16x Faster On-Device Video Generation: Qualcomm's ReHyAt Distills Attention in 160 GPU Hours
What if you could make video diffusion transformers run on a phone while generating infinitely long videos - and distill the capability from existing models in just 160 GPU hours?
Video generation has reached an inflection point. Models like Sora, Wan2.1 [2], and HunyuanVideo produce stunning short clips, but all hit the same wall: the self-attention mechanism in transformer architectures scales quadratically with sequence length. For video, where token counts can reach tens of thousands, this means generating anything beyond 10 seconds becomes impractical on standard GPUs and nearly impossible on mobile devices.
Researchers at Qualcomm AI Research have developed ReHyAt (Recurrent Hybrid Attention), a new attention mechanism that combines the quality of softmax attention with the efficiency of linear attention. Building on their prior work on Attention Surgery [4], the key innovation is a temporally chunked design that can be reformulated as an RNN, enabling constant memory usage regardless of video length. The entire distillation and fine-tuning pipeline requires just 160 GPU hours, two orders of magnitude less than concurrent approaches like SANA-Video [3], which requires approximately 18,000 GPU hours (12 days on 64 H100s).
The Quadratic Attention Problem
Modern video diffusion transformers process video as sequences of spatiotemporal patches. The standard softmax attention mechanism computes pairwise similarities between all tokens, resulting in O(N^2) complexity in both time and memory. For a 5-second video at 480x832 resolution, this translates to a latent size of 21x30x52 tokens per diffusion step.
While optimizations like FlashAttention [5] reduce constants and improve hardware utilization, they do not change the fundamental quadratic scaling. As video length or resolution increases, memory requirements explode. On mobile devices, generating even a few seconds of video pushes the limits of available memory.
Linear attention offers O(N) complexity by replacing the exponential kernel with feature map approximations [1]. However, this substitution introduces an expressiveness gap that typically requires extensive retraining and often results in degraded quality.
How ReHyAt Works
ReHyAt solves this dilemma through a hybrid approach. The video latent is divided into temporal chunks of Tc frames (the best configuration uses Tc=3 with overlap To=1). Within each chunk, tokens attend to each other using full softmax attention for high-fidelity local dependencies. For tokens in previous chunks, the model uses linear attention with learnable polynomial feature maps.
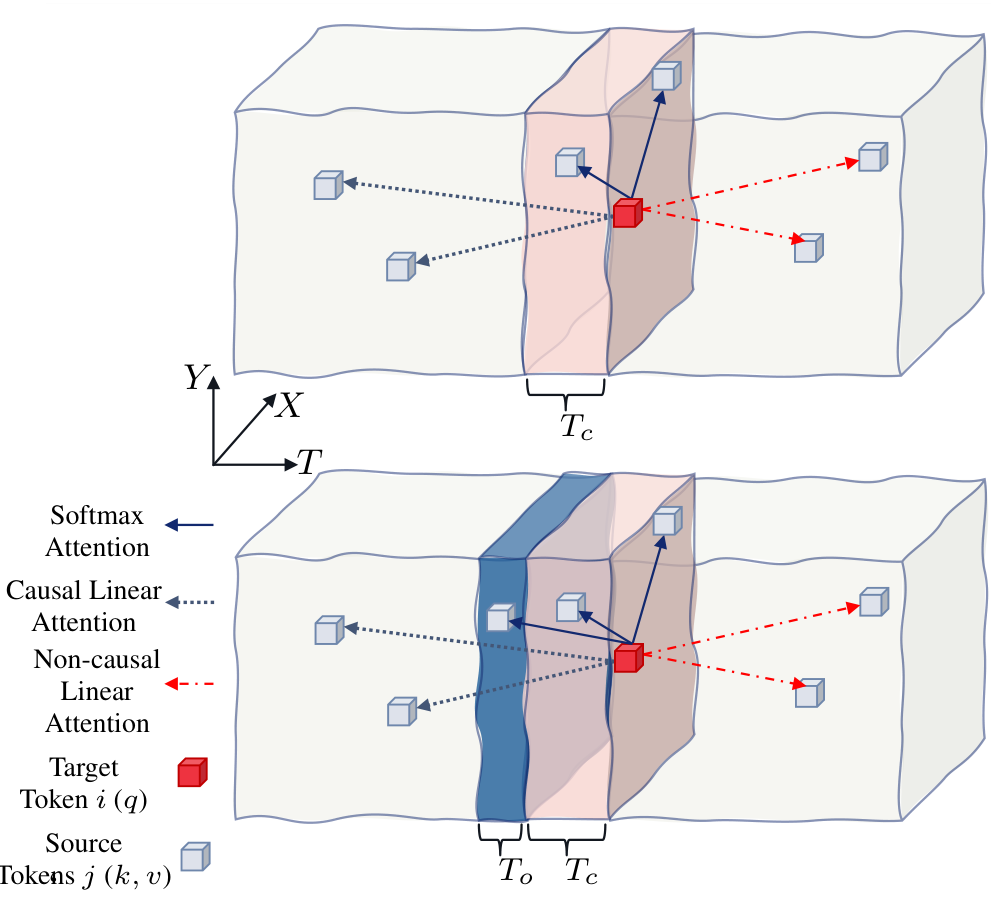 Hybrid Attention ArchitectureThe temporally chunked hybrid attention arrangement showing how softmax attention handles local dependencies within chunks while linear attention efficiently captures global context from previous chunks.
