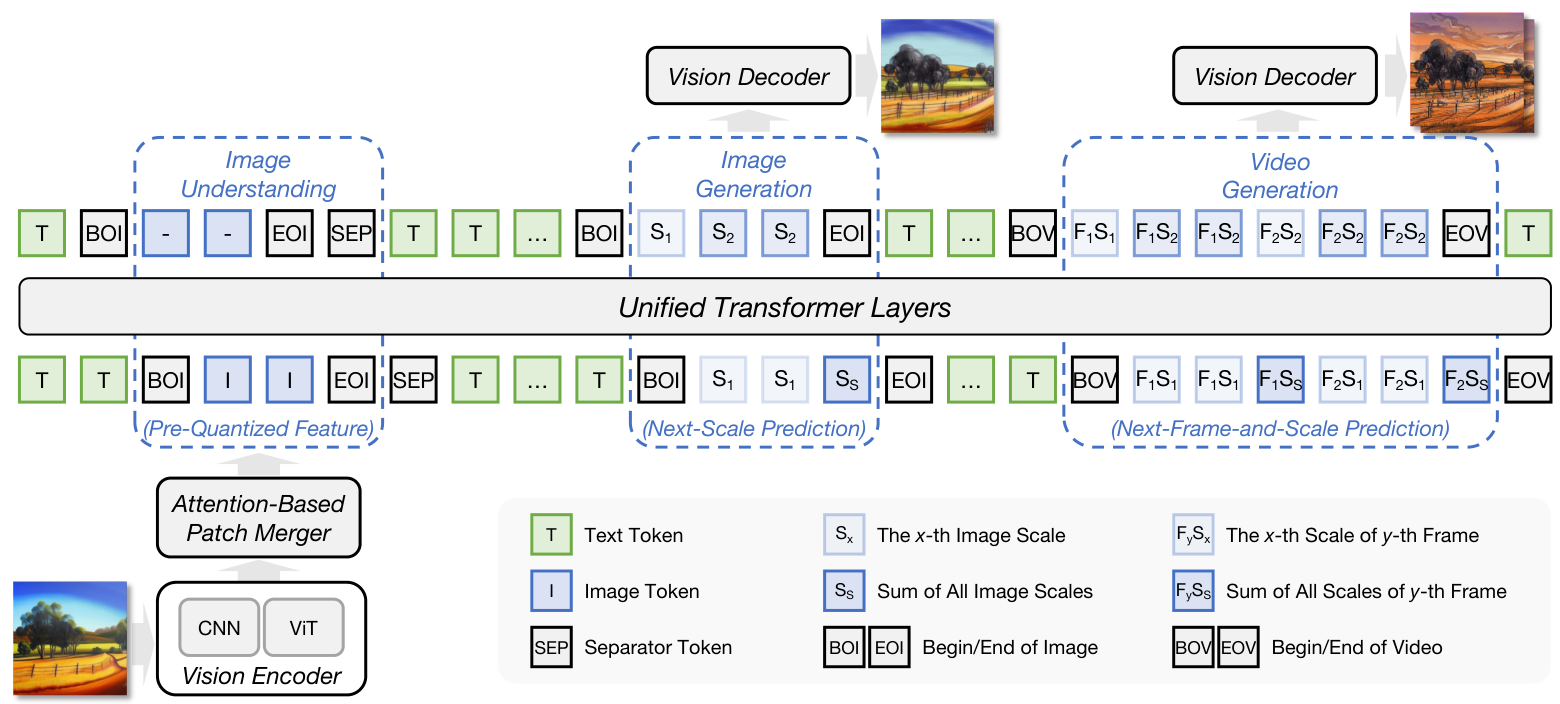 Vision ArchitectureThe dual-path CNN-ViT representation for understanding combined with Next-Frame-and-Scale Prediction paradigm for generation.
Vision ArchitectureThe dual-path CNN-ViT representation for understanding combined with Next-Frame-and-Scale Prediction paradigm for generation.
Elastic Training: One Training Run, Multiple Deployments
Perhaps the most production-relevant innovation is ERNIE 5.0's elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying:
- Depth: Different numbers of active transformer layers
- Width: Varying total number of experts
- Sparsity: Adjustable top-k routing configurations
This enables flexible deployment across diverse resource constraints. Reducing routing top-k to 25% during inference yields over 15% decoding speedup with only minor accuracy loss (74.43 average score versus 75.55 for the full model). When combining all elastic dimensions, the model achieves 75.17 average performance using only 53.7% of activated parameters and 35.8% of total parameters.
