3.5x Faster Image Generation: DDiT Dynamically Resizes Patches in Diffusion Transformers
Not all denoising steps need the same resolution -- DDiT proves that dynamically adjusting patch sizes during inference can cut diffusion transformer inference time by over 3x without visible quality loss.
Diffusion Transformers (DiTs) have become the dominant architecture for high-quality image and video generation, powering models like FLUX [2] and Wan 2.1 [8]. But this quality comes at a steep cost: generating a single 5-second 720p video with Wan 2.1 takes 30 minutes on an RTX 4090. The core inefficiency lies in a deceptively simple design choice -- every denoising step processes the image at the same spatial resolution, regardless of whether the model is laying down coarse global structure or refining fine details. Researchers from Boston University and Amazon now challenge this assumption with DDiT, a method that dynamically adjusts patch sizes during inference to match each timestep's actual computational needs.
Unlike caching-based acceleration methods such as TeaCache [3] and TaylorSeer [4], which skip or predict features across timesteps, DDiT takes a fundamentally different approach: it changes the spatial granularity at which each step operates. The result is up to 3.52x speedup on FLUX-1.Dev and 3.2x on Wan 2.1, with minimal quality degradation.
The Core Insight: Variable Resolution Denoising
The standard DiT architecture [1] divides the latent representation into fixed-size patches that remain constant throughout all denoising steps. DDiT's key observation is that early denoising steps -- which establish broad scene composition -- can operate on much coarser patches without sacrificing quality, while later steps that refine textures and edges need finer resolution.
This is not merely a heuristic. The authors demonstrate that different prompts exhibit distinct computational profiles: generating "a simple red apple on a black background" requires far less spatial detail than "several zebras standing together behind a fence." DDiT adapts to both the timestep and the prompt complexity.
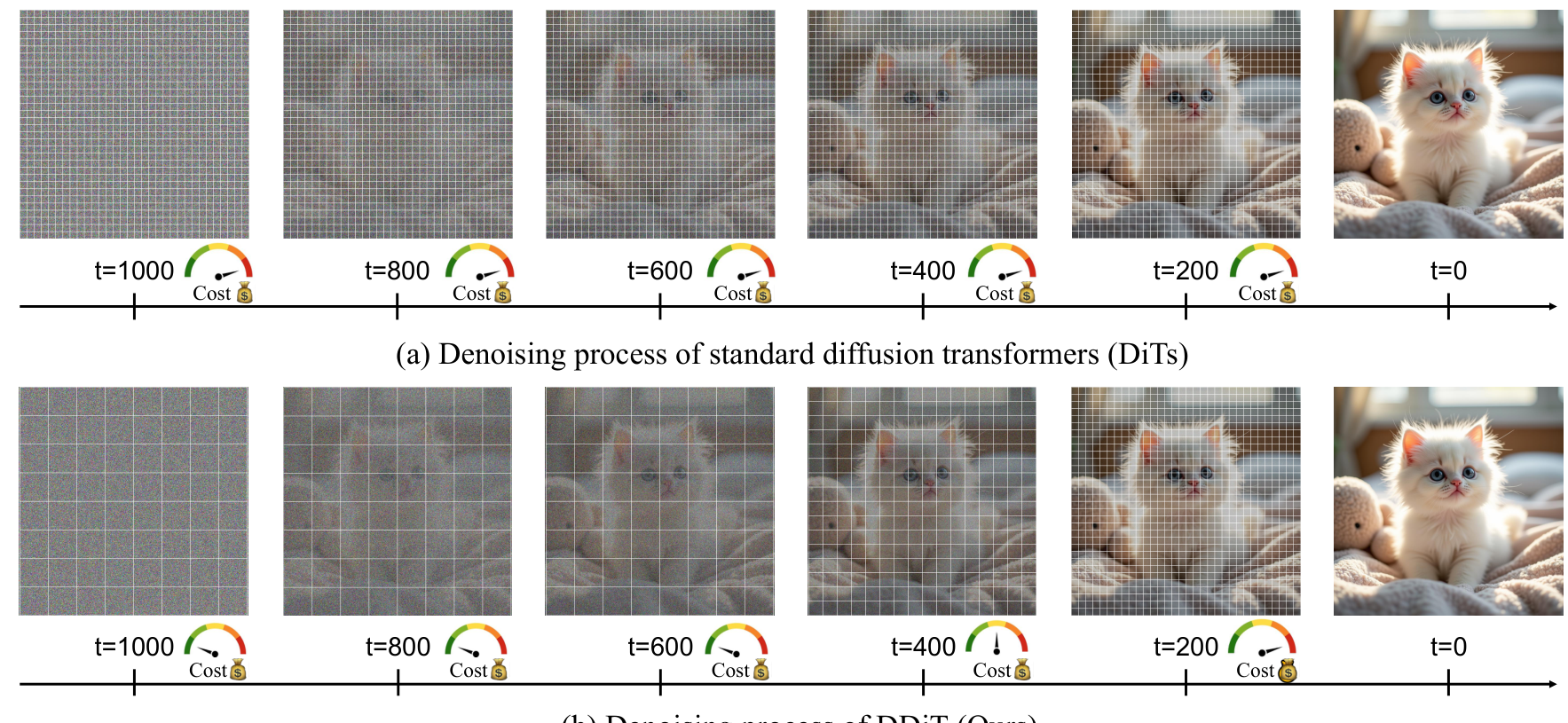 DDiT OverviewStandard DiTs use fixed patch sizes across all denoising timesteps, while DDiT dynamically adapts patch size per step based on latent complexity, reducing cost at coarse-structure timesteps.
