2x Faster VLA Inference with 70% Fewer Layers: Shallow-π Distillation for Edge Robotics
A smaller, faster model can actually outperform its larger teacher when speed matters in real-world robotic manipulation.
Vision-Language-Action (VLA) models have emerged as the foundation for generalist robotics, enabling robots to understand visual scenes, follow natural language instructions, and execute precise manipulation actions. Building on the flow-based VLA architectures pioneered by π0 [1] and π0.5 [2], these models achieve impressive generalization across diverse tasks. However, their computational demands create a significant barrier to real-world deployment: running on edge devices like NVIDIA Jetson requires inference speeds that current 18-layer transformer models simply cannot achieve.
Researchers from Samsung Research South Korea have developed Shallow-π, a knowledge distillation framework that compresses flow-based VLA models from 18 to 6 transformer layers while maintaining near-teacher performance. Validated on the ALOHA bimanual platform and RB-Y1 humanoid robot, the key finding goes beyond efficiency: in dynamic manipulation tasks, the distilled model actually outperforms its teacher because faster inference enables better reaction times, achieving nearly 10Hz end-to-end inference on Jetson Orin.
The Edge Deployment Challenge
Flow-based VLAs like π0 and GR00T combine large vision-language model backbones with diffusion-based action heads, both containing dozens of transformer layers that must process inputs at every denoising step. Unlike layer-skipping methods such as EfficientVLA [3] and MoLE-VLA [5], which dynamically bypass layers at inference time, these approaches still require the full model to remain in GPU memory. Token compression methods like CogVLA reduce visual tokens but provide limited wall-clock speedup because modern GPUs parallelize token computation efficiently.
As shown in the figure below, reducing transformer depth yields substantially larger latency improvements than reducing visual tokens, especially on high-performance hardware. This effect is even more pronounced on edge devices like Jetson Orin, where the sequential nature of layer computation becomes the dominant bottleneck.
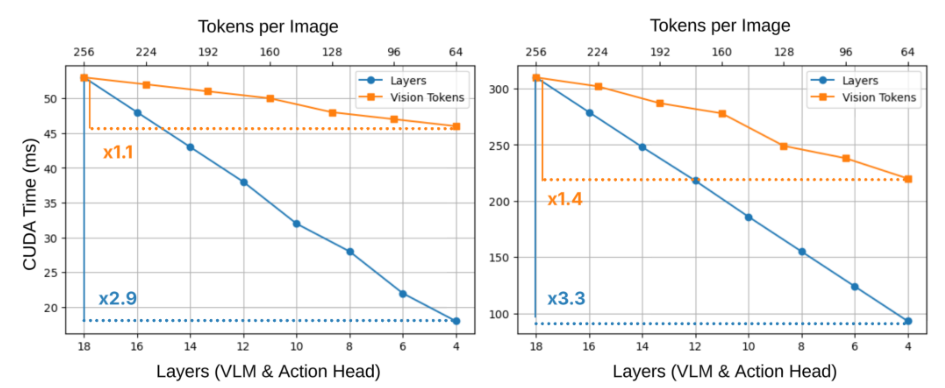 Latency AnalysisCUDA inference time as a function of transformer depth versus visual token count on H100 GPU and Jetson Orin, showing layer reduction provides much larger speedups.
Latency AnalysisCUDA inference time as a function of transformer depth versus visual token count on H100 GPU and Jetson Orin, showing layer reduction provides much larger speedups.
Why Layer Skipping Falls Short
Before developing Shallow-π, the researchers analyzed whether existing layer-skipping approaches could work for π-like architectures. The results revealed two critical limitations. First, feature similarity profiles vary substantially across denoising timesteps, making fixed skipping rules brittle. Second, similarity poorly predicts functional importance: despite higher similarity between layers 1 and 2 than between layers 16 and 17, skipping the former causes a much larger drop in success rate.
Using layer sensitivity as an oracle and progressively removing layers in order of lowest sensitivity, the success rate collapses once more than three layers are removed. This confirms that test-time layer skipping is fundamentally limited for flow-based VLAs where layer functionality is tightly coupled with denoising dynamics.
The Shallow-π Distillation Framework
Shallow-π takes a different approach: permanently reduce model depth through knowledge distillation rather than dynamic skipping. The student model is initialized by uniformly subsampling layers from the pretrained teacher, following TinyBERT-style initialization [6]. The key innovation lies in the combination of three complementary loss terms.
