15-Hour Agent Runtimes Solved: Idea2Story Precomputes Research Knowledge Offline
Current AI research agents spend hours re-reading the same papers for every new idea. Idea2Story pre-builds a methodological knowledge graph offline, enabling faster retrieval-based research generation.
Autonomous AI research agents have demonstrated the ability to automate end-to-end research workflows, from ideation to experimentation. But there's a problem: systems like The AI Scientist [1] can take up to 15 hours to complete a single research pipeline. The culprit is runtime-centric execution - repeatedly reading, summarizing, and reasoning over large volumes of scientific literature for each new idea. This approach incurs high computational costs, bumps against context window limitations, and often leads to hallucinations.
Researchers from the AgentAlpha Team propose Idea2Story, a framework that takes a fundamentally different approach. Building on prior work in autonomous research agents [1, 2, 3], Idea2Story shifts literature understanding from online reasoning to offline knowledge construction. By pre-computing methodological knowledge into a structured knowledge graph, the system promises faster research generation with reduced hallucination risk.
The Core Insight: Pre-Computation Over Runtime Reasoning
The key innovation of Idea2Story is separating offline knowledge construction from online research generation. Rather than processing papers during each research attempt, the system constructs a knowledge graph ahead of time that captures reusable methodological patterns.
This addresses a fundamental inefficiency: even when underlying scientific knowledge is well-established, runtime-centric systems force models to repeatedly re-process the same information. Idea2Story argues that methodological knowledge is stable enough to pre-compute, accepting the tradeoff of potentially missing cutting-edge techniques in exchange for speed and reliability.
How It Works
Idea2Story operates in two distinct stages: offline knowledge graph construction and online retrieval-driven generation.
Offline Stage: Building the Knowledge Graph
The system curates approximately 13,000 papers from NeurIPS and ICLR over a three-year window, along with their peer review feedback. These papers undergo anonymization and safety filtering before being processed into reusable "method units."
Method units are self-contained descriptions of how research problems are formulated or solved, abstracted from implementation details. Each unit captures four aspects: the base problem, solution pattern, story skeleton, and application domain. These units are embedded using UMAP for dimensionality reduction and clustered via DBSCAN into research patterns.
The resulting knowledge graph encodes canonicalized method units as nodes, with edges representing composition relations observed in accepted papers. Reviewer feedback is incorporated as additional signals to refine these relations.
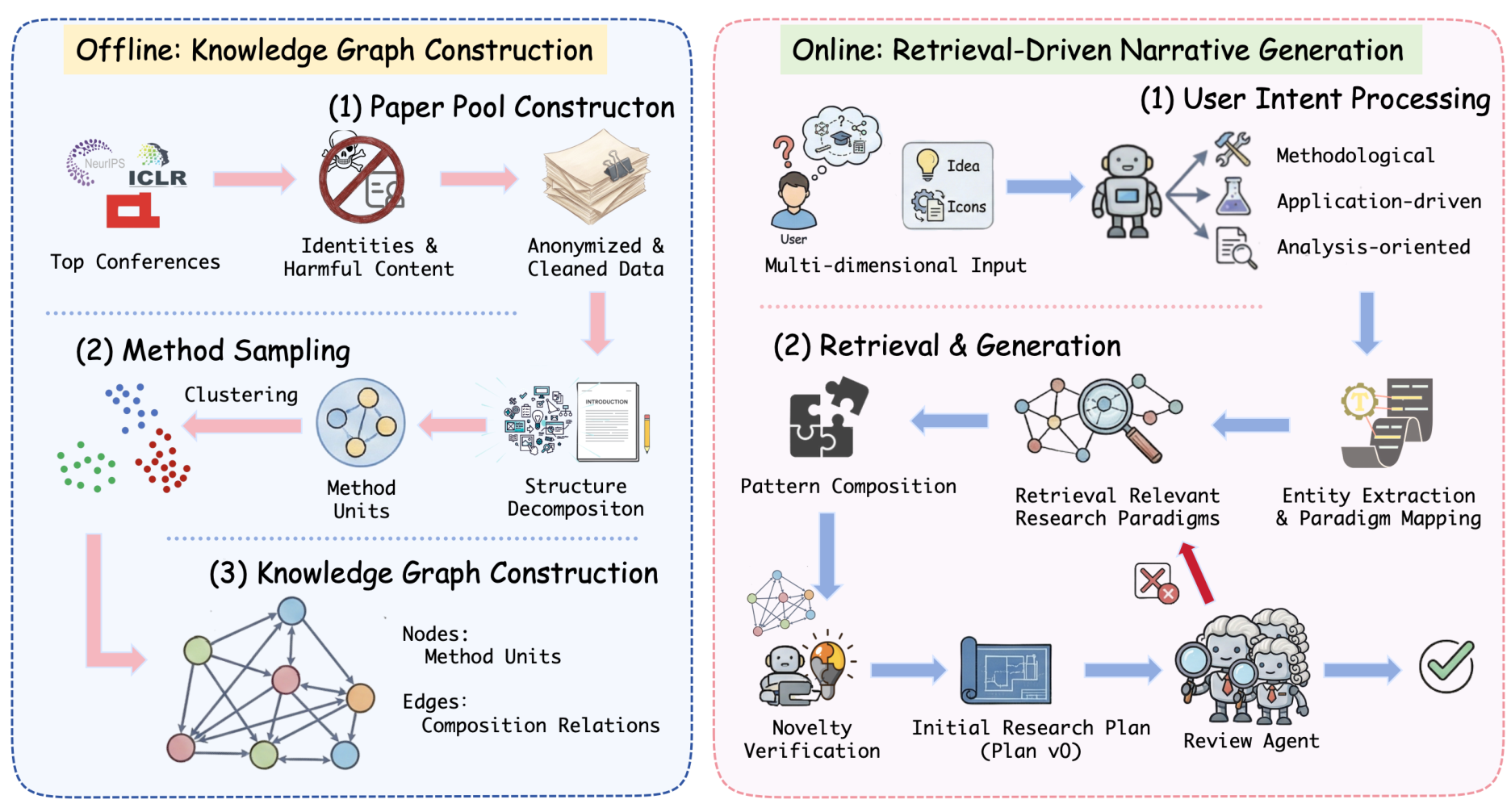 Idea2Story FrameworkOverview of the two-stage framework showing offline knowledge graph construction and online retrieval-driven narrative generation.
