18x Faster Audiovisual Generation: Lightricks' Open-Source LTX-2 Rivals Veo 3
Video AI models have a problem: they're silent.
Text-to-video diffusion models have made remarkable progress, producing visually stunning clips with consistent motion and strong prompt adherence. Yet they share a fundamental limitation: they are silent. Without synchronized audio, these videos miss the semantic, emotional, and atmospheric cues that make content feel complete. Researchers from Lightricks have addressed this gap with LTX-2, an open-source foundation model that jointly generates high-quality video and synchronized audio from text prompts.
Building on their previous LTX-Video model [1], the team introduces an asymmetric dual-stream architecture that achieves state-of-the-art audiovisual quality among open-source systems while being approximately 18x faster than comparable models like Wan 2.2 [5]. Unlike proprietary alternatives such as Veo 3 [4] and Sora 2, LTX-2's weights and code are publicly available, enabling researchers and developers to experiment, fine-tune, and deploy without licensing constraints.
The Problem with Sequential Pipelines
Previous attempts at audiovisual generation relied on decoupled sequential pipelines: generating video first and then "filling in" audio, or vice versa. The authors argue that such approaches are inherently suboptimal because they fail to model the true joint distribution of both modalities. Consider lip synchronization, which is primarily driven by audio, alongside acoustic environment details like reverberation and foley, which are dictated by visual context. A unified model is required to capture these bidirectional dependencies.
The decoupled latent design also enables practical editing workflows. Users can generate synchronized audio for an existing video (V2A mode) or synthesize video driven by a specific audio track (A2V mode), providing flexibility for creative applications.
Asymmetric Dual-Stream Architecture
