3.5x Faster Image Generation: DDiT Dynamically Resizes Patches in Diffusion TransformersFebruary 2026Vision
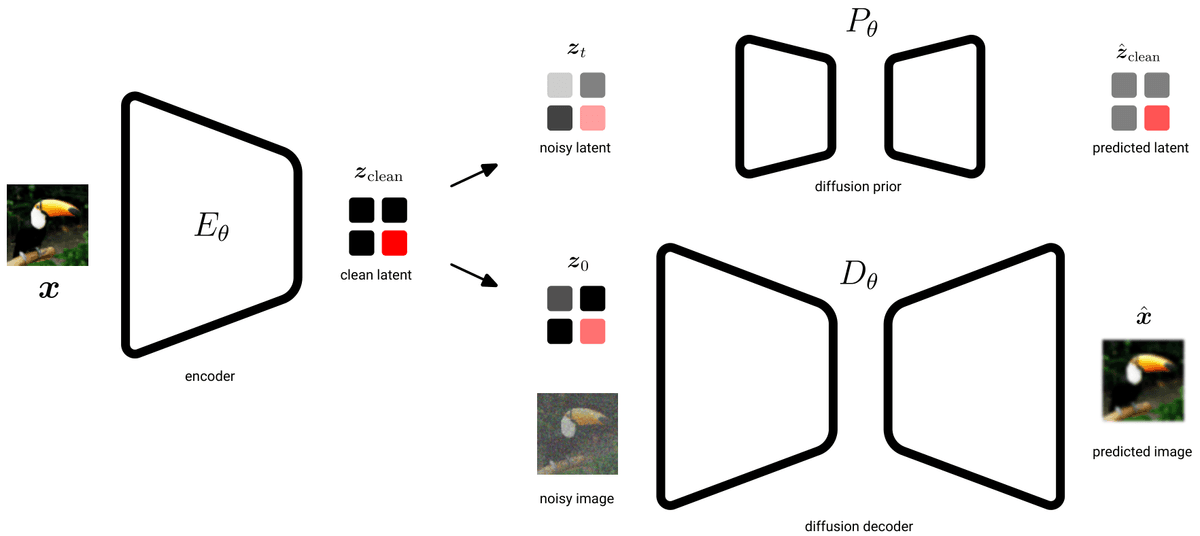
Unified Latents Hits 1.4 FID by Replacing Stable Diffusion's Ad Hoc VAE with a Diffusion PriorFebruary 2026Vision
Baidu Introduces ERNIE 5.0: Trillion-Parameter Unified Multimodal MoE Rivals GPT-5February 2026Vision
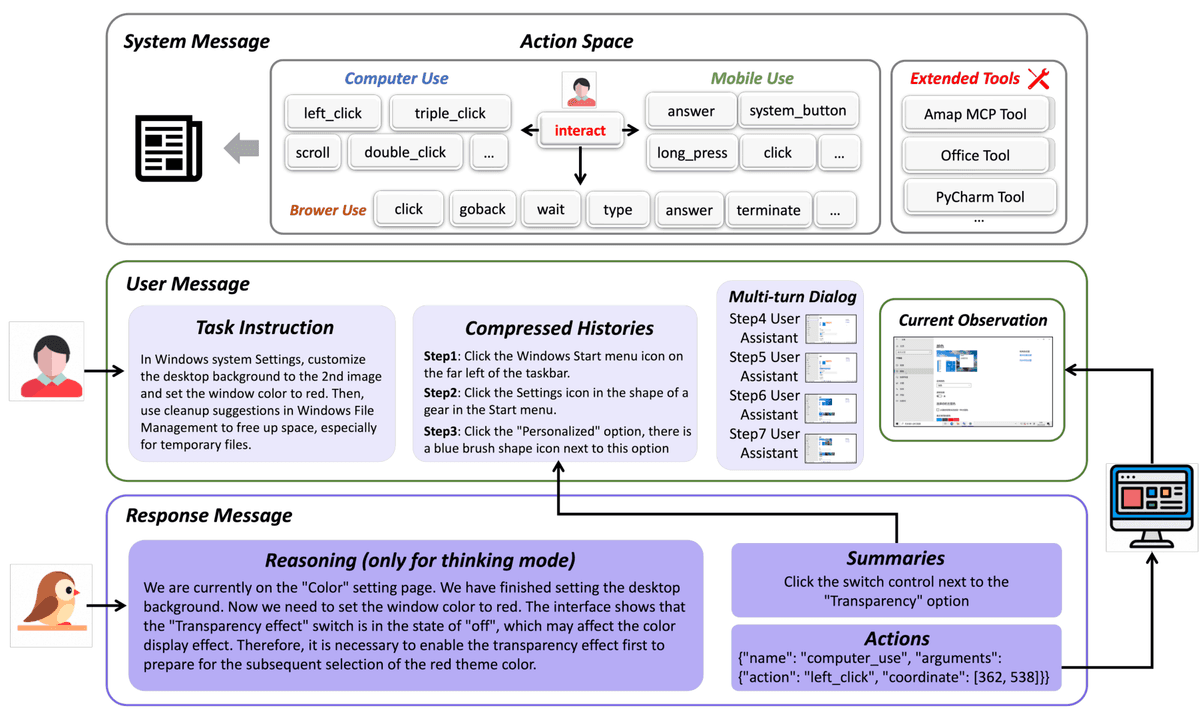
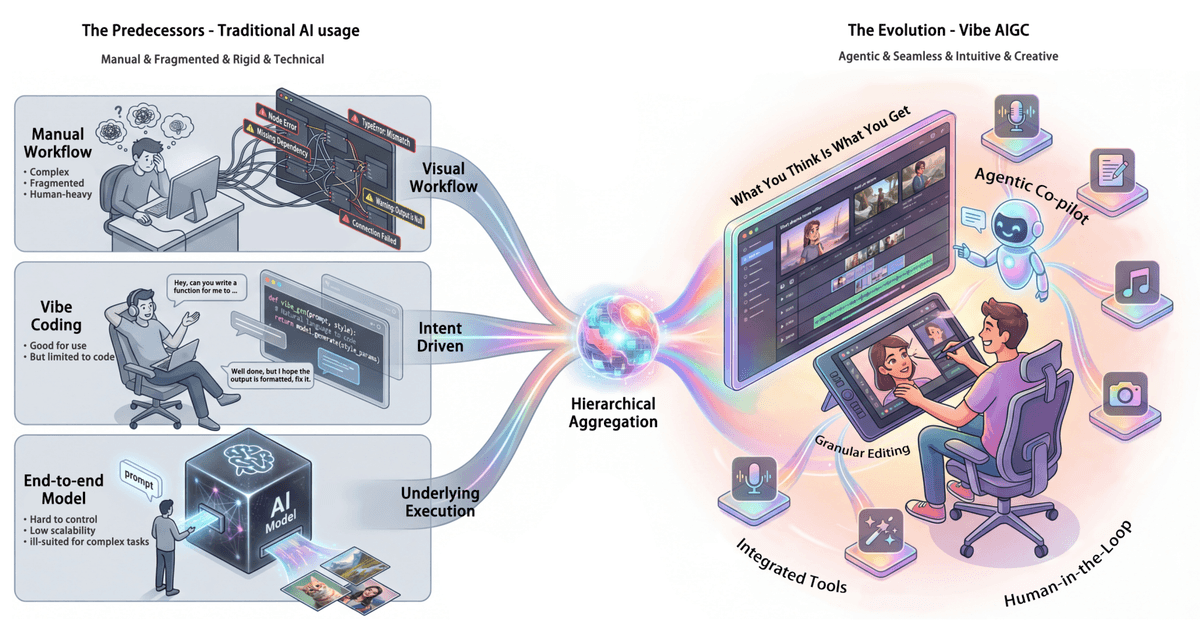
Prompt Fatigue Solved: Vibe AIGC Turns Users Into 'Commanders' of Multi-Agent Creative WorkflowsFebruary 2026AI Agents
Google Introduces Agentic Vision: Gemini 3 Flash Now Zooms, Annotates, and Investigates ImagesFebruary 2026AI Agents
2x Faster VLA Inference with 70% Fewer Layers: Shallow-π Distillation for Edge RoboticsJanuary 2026Infrastructure
90% Attention Sparsity with Zero Quality Loss: SALAD Speeds Up Video Diffusion 1.7xJanuary 2026Infrastructure
2.7x Better 3D Reconstruction from Messy Videos: Meta's ShapeR Tackles Real-World CaptureJanuary 2026Vision
40% Faster Video from Single Images: Pixel-to-4D Predicts Dynamic 3D Gaussians in One PassJanuary 2026Vision
VLM Hallucinations Exposed: VIB-Probe Pinpoints and Suppresses Faulty Attention HeadsJanuary 2026Safety
16x Faster On-Device Video Generation: Qualcomm's ReHyAt Distills Attention in 160 GPU HoursJanuary 2026Vision
Training-Free Fix Boosts Vision-Language Models 3 Points by Correcting Attention ErrorsJanuary 2026Vision