Idea2Story FrameworkOverview of the two-stage framework showing offline knowledge graph construction and online retrieval-driven narrative generation.
Online Stage: Retrieval and Refinement
When a user provides an underspecified research idea, Idea2Story performs multi-view retrieval across three levels: idea-level semantic similarity, domain-level matching, and paper-level pattern retrieval. These signals are aggregated to rank research patterns from the knowledge graph.
Retrieved patterns then undergo a review-guided refinement loop. Similar to the iterative refinement approach used in ResearchAgent [4], an LLM-based reviewer evaluates technical soundness, novelty, and problem-method alignment. Only revisions that improve reviewer scores are retained, producing methodologically grounded research patterns as output.
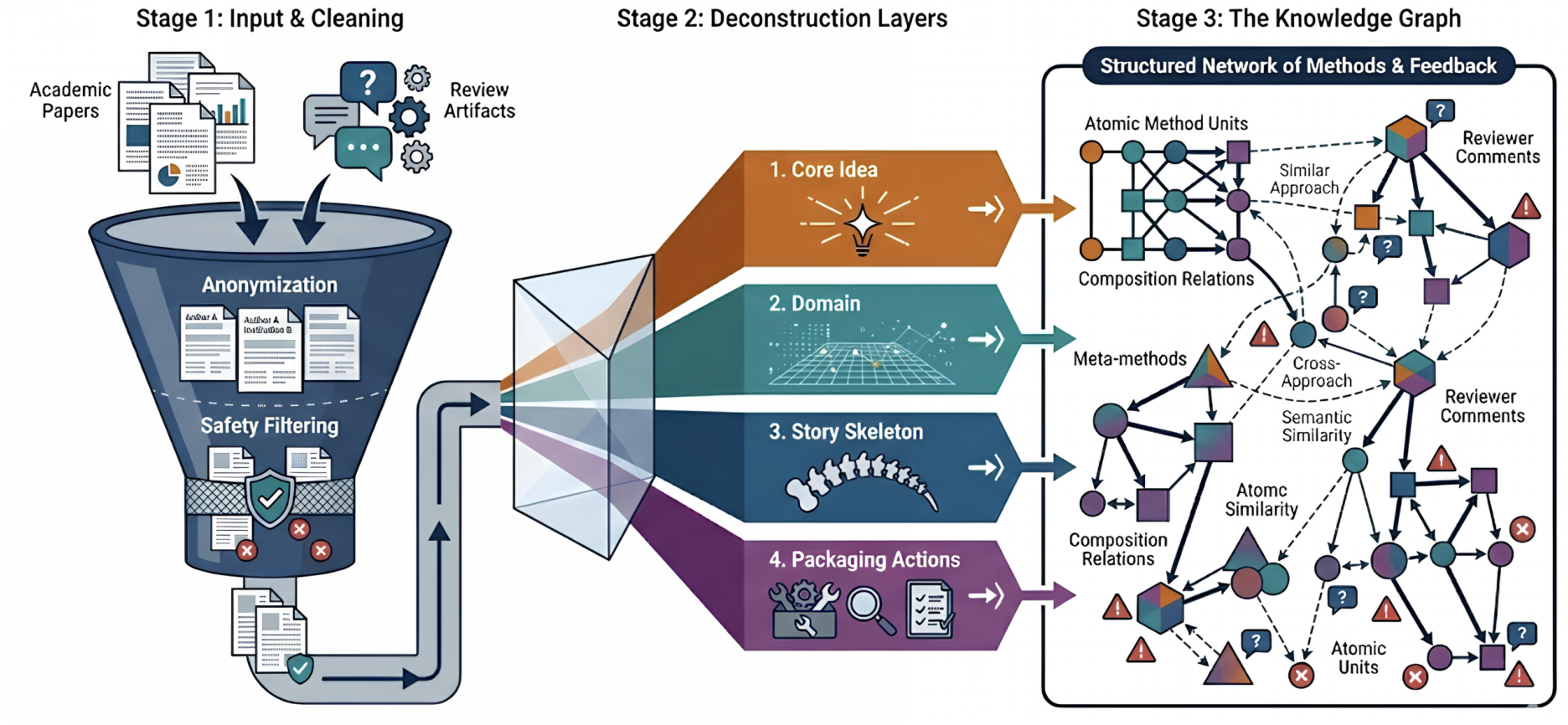 Knowledge Graph ConstructionThe offline pipeline showing anonymization, deconstruction layers, and the resulting knowledge graph structure with method units, meta-methods, and composition relations.