The task loss (L_task) follows standard flow matching, supervising the student to predict ground-truth velocity. The knowledge distillation loss (L_kd) encourages the student to match the teacher's predicted velocity at each denoising step. Most importantly, the attention distillation loss (L_attn) uses KL divergence to align cross-attention distributions between action queries and vision-language key-value pairs.
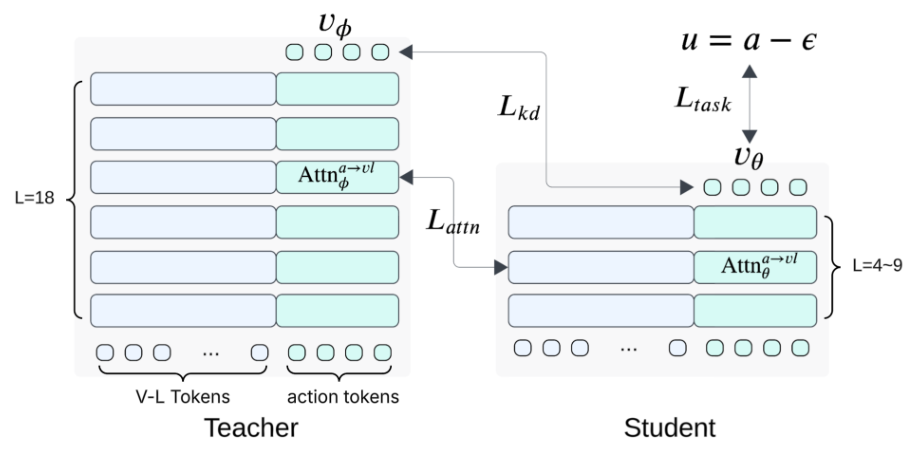 Distillation FrameworkShallow-π architecture showing teacher supervision via velocity matching and attention distribution alignment to the reduced student model.
Distillation FrameworkShallow-π architecture showing teacher supervision via velocity matching and attention distribution alignment to the reduced student model.
Critically, the attention distillation targets only action-to-vision-language cross-attention, not the full token attention matrix. Distilling attention over non-generated backbone tokens over-constrains the student and interferes with pretrained representations. The researchers found that matching attention across all tokens leads to unstable training and near-zero success rates.
Benchmark Results
On the LIBERO simulation benchmark, Shallow-π achieves success rates within 1% of the teacher while reducing both FLOPs and inference time by more than half. The 6-layer π0.5 model (π0.5-L6) achieves 95% average success compared to the teacher's 96%, while reducing FLOPs from 3.39T to 1.30T and CUDA inference time from 25.5ms to 11.3ms.
Compared to SmolVLA [4], which trains a small backbone from scratch, Shallow-π achieves 8 percentage points higher average success (95% vs 87%) while matching computational cost. This confirms that distilling high-capacity models is more effective than training small backbones from scratch.
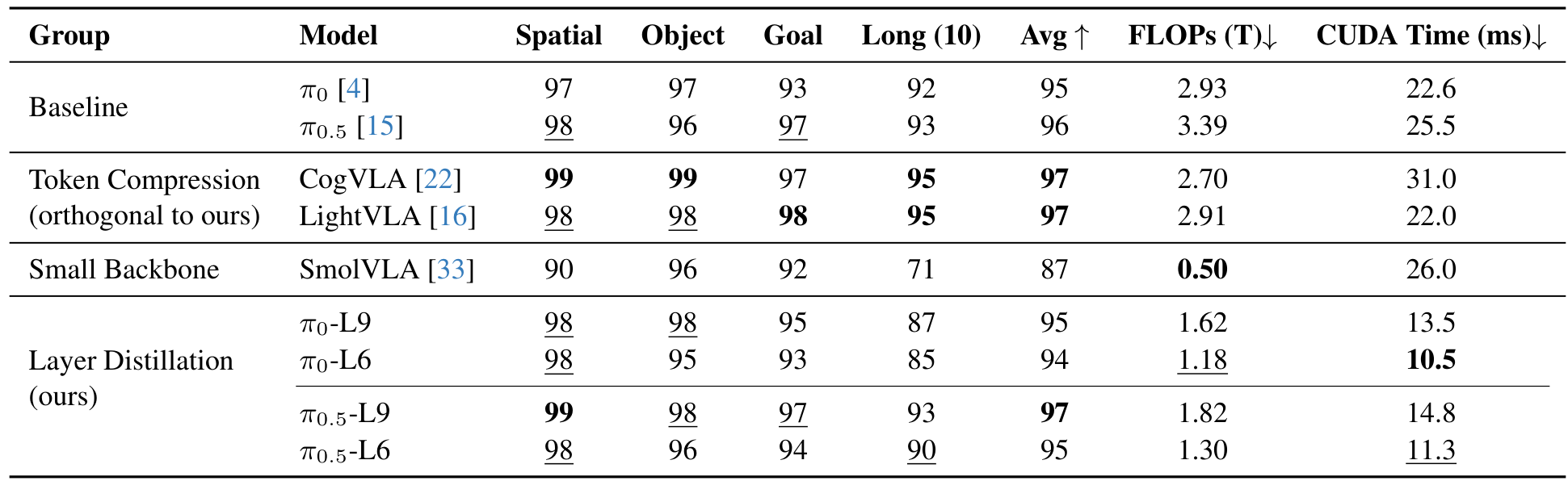 Main ResultsSuccess rates on LIBERO benchmark and computational metrics comparing baselines, token compression, small backbone, and layer distillation approaches.
