175% Faster Prefill with Better Accuracy: ConceptMoE's Adaptive Token Compression for MoE
What if you could make your MoE models 2x faster at inference with better performance?
Large language models process text uniformly at the token level, allocating equal computation to every position regardless of semantic importance. Yet not all tokens carry equal weight: while some represent pivotal concepts requiring deep reasoning, others are trivially predictable from context. Building on dynamic chunking approaches pioneered by H-Net [1] and byte-level transformers like BLT [2], researchers from ByteDance Seed have developed ConceptMoE, which fundamentally changes how MoE models allocate compute by merging semantically similar tokens into concept representations.
The results are striking: up to 175% prefill speedup and 117% decoding speedup at compression ratio R=2, while simultaneously improving benchmark performance by +0.9 to +6.4 points across language and vision-language tasks. Unlike prior approaches that lack precise parameter control or double model parameters for fair comparison [3], ConceptMoE leverages MoE architecture properties to isolate genuine architectural benefits.
The Problem: Uniform Compute for Non-Uniform Tokens
Traditional vocabulary expansion offers limited returns. Research shows that a 100x vocabulary expansion yields only 1.3x compression [4], making further scaling impractical due to training and inference costs. Alternative approaches like fixed-length token merging cannot adapt to varying information density, while byte-level transformers introduce confounding factors through input representation changes.
The key insight behind ConceptMoE is straightforward: consecutive tokens with high semantic similarity should merge into unified concept representations, while semantically distinct tokens maintain fine-grained granularity. This naturally performs implicit compute allocation, processing predictable token sequences efficiently while preserving detailed computation for complex tokens.
How ConceptMoE Works
ConceptMoE consists of five modules: encoder, chunk module, concept model, dechunk module, and decoder. All three main components (encoder, concept model, decoder) use stacked MoE layers.
The Chunk Module calculates cosine similarity between adjacent token embeddings after linear transformation. When similarity between a token and its predecessor is low (indicating a semantic shift), that token is marked as a chunk boundary. The boundary probability p_n is computed as:
p_n = (1 - cos_similarity) / 2
Tokens with p_n >= 0.5 become boundaries. An auxiliary loss inspired by MoE load balancing constrains the compression ratio to a target value R during training.
The Concept Model processes the compressed sequence of concepts. With fewer tokens to process, it can allocate more compute per concept while maintaining the same total FLOPs.