Knowledge Graph ConstructionThe offline pipeline showing anonymization, deconstruction layers, and the resulting knowledge graph structure with method units, meta-methods, and composition relations.
Evaluation Results
The evaluation primarily consists of qualitative comparison against a direct LLM generation baseline. Given the same underspecified user input ("I want to build an e-commerce agent that can better understand user intent"), both Idea2Story and a baseline GLM-4.7 model generated research patterns. An independent evaluator (Gemini 3 Pro) assessed the outputs.
Across all evaluated cases, Idea2Story outputs were consistently favored for novelty, methodological substance, and research quality. The system produced more specific methodological structures (diffusion-based classifiers, VQ-VAE tokenizers, graph embeddings) compared to the baseline's high-level abstractions (BERT encoder, lightweight GNN, LoRA).
Research Context
This work builds on the runtime-centric paradigm established by The AI Scientist [1] and its successor AI Scientist v2 [2], which introduced agentic tree search for research automation. It also relates to Agent Laboratory [3], which demonstrated hallucination issues in autonomous research evaluation, and Kosmos [5], which uses structured world models at runtime.
What's genuinely new:
- Pre-computation-driven paradigm that separates offline knowledge construction from online generation
- Method unit extraction decomposing papers into reusable abstractions (base problem, solution pattern, story, application)
- Knowledge graph encoding both canonicalized method units and empirically observed composition relations from accepted papers
- Multi-view retrieval combining idea-level, domain-level, and paper-level scoring for pattern ranking
Compared to AI Scientist v2 [2], which has demonstrated workshop-level paper acceptance, Idea2Story offers faster generation but is constrained to patterns present in its pre-built knowledge graph. For scenarios requiring the latest literature or truly novel approaches, runtime-centric systems remain more flexible.
Open questions:
- How does the system handle novel research directions that don't match existing patterns in the knowledge graph?
- What is the optimal frequency for updating the knowledge graph to balance recency with computational cost?
- Can method unit extraction generalize beyond ML conference papers to other scientific domains?
Key Takeaways
- Architectural shift: Idea2Story moves from runtime literature processing to offline knowledge pre-computation, potentially reducing the 15-hour runtimes seen in systems like The AI Scientist
- Structured methodology: The method unit extraction creates reusable abstractions that encode how problems are formulated and solved, not just what papers say
- Evaluation gap: While qualitative results favor Idea2Story, the paper lacks quantitative benchmarks for runtime efficiency and hallucination rates - the core motivating claims remain unvalidated
Limitations and Future Directions
The evaluation relies entirely on qualitative comparison of a small number of cases, with independent evaluation by Gemini 3 Pro potentially introducing its own biases. The knowledge graph is limited to NeurIPS and ICLR papers, which may not generalize to other research domains. Additionally, no ablation studies demonstrate the contribution of individual components.
The authors outline plans for integrating experiment-driven agents that can instantiate, validate, and iteratively refine research patterns through empirical feedback. Future work includes systematic translation of refined patterns into complete paper drafts.
Broader Implications
Idea2Story represents an alternative hypothesis in the autonomous research agent space: that methodological knowledge is stable enough to pre-compute, and that the efficiency gains outweigh the cost of potentially missing recent advances. Whether this tradeoff proves worthwhile remains to be seen - the paper lacks the quantitative benchmarks needed for definitive assessment.
For practitioners frustrated by the multi-hour runtimes and hallucination rates of current research agents, Idea2Story offers an intriguing alternative architecture. The pre-computation approach may prove particularly valuable for well-established domains where methodological patterns are relatively stable.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Lu, C. et al. (2024). The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv preprint. arXiv
[2] Yamada, Y. et al. (2025). The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search. arXiv preprint. arXiv
[3] Schmidgall, S. et al. (2025). Agent Laboratory: Using LLM Agents as Research Assistants. EMNLP 2025 Findings. arXiv
[4] Baek, J. et al. (2025). ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models. NAACL 2025. arXiv
[5] Mitchener, L. et al. (2025). Kosmos: An AI Scientist for Autonomous Discovery. arXiv preprint. arXiv