DDiT OverviewStandard DiTs use fixed patch sizes across all denoising timesteps, while DDiT dynamically adapts patch size per step based on latent complexity, reducing cost at coarse-structure timesteps.
How DDiT Works
DDiT modifies a pre-trained DiT with minimal architectural changes to support multiple patch sizes (p, 2p, and 4p). Three components enable this:
Flexible patch embeddings. New patch embedding and de-embedding layers are introduced for each supported patch size. These are initialized using pseudo-inverse bilinear interpolation from FlexiViT [5], preserving the base model's functional behavior from the start.
LoRA adaptation. Rather than retraining the full model, DDiT adds lightweight LoRA branches [6] (rank 32) to the feed-forward layers of each transformer block. A residual connection from before patching to after de-patching helps bridge the base model's latent manifold with the new representations. The LoRA branch is fine-tuned using a distillation loss that aligns its noise predictions with the frozen base model. Notably, this fine-tuning uses synthetic data generated by the base model itself -- the T2I model trains on the T2I-2M dataset of base-model-generated images, while the T2V model uses synthetically generated videos -- keeping the training pipeline self-contained.
Dynamic patch scheduler. At inference time, the scheduler determines the optimal patch size at each timestep by measuring the rate of latent evolution. Specifically, it computes the third-order finite difference of the latent representations -- a measure of how quickly the denoising trajectory is "accelerating." When this acceleration is low (smooth evolution), coarser patches suffice; when it spikes (rapid detail generation), the scheduler falls back to finer patches.
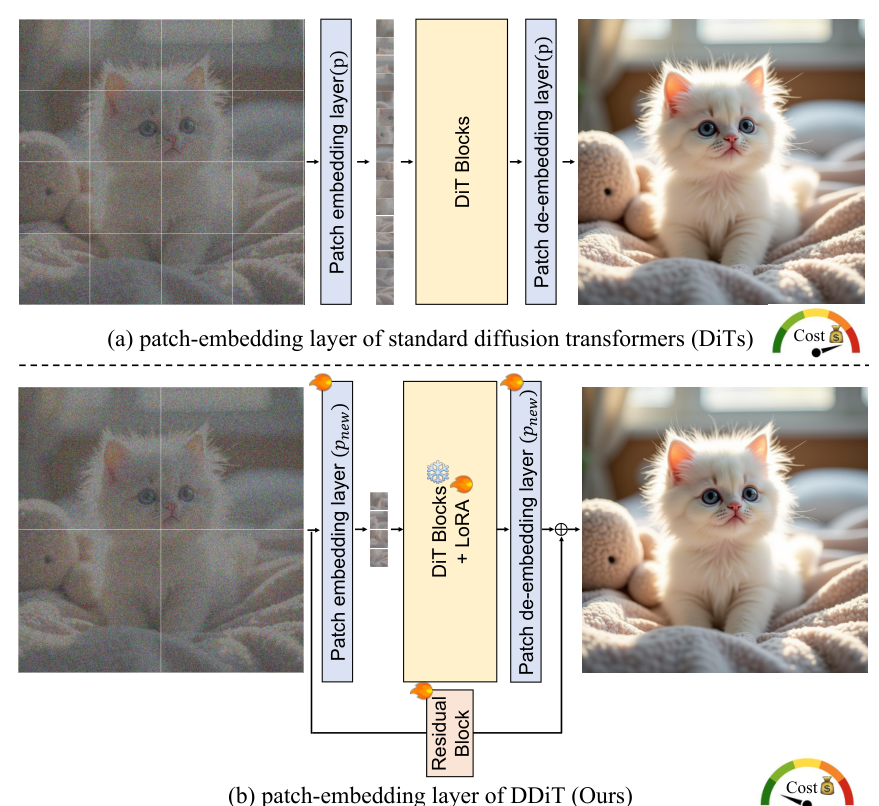 DDiT ArchitectureThe revised patch-embedding layer supports multiple resolutions through new embedding layers, LoRA branches in transformer blocks, and a residual connection.