LTX-2 employs an asymmetric dual-stream Diffusion Transformer (DiT) with a 14B-parameter video stream and a 5B-parameter audio stream. This design recognizes that video and audio possess fundamentally different information densities: video requires more capacity for complex spatiotemporal dynamics, while audio processing can be more compact.
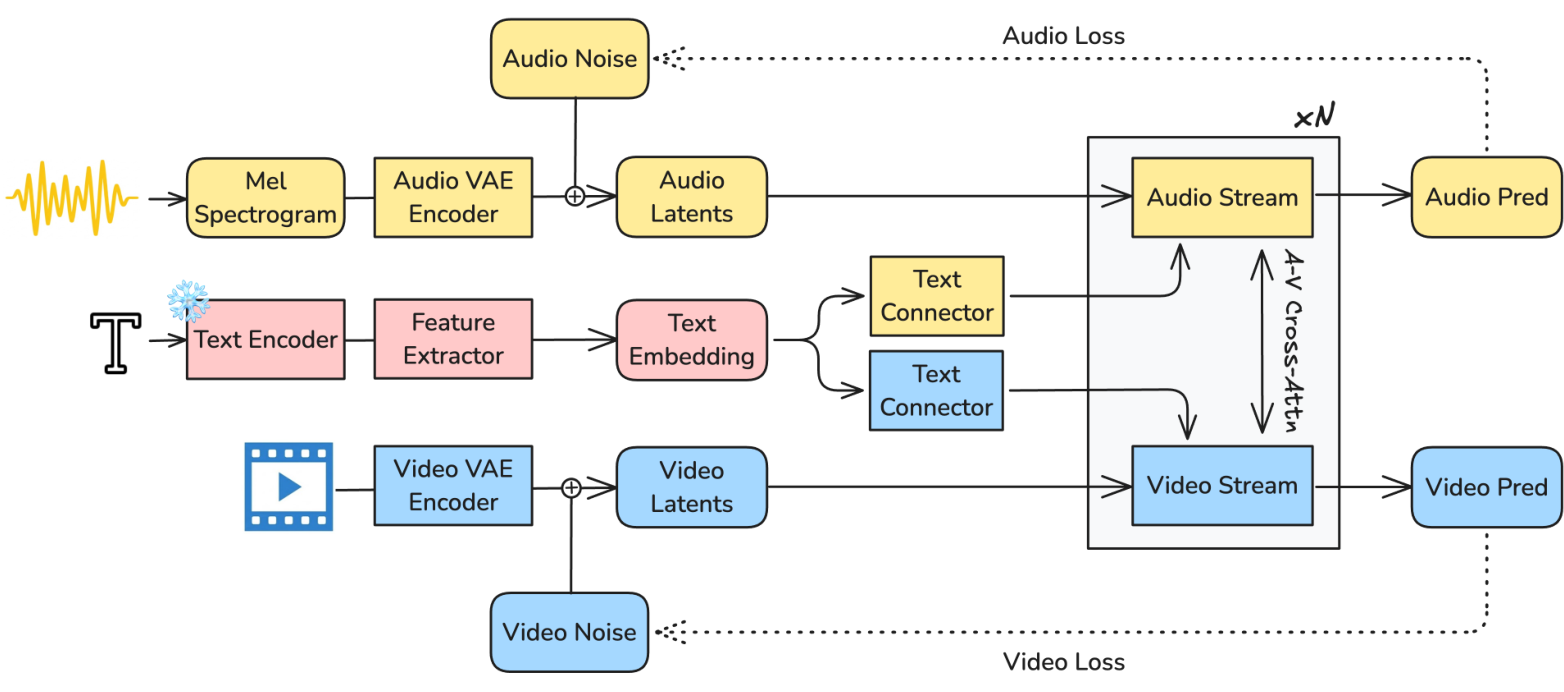 LTX-2 ArchitectureOverview of the LTX-2 architecture showing audio/video VAE encoders, text encoder with feature extractor, and dual-stream DiT with bidirectional cross-attention.
LTX-2 ArchitectureOverview of the LTX-2 architecture showing audio/video VAE encoders, text encoder with feature extractor, and dual-stream DiT with bidirectional cross-attention.
Both streams process latent representations from modality-specific causal VAEs. The video stream uses 3D Rotary Positional Embeddings (RoPE) for spatiotemporal dynamics, while the audio stream uses 1D temporal RoPE. At each layer, the dual-stream blocks perform four operations: self-attention within the modality, text cross-attention for prompt conditioning, bidirectional audio-visual cross-attention for inter-modal exchange, and feed-forward refinement.
The cross-modal attention uses temporal 1D RoPE during audio-video interactions, ensuring synchronization focuses on time alignment rather than spatial correspondence. Cross-modality AdaLN gates allow scaling and shift parameters for one modality to be conditioned on the other's hidden states, enabling tight synchronization even when diffusion timesteps or temporal resolutions differ.
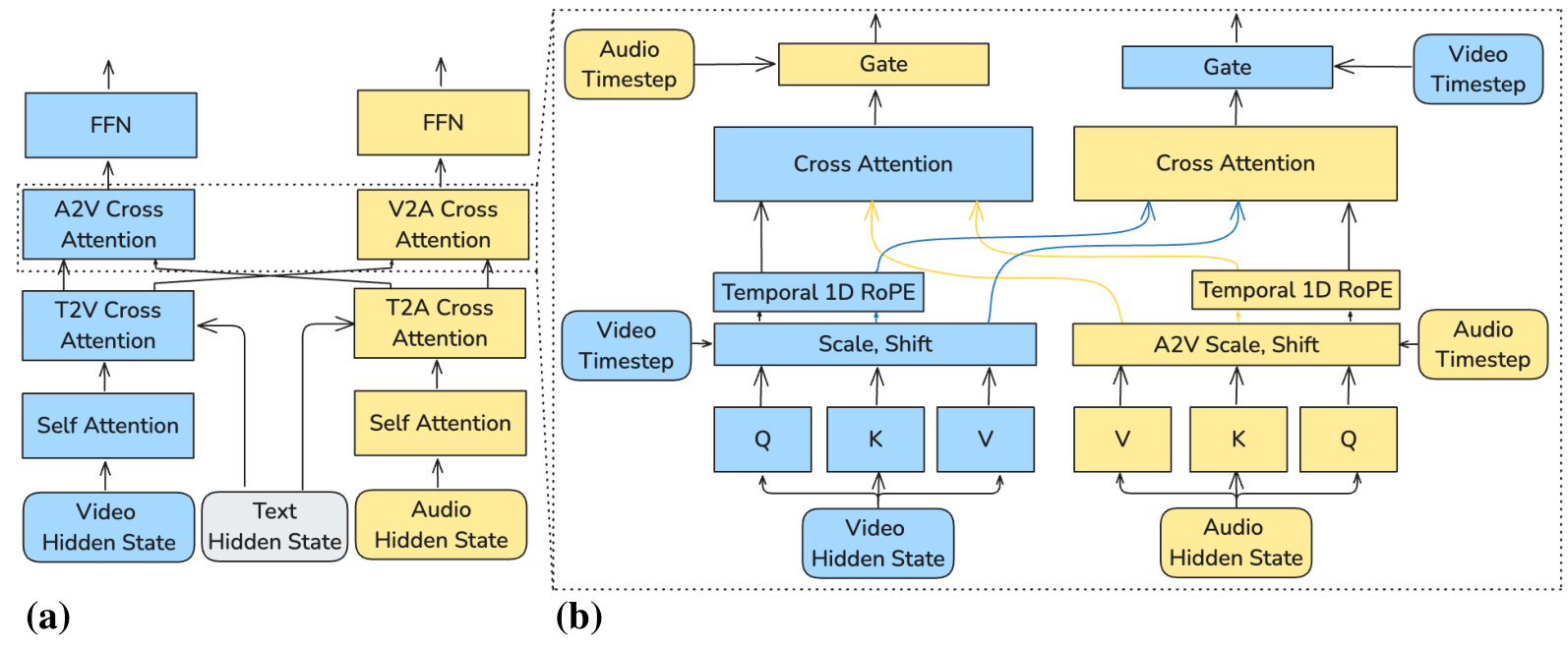 Dual-Stream ArchitectureThe dual-stream backbone processes video and audio latents in parallel with bidirectional cross-attention and AdaLN conditioning.
Dual-Stream ArchitectureThe dual-stream backbone processes video and audio latents in parallel with bidirectional cross-attention and AdaLN conditioning.
Deep Text Conditioning with Thinking Tokens
