260% Better at Catching Moving Objects: DynamicVLA Solves Robot Latency Problem
Current VLA models ace static manipulation but fail catastrophically when objects move.
Vision-Language-Action (VLA) models have demonstrated impressive capabilities in robotic manipulation—but only when objects stay still. When targets start moving, these systems fail catastrophically. The root cause isn't perception quality; it's the hidden latency between observation and action execution. Even 100 milliseconds of delay can cause a robot to miss fast-moving targets entirely.
Researchers from Nanyang Technological University have developed DynamicVLA, a framework specifically designed for dynamic object manipulation. Building on the compact architecture pioneered by SmolVLA [1], the team redesigned both the model and execution pipeline to address temporal misalignment—achieving 260% better success rates than existing approaches while running at 88 Hz on modest hardware.
The Temporal Misalignment Problem
Current VLA models were designed assuming objects remain stationary during inference. This creates two critical gaps that compound with object motion: the perception-execution gap (delay between capturing an image and executing the corresponding action) and inter-chunk waiting (pauses between action sequences while the next inference completes).
Unlike VLASH [3], which attempts to predict future states to compensate for latency, DynamicVLA takes a fundamentally different approach. Rather than forecasting where objects will be, the system discards outdated actions entirely and ensures that only temporally-aligned predictions reach the robot.
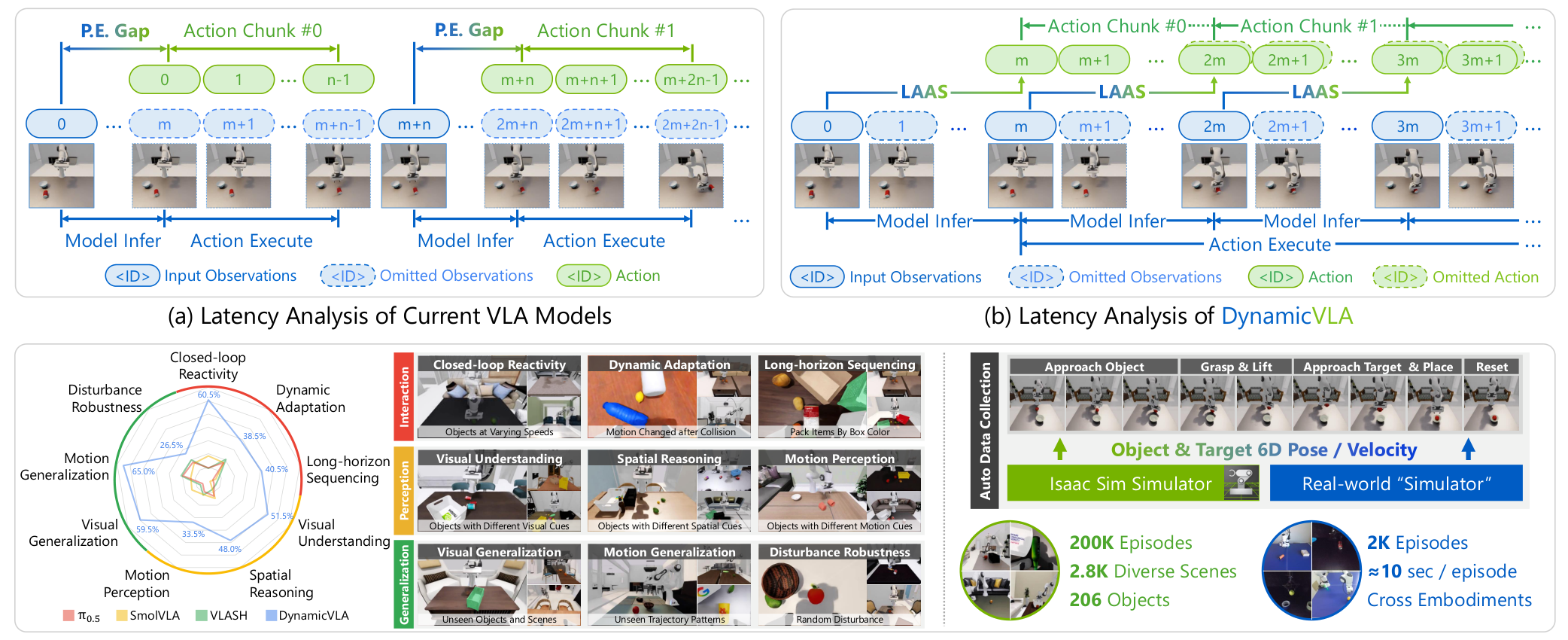 DynamicVLA OverviewThe framework addresses perception-execution gaps through Latent-Aware Action Streaming (LAAS) and Continuous Inference, enabling seamless action transitions for dynamic manipulation.