DDiT ArchitectureThe revised patch-embedding layer supports multiple resolutions through new embedding layers, LoRA branches in transformer blocks, and a residual connection.
The spatial variance of this acceleration signal is aggregated using the rho-th percentile (rather than a simple mean) to capture heterogeneous detail regions -- ensuring that a highly textured area is not averaged away by a uniform background. A threshold parameter tau controls the speed-quality tradeoff: higher tau yields faster generation with slightly less detail fidelity.
Results
DDiT achieves substantial speedups while maintaining near-baseline quality across both image and video generation tasks.
On text-to-image with FLUX-1.Dev, DDiT alone achieves a 2.18x speedup (5.5 sec/image vs 12.0 sec baseline) with an FID of 33.42 compared to the baseline's 33.07 -- a difference of just 0.35. ImageReward scores remain nearly identical (1.0284 vs 1.0291). When combined with TeaCache [3], DDiT reaches 3.52x speedup (3.4 sec/image), outperforming both TeaCache and TaylorSeer [4] at similar speeds across FID, CLIP, and ImageReward metrics. Because coarser patches produce fewer tokens, timesteps using 2p or 4p patches also reduce peak memory consumption during attention computation -- a practical benefit for deployment on memory-constrained hardware.
On text-to-video with Wan 2.1 [8], DDiT achieves 2.1x speedup with a VBench score of 80.97 (vs 81.24 baseline), and 3.2x when stacked with TeaCache.
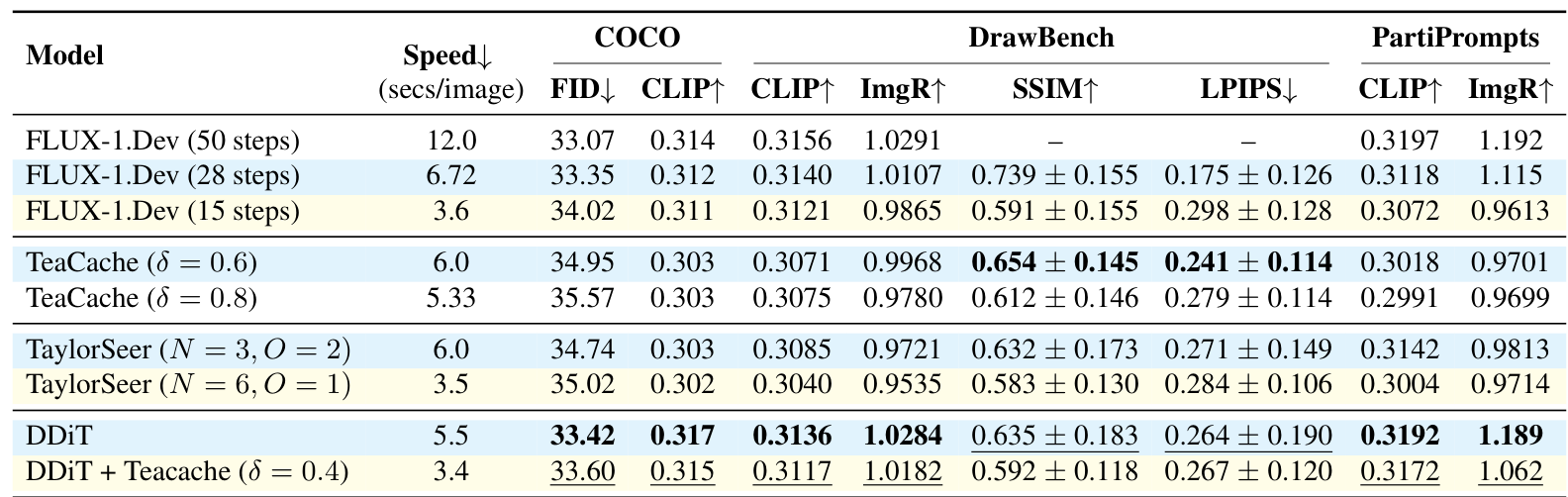 Benchmark ComparisonQuantitative comparison on COCO, DrawBench, and PartiPrompts shows DDiT outperforming TeaCache and TaylorSeer at similar inference speeds.