For high-quality speech generation, the team found that advanced text understanding is critical for both phonetic accuracy and semantic precision. LTX-2 uses Gemma3-12B [7] as its text encoder backbone with two specialized enhancements.
First, rather than relying solely on final-layer embeddings, a multi-layer feature extractor aggregates information across all decoder layers. This captures a hierarchy of linguistic meaning, from raw phonetics in early layers to complex semantics in later ones. Second, a text connector module introduces learnable "thinking tokens" that are processed through bidirectional transformer blocks alongside the original embeddings. These tokens serve as global information carriers, allowing the model to prepare aggregated contextual information before conditioning the diffusion process.
Modality-Aware Classifier-Free Guidance
Standard classifier-free guidance (CFG) [8] uses a single guidance scale for text conditioning. LTX-2 extends this with modality-aware CFG, introducing separate guidance terms for text (st) and cross-modal (sm) conditioning.
For each stream, the guided prediction combines the fully conditioned output with two guidance directions: a text guidance term and a cross-modal guidance term. The default guidance weights are st=3 and sm=3 for the video stream, and st=7 and sm=3 for the audio stream. This allows independent modulation of text and inter-modal influences during inference, with stronger cross-modal guidance promoting improved temporal synchronization and semantic coherence between generated video and audio.
Results and Efficiency
LTX-2 demonstrates significant advantages in both quality and speed. On inference benchmarks using an NVIDIA H100 GPU at 720p resolution with 121 frames, LTX-2 processes both audio and video in 1.22 seconds per diffusion step, compared to 22.30 seconds per step for Wan 2.2-14B [5] (which generates video only). This 18x speedup comes despite LTX-2 having 36% more parameters (19B vs 14B) due to its optimized latent space mechanism.