Hybrid Attention ArchitectureThe temporally chunked hybrid attention arrangement showing how softmax attention handles local dependencies within chunks while linear attention efficiently captures global context from previous chunks.
The key insight is that local dependencies within adjacent frames are more critical for video quality than global dependencies across distant frames. By preserving softmax attention for the current chunk and using efficient linear attention for everything else, ReHyAt maintains quality while achieving linear complexity.
To prevent temporal artifacts at chunk boundaries, the researchers introduce overlapping chunks. The softmax attention window extends To frames into the previous chunk, enabling smoother message passing between chunks.
RNN Reformulation for Constant Memory
The real power of ReHyAt emerges from its RNN reformulation. Because the linear attention terms over previous chunks can be accumulated into state variables, the model can process video chunk-by-chunk with constant peak memory. The state variables for chunk t+1 simply add the current chunk's contributions to the running sum.
This means ReHyAt can generate arbitrarily long videos without running out of memory. On a Snapdragon 8 Gen 4 mobile processor, where FlashAttention runs out of memory beyond 121 frames (about 7.5 seconds), ReHyAt continues scaling linearly with no memory limit.
Two-Stage Training
Rather than training a hybrid attention model from scratch, ReHyAt leverages existing high-quality softmax models through a lightweight distillation pipeline:
Stage 1: Attention Distillation. Each transformer block is trained independently. Only the learnable feature maps (phi_q and phi_k) are optimized to match the teacher's attention outputs. This stage does not require video-text pairs, only prompts, noise samples, and denoising iterations.
Stage 2: Lightweight Fine-tuning. The full model is fine-tuned on a modest dataset (350K video clips for low resolution, 22K synthetic samples for high resolution) for 1,000 iterations using flow matching objectives.
The entire pipeline completes in approximately 160 H100 GPU hours.
Benchmark Results
The researchers applied ReHyAt to Wan2.1 1.3B [2] and evaluated on VBench [6], the standard benchmark for video generation with 16 evaluation dimensions.
 VBench ComparisonBenchmark results comparing ReHyAt against state-of-the-art video diffusion models, showing competitive performance with significantly reduced computational requirements.
VBench ComparisonBenchmark results comparing ReHyAt against state-of-the-art video diffusion models, showing competitive performance with significantly reduced computational requirements.
ReHyAt (15x blocks, Tc=3, To=1) achieves a VBench Total Score of 83.79, outperforming both the original Wan2.1 (83.31) and SANA-Video (83.71). The semantic understanding score is particularly strong at 80.70, compared to 75.65 for Wan2.1.
On-device performance is where ReHyAt truly shines. At 121 frames on Snapdragon 8 Gen 4, ReHyAt achieves 302ms latency per DiT block compared to 4,809ms for FlashAttention, a 16x speedup. Memory read/write is reduced from 76.3 GB to 7.1 GB, an 11x improvement.
A human preference study with 500 paired comparisons found no statistically significant difference between ReHyAt and original Wan2.1 (27.6% preferred ReHyAt, 43.5% no preference, 29.0% preferred Wan2.1).
Limitations
The authors acknowledge that a small fraction of videos, especially with the most efficient variants, still show some temporal incoherence. The VBench Quality score drops slightly from 85.23 to 84.57. The current validation is limited to Wan2.1 1.3B, and transfer to other architectures like HunyuanVideo or CogVideoX remains to be demonstrated.
Research Context
ReHyAt builds on the foundation of linear attention RNN reformulation [1] and the DiT architecture [7]. Unlike SANA-Video [3] which uses pure linear attention trained from scratch, ReHyAt's hybrid design enables practical distillation from existing pretrained models.
What's genuinely new:
- A non-uniform chunked hybrid attention that enables RNN reformulation (prior hybrid methods remained quadratic)
- Overlapping chunk mechanism for temporal coherence
- 100x training efficiency through distillation versus training from scratch
Compared to SANA-Video, ReHyAt achieves comparable quality with dramatically lower training cost. For scenarios requiring maximum quality regardless of compute, the original softmax models remain preferable. For mobile deployment or long video generation, ReHyAt offers a practical path forward.
Open questions:
- Can this distillation recipe transfer to other video diffusion architectures?
- What is the optimal chunk size for different video lengths and resolutions?
- How does performance scale on videos requiring strong long-range temporal dependencies?
Check out the Paper and Project Page. All credit goes to the researchers.
References
[1] Katharopoulos, A. et al. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML 2020. Paper
[2] Team Wan et al. (2025). Wan: Open and Advanced Large-Scale Video Generative Models. arXiv preprint. arXiv
[3] Chen, J. et al. (2025). SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer. arXiv preprint. arXiv
[4] Ghafoorian, M. et al. (2025). Attention Surgery: An Efficient Recipe to Linearize Your Video Diffusion Transformer. arXiv preprint. arXiv
[5] Dao, T. et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022. arXiv
[6] Huang, Z. et al. (2024). VBench: Comprehensive Benchmark Suite for Video Generative Models. CVPR 2024. GitHub
[7] Peebles, W. & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023. arXiv


