Meta's LeCun Introduces SAI: A Measurable Alternative to AGI
Every major AI lab is racing toward AGI — but what if AGI is a fundamentally incoherent target?
Everyone from AI executives to policymakers is talking about Artificial General Intelligence, yet the term means something different to nearly every person who uses it. Building on the intelligence measurement frameworks proposed by Chollet [1] and the formal definitions from Legg and Hutter [4], researchers from Columbia University, Distyl, and NYU — including Turing Award winner Yann LeCun — argue that AGI is not merely ill-defined but structurally incoherent. Their proposed replacement, Superhuman Adaptable Intelligence (SAI), shifts the target from vague generality to measurable adaptation speed.
The paper arrives amid a visible public dispute between LeCun and DeepMind CEO Demis Hassabis over what AI should ultimately aim for, and at a moment when policymakers are increasingly drafting regulations around "AGI" thresholds that lack precise definitions. Unlike previous critiques that focus on individual definitions, this work systematically evaluates seven prominent AGI definitions and shows that every single one fails at least one of three basic criteria: feasibility, consistency, or assessability.
Why AGI Is the Wrong Target
The paper's central argument begins with a provocative claim: human intelligence is not general. Drawing on Moravec's Paradox — the observation that tasks trivial for humans (walking, recognizing faces) are hard for machines, while tasks hard for humans (chess, calculation) are easy for machines — the authors argue that evolution has shaped humans into specialized systems for survival-relevant tasks. As the paper puts it: "We feel general because we can't perceive our blind spots, not because we lack them."
This matters because most AGI definitions anchor themselves to human intelligence as the benchmark for generality. If human intelligence is itself specialized, then defining AGI as "matching human cognitive versatility" [2] or "outperforming humans at most economically valuable work" (OpenAI Charter) creates a circular reference: generality is defined in terms of a system that is not actually general.
The No Free Lunch theorem [6] provides the theoretical backstop. No single algorithm can outperform all others across every possible problem distribution, meaning true universality is not just impractical but mathematically infeasible. Evidence from multi-task learning reinforces this: negative transfer [9] shows that training on more tasks can actively harm performance on individual ones.