DynamicVLA OverviewThe framework addresses perception-execution gaps through Latent-Aware Action Streaming (LAAS) and Continuous Inference, enabling seamless action transitions for dynamic manipulation.
Architecture: Compact and Fast
DynamicVLA uses a 0.4B-parameter architecture combining three key components:
FastViT Vision Encoder: Instead of transformer-based vision encoding used in prior work [1, 7], DynamicVLA employs a convolutional encoder (FastViT [8]) that processes 384×384 images through hierarchical stages with channel widths 96→192→384→768→1536. This produces just 36 visual tokens—significantly fewer than transformer approaches—while preserving spatial structure critical for manipulation.
SmolLM2-360M Backbone: The language model backbone uses only the first 16 transformer layers of SmolLM2 [10], providing multimodal reasoning capabilities without the latency penalty of larger models. This design choice follows the truncation approach from SmolVLA [1] but optimizes for inference speed over language understanding.
Flow Matching Action Expert: A diffusion-based action head [4, 9] predicts action chunks—sequences of 20 timesteps of predicted robot actions—conditioned on the VLM features. This enables smooth, continuous motion rather than jerky discrete actions.
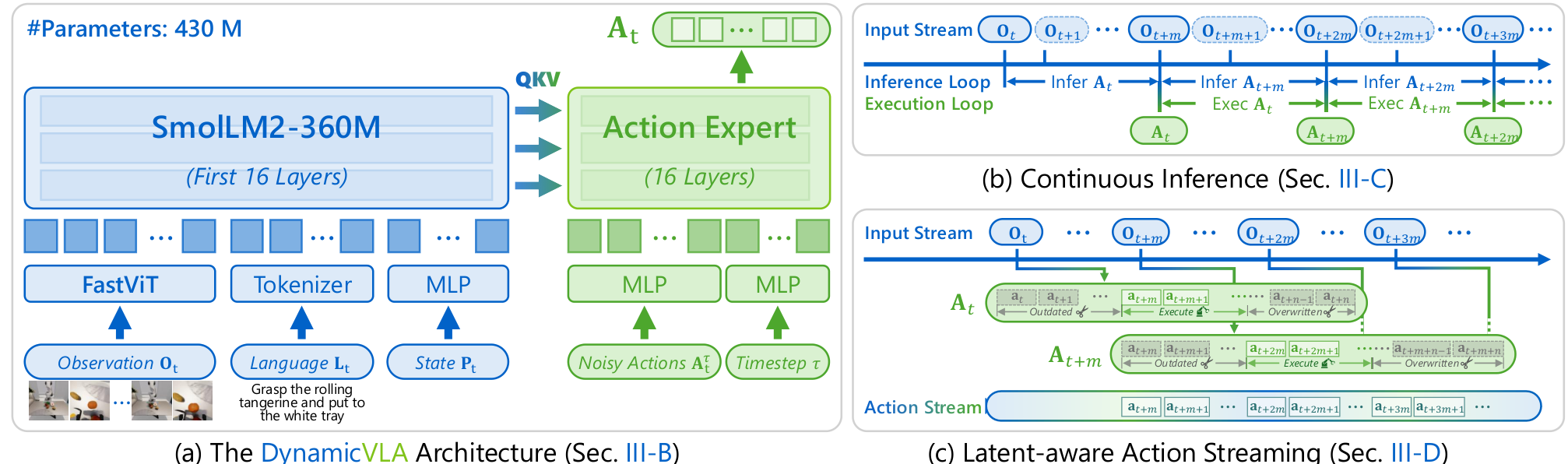 DynamicVLA ArchitectureThe 0.4B-parameter model combines FastViT vision encoder, SmolLM2-360M backbone, and a diffusion-based Action Expert for fast closed-loop control.
DynamicVLA ArchitectureThe 0.4B-parameter model combines FastViT vision encoder, SmolLM2-360M backbone, and a diffusion-based Action Expert for fast closed-loop control.