In human preference studies, LTX-2 significantly outperforms open-source alternatives like Ovi [3] and achieves scores comparable to proprietary models including Veo 3 [4] and Sora 2. On the Artificial Analysis public rankings (as of November 6th, 2025), LTX-2 was ranked 3rd in Image-to-Video and 4th in Text-to-Video generation. According to the authors, it surpassed proprietary systems including Sora 2 Pro and large-scale open models like Wan 2.2-14B on these rankings.
LTX-2 also supports longer generation than competitors, producing up to 20 seconds of continuous video with synchronized stereo audio. This exceeds Veo 3 (12s), Sora 2 (16s), Ovi (10s), and Wan 2.5 (10s).
 Cross-Attention VisualizationVisualization of audio-visual cross-attention maps showing the model's ability to track moving objects, shift attention between speakers, and focus on lip regions during speech.
Cross-Attention VisualizationVisualization of audio-visual cross-attention maps showing the model's ability to track moving objects, shift attention between speakers, and focus on lip regions during speech.
Audio Representation
The audio pipeline converts input waveforms to stereo audio at 16 kHz, computing mel-spectrograms that are encoded by a causal audio VAE. Each latent token corresponds to approximately 1/25 seconds of audio with a 128-dimensional feature vector. For reconstruction, a HiFi-GAN-based vocoder [6] jointly synthesizes a two-channel waveform at 24 kHz from the decoded mel-spectrograms, providing higher output quality than the latent processing rate.
Research Context
This work builds on LTX-Video [1], which established efficient spatiotemporal latent diffusion for video, and the Diffusion Transformer architecture [2] that replaced U-Net backbones with transformers for superior scalability.
What's genuinely new: The asymmetric dual-stream design (14B video + 5B audio) is novel for audiovisual generation, as prior work like Ovi [3] uses symmetric streams. The cross-modality AdaLN gating mechanism, where one modality's hidden states condition the other's normalization parameters, enables tighter synchronization. The thinking tokens approach for text conditioning improves phonetic accuracy in speech synthesis.
Compared to Veo 3 [4], the strongest proprietary competitor, LTX-2 achieves comparable human preference scores while being fully open-source, 18x faster in inference, and supporting longer (20s vs 12s) generation. For scenarios requiring absolute highest quality regardless of cost or complex multi-speaker dialogue, proprietary alternatives may still have advantages.
Open questions:
- How does performance scale with longer generation (30s+)? At what point does temporal drift become unacceptable?
- Can the asymmetric ratio be dynamically adjusted based on content type (e.g., more audio capacity for music videos)?
- How does the model handle edge cases like lip sync for singing versus speaking?
Limitations
The authors acknowledge several limitations. Performance varies across languages, with prompts in underrepresented languages or dialects yielding less accurate speech synthesis. In multi-speaker scenarios, the model may inconsistently assign spoken content to characters. Generating coherent sequences longer than approximately 20 seconds can lead to temporal drift, degraded synchronization, or reduced scene diversity. Additionally, as a generative diffusion model without explicit reasoning capabilities, deeper narrative coherence and factual grounding depend on external LLMs used to produce the conditioning text.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] HaCohen, Y. et al. (2024). LTX-Video: Realtime Video Latent Diffusion. arXiv preprint. arXiv
[2] Peebles, W. & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023. arXiv
[3] Character.AI Research. (2025). Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation. arXiv preprint. arXiv
[4] Google DeepMind. (2025). Veo 3: A diffusion-based audio+video generation system. Technical Report. Paper
[5] Team Wan et al. (2025). WAN: Open and Advanced Large-Scale Video Generative Models. arXiv preprint. arXiv
[6] Kong, J. et al. (2020). HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. NeurIPS 2020. arXiv
[7] Gemma Team. (2025). Gemma 3 Technical Report. arXiv preprint. arXiv
[8] Ho, J. & Salimans, T. (2022). Classifier-Free Diffusion Guidance. arXiv preprint. arXiv