A Taxonomy of AGI Definitions
To move beyond ad hoc critiques, the authors construct a two-dimensional semantic map organizing seven major AGI definitions along two axes: capability source (learning/adaptability vs. performance) and task scope (universal vs. human-centric). The definitions cluster into three distinct camps: Adaptive Generalists emphasizing learning efficiency, Cognitive Mirrors focused on replicating human cognition, and Economic Engines prioritizing practical utility.
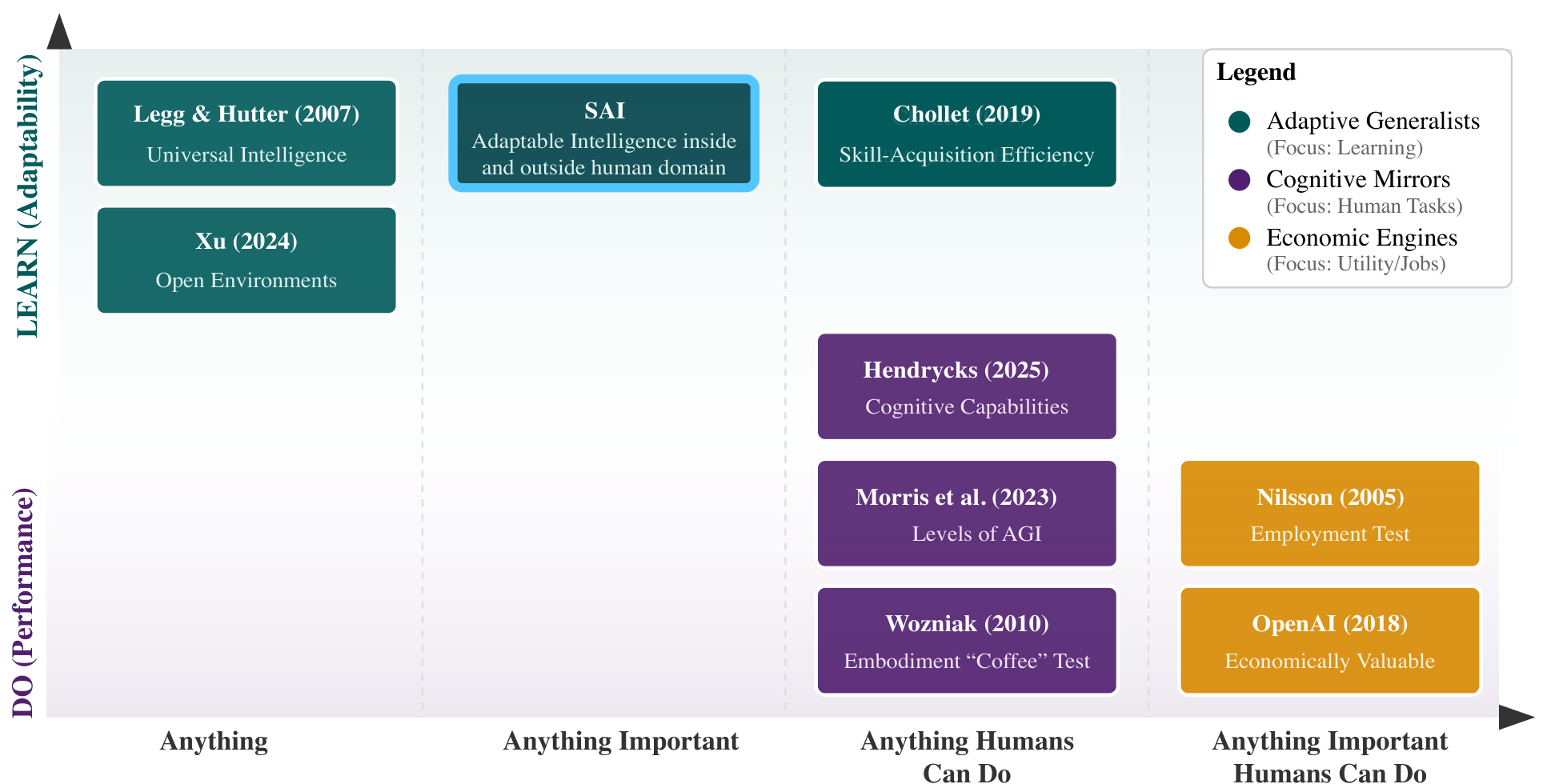 AGI TaxonomyA two-dimensional semantic map organizing prominent AGI definitions along axes of capability source and task scope, revealing three clusters: Adaptive Generalists, Cognitive Mirrors, and Economic Engines.
AGI TaxonomyA two-dimensional semantic map organizing prominent AGI definitions along axes of capability source and task scope, revealing three clusters: Adaptive Generalists, Cognitive Mirrors, and Economic Engines.
Each definition is then evaluated against three criteria. Feasibility asks whether the definition describes something theoretically achievable. Consistency checks whether the definition's claims match reality. Assessability tests whether progress can be measured. The results are striking: of the seven definitions surveyed, 4 are classified as Not Consistent, 2 as Not Feasible, and 1 as Not Assessable. Specifically, definitions from Morris et al. [3] and Legg and Hutter [4] that claim broad generality fail feasibility under No Free Lunch constraints. Human-centric definitions — including those from Hendrycks et al. [2], Morris et al. [3], Hassabis/DeepMind, and Chollet [1] — fail consistency because they circularly define generality in terms of non-general human cognition. OpenAI's performance-focused definition fails assessability because it requires benchmarking against an ever-expanding and ill-defined set of tasks.
Introducing SAI: Adaptation Speed as the North Star
SAI is defined as intelligence that can learn to exceed humans at any important task while also adapting to tasks outside the human domain that have utility. The critical distinction from AGI is the replacement of generality with adaptability. As the authors memorably argue: "The AI that folds our proteins should not be the AI that folds our laundry!"