The Dechunk Module remaps concepts back to tokens using exponential moving average (EMA) on concept boundaries. This smoothing mechanism accelerates chunking convergence during training.
Joint Decoding ensures information in concepts is fully exploited. In the decoder's last 4 self-attention layers, additional QKV projectors incorporate concept information into the attention computation. Specifically, both the token embedding z_n and its associated concept c are projected through separate Q, K, and V matrices, then added together before computing attention. This allows each subsequent token to directly attend to the rich semantic information captured in the concept representation, not just the residual token-level signal.
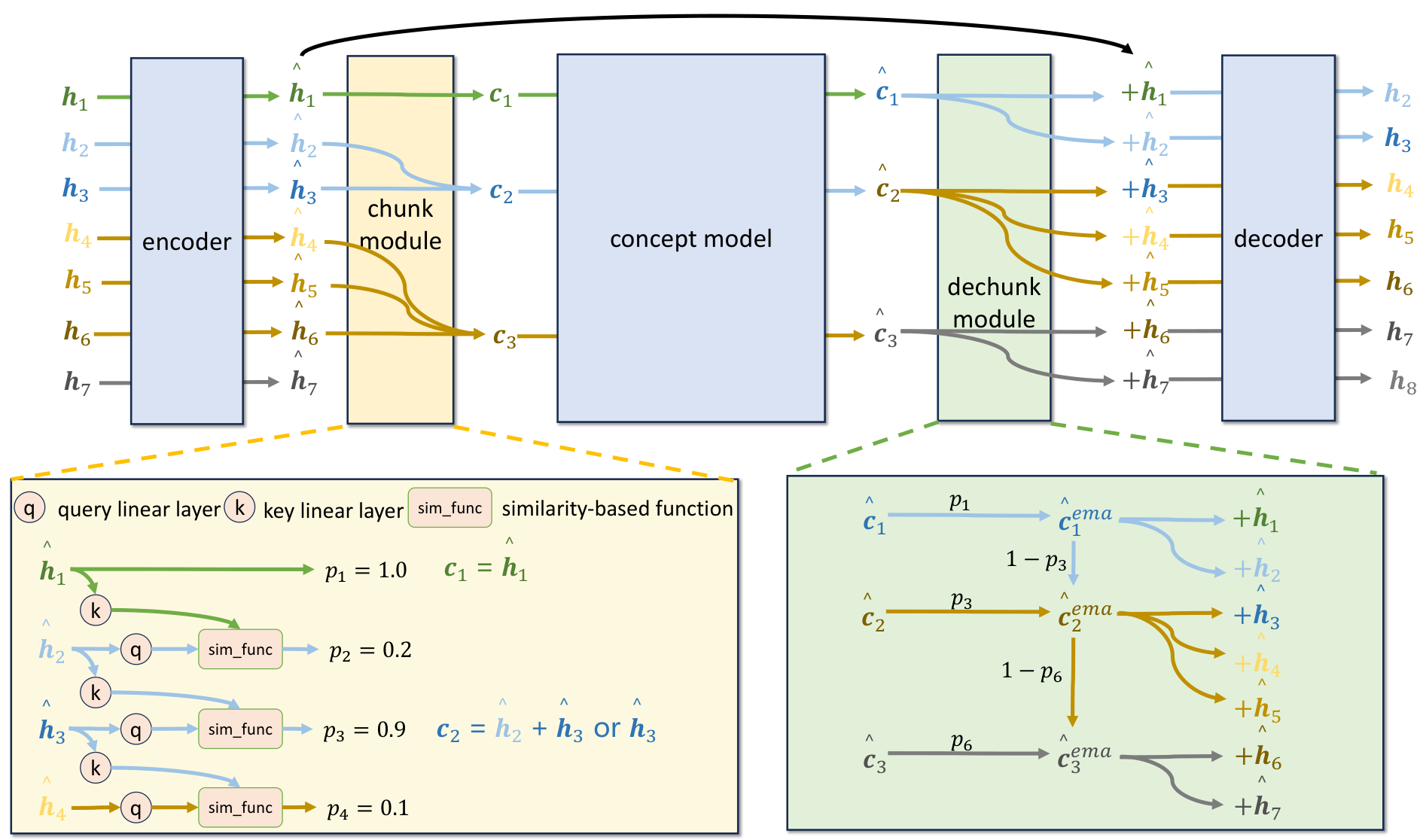 ConceptMoE ArchitectureOverview showing the complete pipeline: encoder, chunk module with similarity-based boundary detection, concept model, dechunk module with EMA smoothing, and decoder with joint decoding.
ConceptMoE ArchitectureOverview showing the complete pipeline: encoder, chunk module with similarity-based boundary detection, concept model, dechunk module with EMA smoothing, and decoder with joint decoding.
Fair Comparison Through Compute Reallocation
Unlike dense architectures, MoE allows adjusting activated parameters independently of total parameters. ConceptMoE exploits this property to enable rigorous comparison under identical total parameters and per-token FLOPs (excluding attention maps).
Three compute reallocation strategies are explored:
- Increasing C_moe: Activate more experts to compensate for token reduction
- Increasing L_C and C_moe: Add layer loops through intermediate layers (CT-friendly)
- Increasing C_attn and C_moe: Scale hidden size while reducing expert count
Even after compute matching, ConceptMoE provides inherent efficiency gains: attention map computation reduces by up to R^2x and KV cache by Rx.
Results: Performance and Speedup
ConceptMoE demonstrates consistent improvements across diverse training scenarios:
Language Pretraining (12B-24B parameters): +0.9 points over MoE baseline with identical FLOPs and parameters, achieving 50.9 vs 50.0 on Open Benchmark.
Vision-Language Training (60B parameters): +0.6 points on multimodal benchmarks and +2.3 points on long context understanding. The model adaptively compresses text less (using more compute) and images more, suggesting higher visual redundancy.
Continual Training Conversion (90B parameters): The basic ConceptMoE-top15 matches baseline performance, while ConceptMoE-top11-loop8 (with layer looping) achieves +5.5 points, reaching 46.4 vs 40.9. Training from scratch yields +6.4 points total. Math reasoning improves dramatically from 38.1 to 52.8 (+14.7 points).