Benchmark ComparisonQuantitative comparison on COCO, DrawBench, and PartiPrompts shows DDiT outperforming TeaCache and TaylorSeer at similar inference speeds.
A user study further validates these results: human raters found DDiT generations visually as pleasing as the baseline 61% of the time, preferred DDiT 17% of the time, and preferred the baseline only 22% of the time.
Prompt-Adaptive Computation
One of DDiT's most compelling properties is content-aware resource allocation. The dynamic scheduler automatically adjusts computation based on prompt complexity. As shown in the figure below, complex scenes with fine-grained textures (zebras behind a fence) receive more fine-patch timesteps, while simpler scenes (a red apple on a black background) use primarily coarse patches, achieving greater speedup without quality loss.
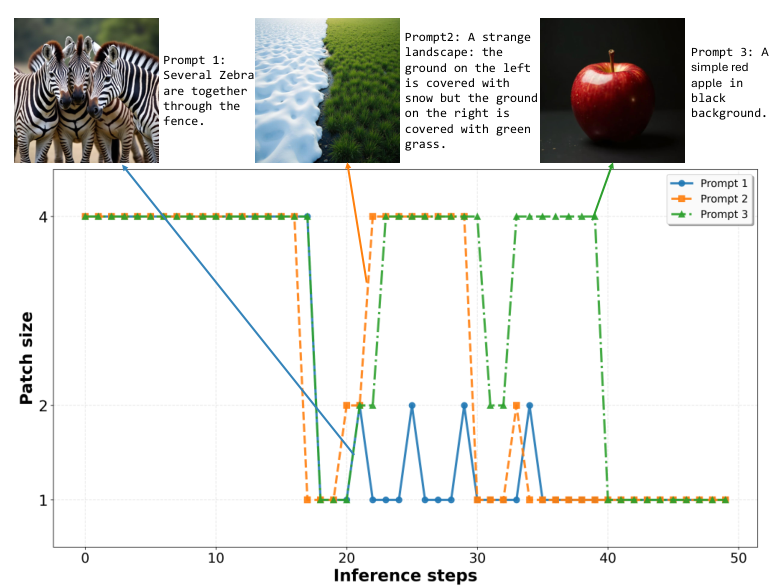 Patch SchedulesThree different prompts produce distinct patch schedules -- complex scenes allocate more fine-patch steps while simple scenes use predominantly coarse patches.
Patch SchedulesThree different prompts produce distinct patch schedules -- complex scenes allocate more fine-patch steps while simple scenes use predominantly coarse patches.
Research Context
DDiT builds on two key lines of prior work: the Diffusion Transformer architecture [1] and flexible patch sizing from FlexiViT [5]. While prior approaches to dynamic patches in DiTs either required training from scratch or used rigid manual schedules, DDiT is the first framework to dynamically adjust patch sizes at test time for pre-trained models [7].
What is genuinely new: the use of third-order finite differences to estimate latent manifold evolution as a scheduling signal, the percentile-based spatial variance aggregation for heterogeneous content, and the demonstration that patch-size adaptation is orthogonal to (and combinable with) caching methods.
Compared to TaylorSeer [4] -- the strongest competing method -- DDiT achieves better quality at comparable speeds (FID 33.42 vs 34.74, ImageReward 1.0284 vs 0.9721). TaylorSeer's advantage is being fully training-free, while DDiT requires a one-time LoRA fine-tuning step. For practitioners who need maximum speedup and can invest in fine-tuning, DDiT combined with caching offers the best available speed-quality tradeoff.
Open questions remain: whether DDiT can be made fully training-free, how it performs when stacked with orthogonal techniques like quantization, and whether learned scheduling policies could further improve the speed-quality curve.
Check out the Paper and Project Page. All credit goes to the researchers.
References
[1] Peebles, W. & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023. arXiv
[2] Black Forest Labs. (2024). FLUX. GitHub. GitHub
[3] Liu, F. et al. (2025). TeaCache: Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model. CVPR 2025. arXiv
[4] Liu, J. et al. (2025). TaylorSeer: From Reusing to Forecasting: Accelerating Diffusion Models with TaylorSeers. ICCV 2025. arXiv
[5] Beyer, L. et al. (2023). FlexiViT: One Model for All Patch Sizes. CVPR 2023. arXiv
[6] Hu, E. et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022. arXiv
[7] Zhao, W. et al. (2024). Dynamic Diffusion Transformer. arXiv. arXiv
[8] Team Wan. (2025). Wan: Open and Advanced Large-Scale Video Generative Models. arXiv. arXiv