Solving Temporal Misalignment
Continuous Inference eliminates the traditional waiting period between action chunks. Standard VLA execution waits until one action sequence completes before starting the next inference cycle. DynamicVLA triggers new inference immediately after the previous cycle finishes—independent of action execution status. This overlapping pipeline dramatically reduces response latency.
Latent-aware Action Streaming (LAAS) addresses what happens when new observations arrive while old actions are still executing. Rather than blending outdated and current predictions, LAAS invalidates actions from timesteps before the inference completed and overwrites overlapping segments with predictions from the newest action chunk. This ensures the robot always acts on the most current world state.
The DOM Benchmark
To evaluate dynamic manipulation, the team created the Dynamic Object Manipulation (DOM) benchmark from scratch. The dataset includes 200,000 synthetic episodes across 2,800 scenes and 206 objects, plus 2,000 real-world episodes collected without teleoperation.
A critical insight: teleoperation is fundamentally ineffective for collecting dynamic manipulation data because fast-moving objects routinely exceed human reaction limits. The team developed an automated collection pipeline using 6D pose estimation from dual RGB cameras, creating a "real-world simulator" that enables programmatic data generation.
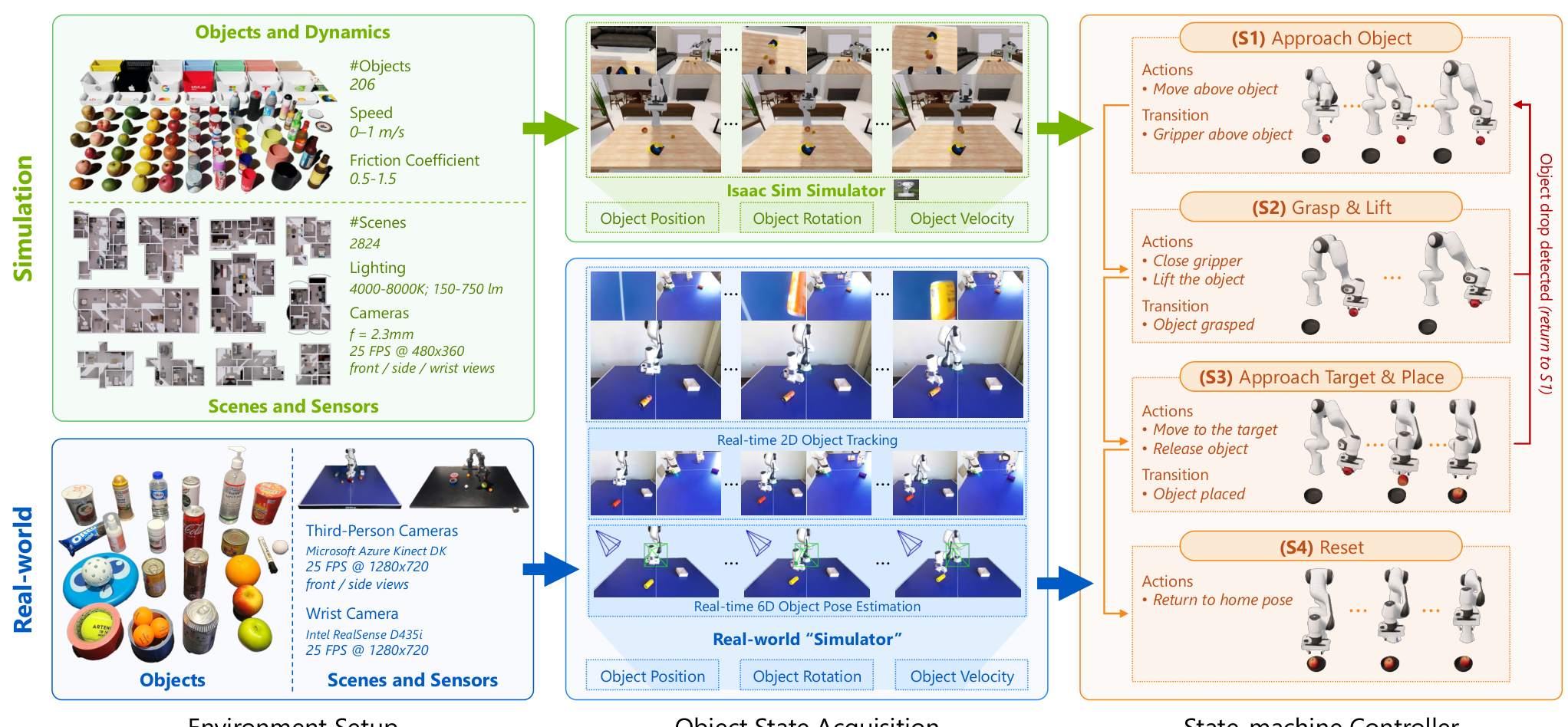 Data Collection PipelineThe automated pipeline enables efficient gathering of both simulation and real-world episodes without requiring human teleoperation.