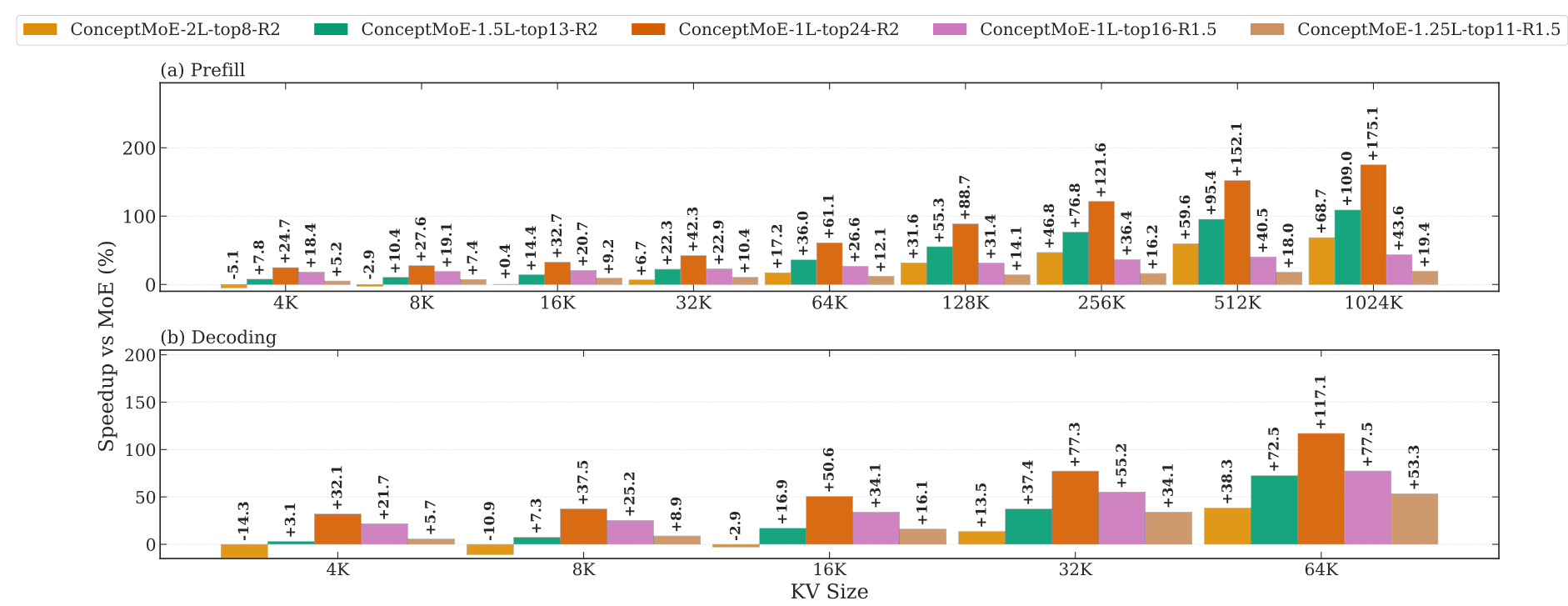 Inference SpeedupPrefill and decoding speedup percentages across sequence lengths from 4K to 1024K, showing five ConceptMoE configurations from efficiency-oriented to quality-oriented.
Inference SpeedupPrefill and decoding speedup percentages across sequence lengths from 4K to 1024K, showing five ConceptMoE configurations from efficiency-oriented to quality-oriented.
Inference Speedup: At R=2, efficiency-oriented configurations achieve prefill speedups up to 175% at 1024K context and decoding speedups up to 117% at 64K KV cache. Even quality-oriented configurations (doubling layers at R=2) maintain comparable speed to MoE on short sequences while gaining increasing advantages on long sequences.