The proposed metric is adaptation speed — how quickly a system can acquire competence at a new task. This draws directly from the meta-learning tradition established by MAML [7], which demonstrated that learning-to-learn efficiency is both measurable and optimizable. Unlike Chollet's skill-acquisition efficiency metric [1], which anchors evaluation to human intelligence benchmarks, SAI's adaptation speed is defined without reference to human performance as the ceiling.
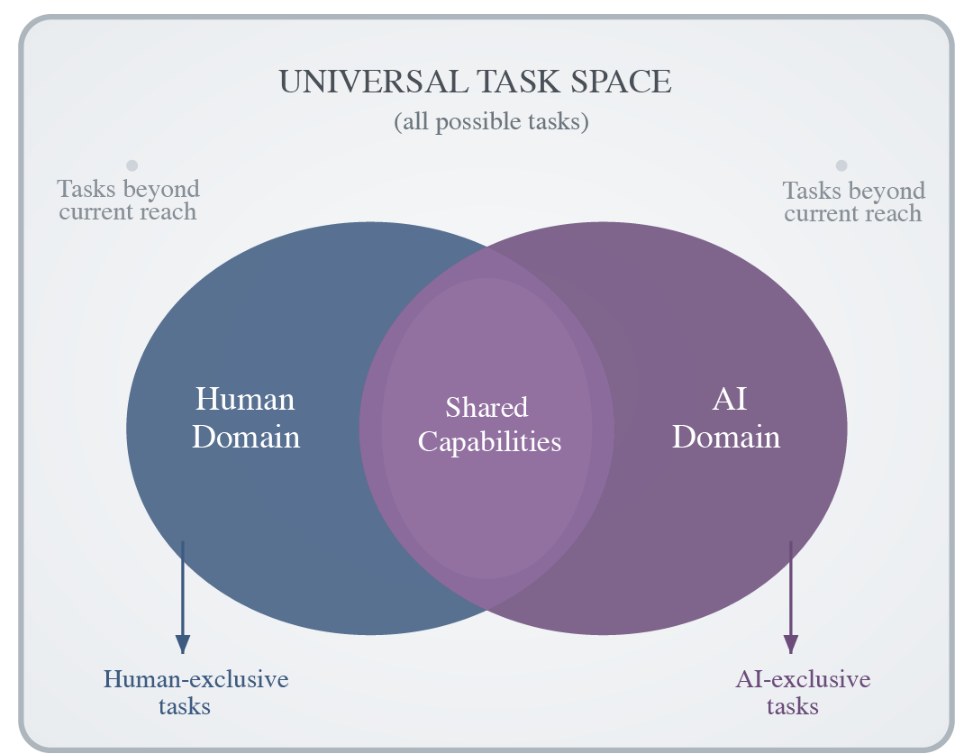 Task SpaceIllustration of the universal task space showing overlapping human and AI domains, with shared capabilities in the intersection and tasks beyond current reach on both sides.
Task SpaceIllustration of the universal task space showing overlapping human and AI domains, with shared capabilities in the intersection and tasks beyond current reach on both sides.
The paper identifies self-supervised learning and world models [5] as the most promising technical pathways toward SAI, pointing to architectures like I-JEPA [8] that learn latent representations without relying on autoregressive token prediction — a paradigm the authors argue faces exponential divergence as sequence length grows.