Main ResultsSuccess rates on LIBERO benchmark and computational metrics comparing baselines, token compression, small backbone, and layer distillation approaches.
Real-World Validation: When Faster Means Better
The most striking results come from real-world experiments on dynamic manipulation tasks. On the ALOHA platform with objects moving on a rotating turntable (15 deg/s), Shallow-π0 outperforms both its teacher and SmolVLA across all four tasks: peg-in-hole (10/10 vs 7/10), insert foam (7/10 vs 5/10), scoop apple (9/10 vs 6/10), and pour beans (8/10 vs 5/10).
The reason? End-to-end computation time drops from 364ms (π0) to 110ms (Shallow-π0). The 254ms reduction corresponds to over 2cm of additional open-loop translation of the end-effector, which measurably degrades placement precision for the slower teacher model. Given the turntable's linear edge speed of approximately 0.8cm/s, slower inference directly translates to missed manipulation targets.
On the RB-Y1 humanoid platform running on Jetson Thor, Shallow-π0.5 similarly outperforms the teacher on the recycle task (17/20 vs 12/20) and the challenging open-lid-and-peg task (5/5 vs 1/5 on variant B). The distilled model's 78ms compute time versus 130ms for the teacher enables better reaction to dynamic scene changes.
 Experimental TasksTask suites for real-world evaluation including dynamic manipulation on ALOHA and humanoid coordination tasks on RB-Y1.
Experimental TasksTask suites for real-world evaluation including dynamic manipulation on ALOHA and humanoid coordination tasks on RB-Y1.
Research Context
This work builds on the π0 [1] and π0.5 [2] flow-based VLA architectures that inject vision-language features at every transformer layer. The distillation methodology draws from TinyBERT [6] for layer initialization and Align-KD for middle-layer attention transfer strategies.
What's genuinely new: Shallow-π is the first knowledge distillation framework that jointly compresses both the VLM backbone and action head in π-like architectures. The action-token-only attention distillation avoids interference with pretrained representations, and the comprehensive real-world validation on humanoid robots goes far beyond typical efficiency papers.
Compared to EfficientVLA [3], the strongest layer-skipping alternative, Shallow-π provides permanent model reduction (no full model in memory), works for both backbone and action head, and produces clean inference graphs suitable for edge deployment. For scenarios requiring quick deployment without retraining, layer-skipping methods remain appropriate.
Open questions: How does distillation interact with complementary efficiency techniques like token pruning and quantization? Can this approach transfer to non-π-like VLA architectures? What is the minimum viable teacher size for effective distillation?
Limitations
The authors acknowledge that knowledge distillation incurs higher training-time costs than layer-skipping approaches, as both teacher and student must be loaded simultaneously. The current validation is limited to specific robot platforms and tasks, and the approach is tailored to π-like architectures that inject features at every layer.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Black, K. et al. (2024). π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv preprint. arXiv
[2] Physical Intelligence et al. (2025). π0.5: A Vision-Language-Action Model with Open-World Generalization. arXiv preprint. arXiv
[3] Yang, Y. et al. (2025). EfficientVLA: Training-free Acceleration and Compression for Vision-Language-Action Models. arXiv preprint. arXiv
[4] Shukor, M. et al. (2025). SmolVLA: A Vision-Language-Action Model for Affordable Robotics. arXiv preprint. arXiv
[5] Zhang, R. et al. (2025). MoLE-VLA: Dynamic Layer-Skipping via Mixture-of-Layers. arXiv preprint. arXiv
[6] Jiao, X. et al. (2020). TinyBERT: Distilling BERT for Natural Language Understanding. EMNLP 2020. arXiv