Data Collection PipelineThe automated pipeline enables efficient gathering of both simulation and real-world episodes without requiring human teleoperation.
Results
Across nine evaluation dimensions spanning Interaction, Perception, and Generalization, DynamicVLA achieves 47.06% overall success rate compared to the best baseline (VLA-Adapter-Pro) at 13.61%—a 260% relative improvement evaluated over 1,800 trials.
The gains are particularly striking in specific capabilities:
- Long-horizon sequencing: 40.5% vs 7.5% (VLASH), a 440% improvement
- Visual understanding: 51.5% vs 9.5% (GR00T-N1.5 [6]), a 442% improvement
- Motion generalization: 65.0% vs 21.0% (VLASH), a 209% improvement
In real-world evaluation across Franka and PiPER robots, DynamicVLA achieves 50-78% success rates on interaction tasks compared to baselines' 10-33%, with visual generalization reaching up to 81.7% on specific tasks. The model runs at approximately 88 Hz on an NVIDIA RTX A6000 with just 1.8 GB GPU memory—making edge deployment feasible.
Ablation studies confirm each component's contribution: the 360M backbone is optimal (vs 135M or 1.7B), FastViT adds +18% over transformer encoders, Continuous Inference contributes +9.5%, and LAAS adds +5.8%. Combined, CI and LAAS boost performance from 30.27% to 47.06%.
Research Context
This work builds on SmolVLA's compact architecture [1] and π0's flow matching approach [2], but addresses a fundamentally different problem that prior VLAs ignored.
What's genuinely new:
- First VLA model specifically designed and benchmarked for dynamic object manipulation
- Latent-aware Action Streaming mechanism that discards outdated actions based on temporal alignment
- Automated data collection pipeline that bypasses teleoperation limitations entirely
Compared to VLASH [3] (the closest competitor addressing VLA latency), DynamicVLA achieves 47.06% vs 12.33% success rate. While VLASH predicts future states without architecture changes, DynamicVLA redesigns both model and execution pipeline. For scenarios requiring broad open-world generalization rather than dynamic manipulation, π0.5 [5] or SmolVLA [1] may be more appropriate.
Open questions:
- How does performance scale with faster object speeds?
- Can the approach extend to non-rigid or deformable dynamic objects?
- Can CI and LAAS benefits transfer to larger VLA models with improved efficiency?
Limitations
The real-time constraint fundamentally trades off multimodal understanding against responsiveness—larger models like π0.5 [5] show only marginal gains from CI and LAAS due to underlying inference latency. The current formulation emphasizes short- to medium-horizon reactive interaction; longer-horizon dynamic behaviors remain challenging. Additionally, the data pipeline assumes rigid-body state estimation; non-rigid or fluid dynamics are not addressed.
Check out the Paper, GitHub, and Dataset. All credit goes to the researchers.
References
[1] Shukor, M. et al. (2025). SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. arXiv preprint. arXiv
[2] Black, K. et al. (2024). π0: A Vision-Language-Action Flow Model for General Robot Control. RSS 2025. arXiv
[3] Tang, J. et al. (2025). VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference. arXiv preprint. arXiv
[4] Chi, C. et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. RSS 2023. arXiv
[5] Physical Intelligence. (2025). π0.5: A Vision-Language-Action Model with Open-World Generalization. CoRL 2025. arXiv
[6] Bjorck, J. et al. (2025). GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. arXiv preprint. arXiv
[7] Kim, M.J. et al. (2024). OpenVLA: An Open-Source Vision-Language-Action Model. arXiv preprint. arXiv
[8] Vasu, P.K.A. et al. (2023). FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization. ICCV 2023. arXiv
[9] Lipman, Y. et al. (2023). Flow Matching for Generative Modeling. ICLR 2023. arXiv
[10] Ben Allal, L. et al. (2025). SmolLM2: When Smol Goes Big - Data-Centric Training of a Small Language Model. arXiv preprint. arXiv