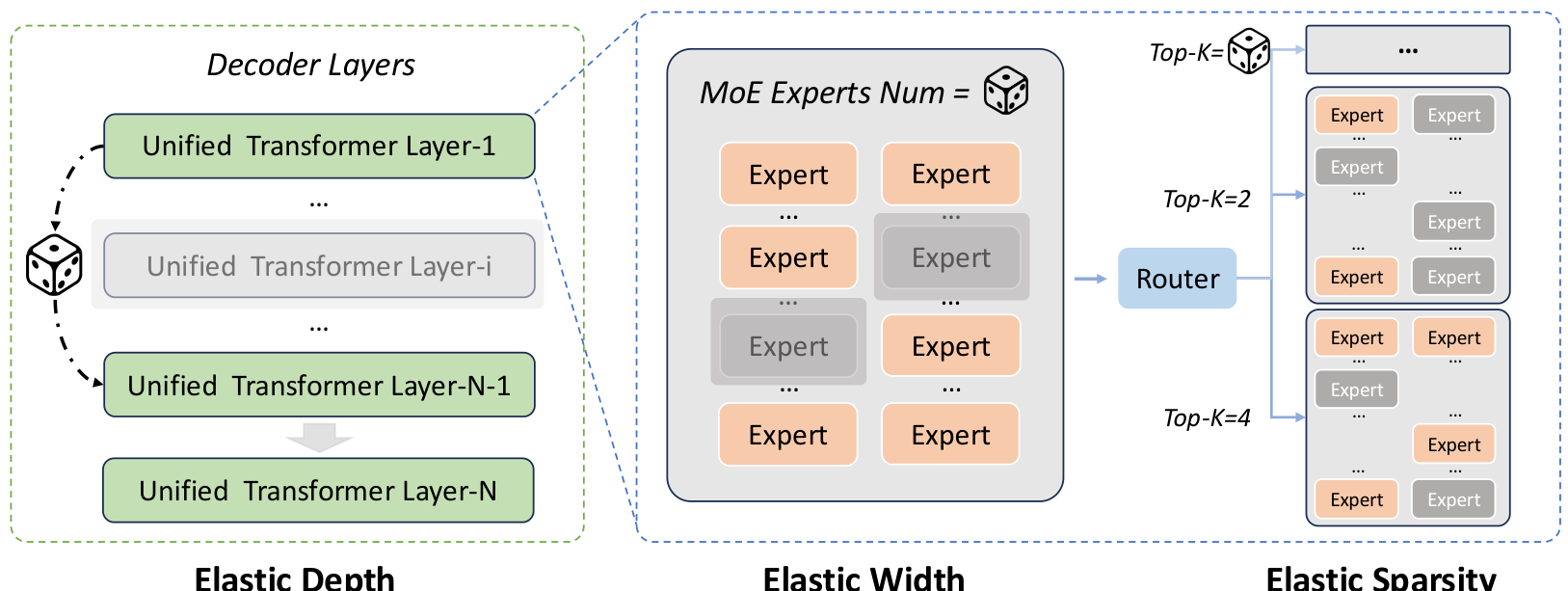 Elastic Training FrameworkThe three dimensions of elasticity—depth, width, and sparsity—that enable flexible deployment from a single pre-training run.
Elastic Training FrameworkThe three dimensions of elasticity—depth, width, and sparsity—that enable flexible deployment from a single pre-training run.
Benchmark Performance
ERNIE 5.0 demonstrates strong performance across multiple domains, particularly excelling in knowledge recall and instruction following:
Language Tasks:
- SimpleQA (factual knowledge recall): 74.01 vs Gemini 3 Pro's 69.33 and GPT-5's 51.30
- Multi-IF (instruction following): 85.56 vs Gemini 3 Pro's 81.15 and GPT-5's 70.00
- ACEBench-en (agent): 87.70 vs Gemini 3 Pro's 80.90
Vision Tasks:
- VLMAreBlind (reasoning): 91.38 vs Gemini 3 Pro's 80.83
- GenEval (image generation): 90.1, competitive with specialized image generators
- VBench-Semantic (video): 83.40 vs reported Veo3 baseline of 82.49
Audio Tasks:
- AISHELL-1 ASR (WER): 0.31 vs reported Kimi Audio baseline of 0.60 (lower is better)
- MMAU (understanding): 80.40, matching Gemini 3 Pro's 80.80
However, a moderate gap persists on the most challenging reasoning benchmarks—ERNIE 5.0 scores 86.36% on GPQA-Diamond compared to Gemini 3 Pro's 91.9%.
Research Context
This work builds on ERNIE 4.5 [1], which established modality-isolated routing strategies, and DeepSeek-V3 [2], which pioneered auxiliary-loss-free load balancing at scale. ERNIE 5.0 extends these with native multimodal training and modality-agnostic routing.
What's genuinely new:
- First publicly disclosed trillion-parameter unified autoregressive model supporting both multimodal understanding AND generation
- Modality-agnostic expert routing with demonstrated emergent specialization
- Elastic training across depth, width, AND sparsity simultaneously in MoE pre-training
Compared to Gemini 3 Pro [4], ERNIE 5.0 trades approximately 5-10% on peak reasoning benchmarks for superior factual knowledge, better instruction following, and transparent technical documentation. For applications requiring highest reasoning performance, Gemini 3 Pro remains the stronger choice. For deployments needing flexible compute-performance tradeoffs or strong Chinese language support, ERNIE 5.0 offers distinct advantages.
Open questions:
- How does modality-agnostic routing scale beyond four modalities (e.g., adding 3D, haptics)?
- Can elastic sub-models match the performance of independently trained models of equivalent size?
- What computational overhead does the cascaded diffusion refiner add to end-to-end visual generation?
Check out the Paper and Project Page. All credit goes to the researchers.
References
[1] ERNIE Team, Baidu. (2025). ERNIE 4.5 Technical Report. Technical Report. Paper
[2] Liu, A. et al. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv
[3] Wu et al. (2024). VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation. ICLR 2025. arXiv
[4] Google DeepMind. (2025). Gemini 3 Pro. Product Release. Link
[8] Gloeckle, F. et al. (2024). Better & Faster Large Language Models via Multi-token Prediction. ICML 2024. arXiv
[10] Ji, L. et al. (2026). VideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction. arXiv preprint. arXiv