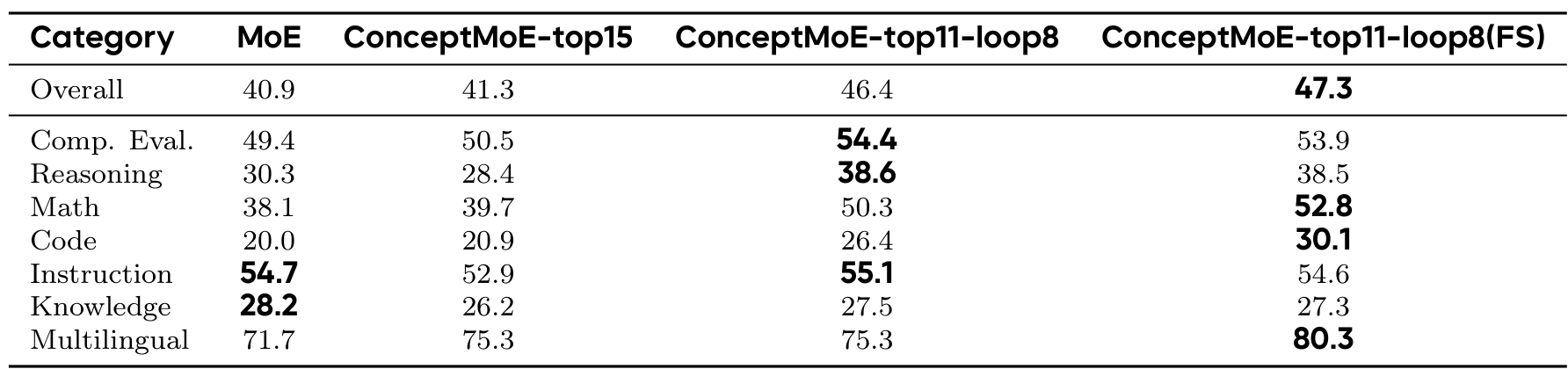 Benchmark ResultsPost-SFT performance comparison across categories showing gains in Reasoning (+8.3), Math (+12.2), and Code (+6.4) for the ConceptMoE-top11-loop8 configuration.
Benchmark ResultsPost-SFT performance comparison across categories showing gains in Reasoning (+8.3), Math (+12.2), and Code (+6.4) for the ConceptMoE-top11-loop8 configuration.
Practical Deployment: Converting Existing Models
A key practical advantage is CT conversion compatibility. Existing MoE checkpoints can be converted to ConceptMoE by adding:
- A chunk module (query and key linear layers, randomly initialized)
- A dechunk module
- Additional QKV projectors in the last 4 self-attention layers (zero-initialized)
The conversion is lossless: ConceptMoE-top15 matches MoE baseline performance while enabling inference speedup. With layer looping (ConceptMoE-top11-loop8), substantial gains emerge without retraining from scratch.
 CT ConversionIllustration showing MoE layers (blue) with added chunk module, dechunk module, and zero-initialized QKV projectors in the last 4 self-attention layers.
CT ConversionIllustration showing MoE layers (blue) with added chunk module, dechunk module, and zero-initialized QKV projectors in the last 4 self-attention layers.
Research Context
This work builds on H-Net's dynamic chunking module [1] and addresses limitations of BLT's non-end-to-end approach [2]. Unlike concurrent work DLCM [3] which doubles parameters when comparing against FLOPs-matched baselines, ConceptMoE maintains fair comparison by controlling both FLOPs and total parameters.
What's genuinely new:
- Learnable chunk module using cosine similarity for adaptive boundary detection
- Fair comparison methodology leveraging MoE architecture properties
- Three compute reallocation strategies maintaining controlled evaluation
- Joint decoding with additional QKV projectors for concept information
Compared to vocabulary expansion [4] which achieves only 1.3x compression with 100x vocabulary, ConceptMoE achieves R=2 compression dynamically. For scenarios requiring simpler deployment without MoE infrastructure, vocabulary expansion remains preferable.
Open questions:
- What is the optimal compression ratio for different content types (code vs prose)?
- Would 2D-aware chunking for vision tokens preserve spatial relationships?
- How does ConceptMoE interact with quantization or sparse attention techniques?
Limitations
The authors acknowledge that fine-grained visual tasks (localization, chart text extraction) show slight decline because treating image tokens sequentially disrupts spatial relationships. Excessive compression (R=4) degrades performance, particularly on reasoning and math tasks, suggesting each dataset has an optimal compression ratio determined by its semantic redundancy distribution.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Hwang, S. et al. (2025). Dynamic chunking for end-to-end hierarchical sequence modeling. arXiv preprint. arXiv
[2] Pagnoni, A. et al. (2024). Byte Latent Transformer: Patches scale better than tokens. arXiv preprint. arXiv
[3] Qu, X. et al. (2025). Dynamic Large Concept Models: Latent reasoning in an adaptive semantic space. arXiv preprint. arXiv
[4] Takase, S. et al. (2025). Large vocabulary size improves large language models. ACL Findings. Paper