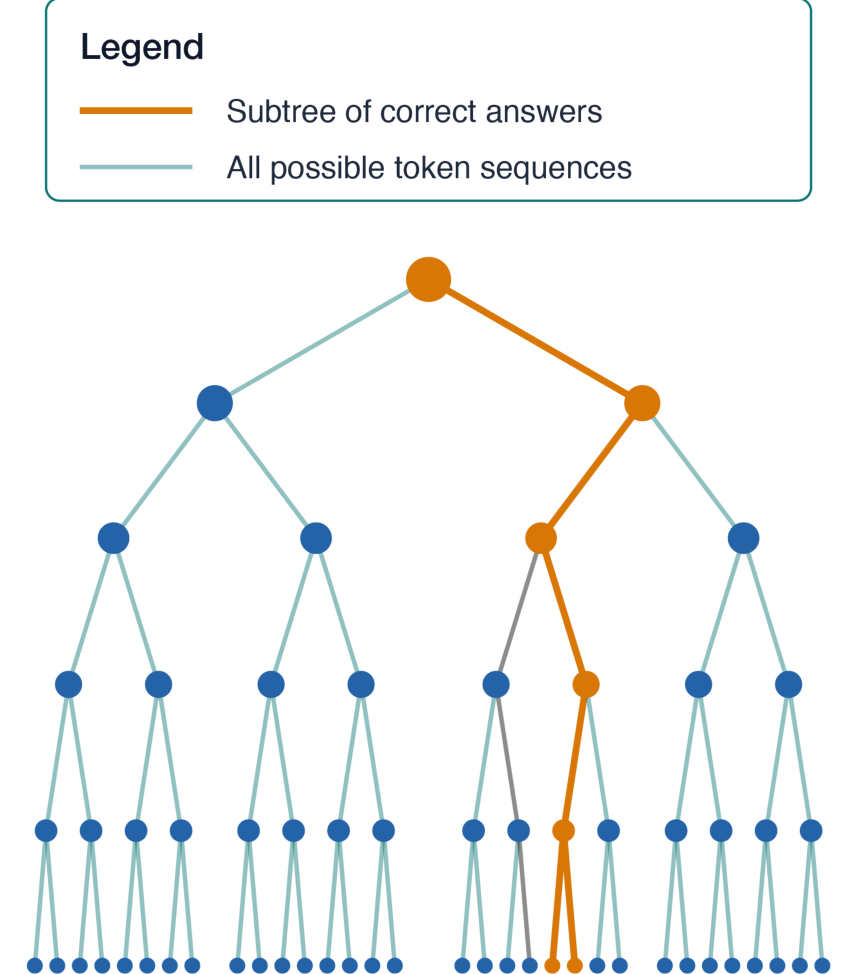 Autoregressive DivergenceTree diagram showing how the subtree of correct answers becomes exponentially smaller relative to all possible token sequences as prediction length increases, motivating the case for latent prediction architectures.
Autoregressive DivergenceTree diagram showing how the subtree of correct answers becomes exponentially smaller relative to all possible token sequences as prediction length increases, motivating the case for latent prediction architectures.
Research Context
This work builds on Chollet's "On the Measure of Intelligence" [1], which first proposed skill-acquisition efficiency as the key metric for intelligence, and LeCun's 2022 position paper [5] advocating world models and joint-embedding architectures as pathways to advanced AI.
What's genuinely new: The two-axis semantic taxonomy for organizing AGI definitions into three philosophical clusters, and the three-criteria evaluation framework that uniformly demonstrates why every prominent AGI definition is insufficient. These analytical tools are original contributions even though the underlying arguments (NFL against generality, adaptation as metric) build on established ideas.
Compared to Chollet's ARC framework [1, 10], the closest intellectual competitor, SAI shares the emphasis on adaptation efficiency but explicitly rejects human-centric benchmarking and extends the task domain beyond human capabilities. For scenarios requiring concrete benchmarks to measure progress today, Chollet's ARC remains more practical — it has active competitions and industry adoption, while SAI remains purely conceptual.
Open questions:
- How should "utility" be precisely defined to bound SAI's task scope? Without this, the definition's assessability advantage is hollow.
- Can adaptation speed be meaningfully compared across fundamentally different task domains, such as protein folding versus natural language?
- Does SAI's embrace of specialization imply a collection of narrow AI systems, and if so, how does it differ from the current AI landscape?
What SAI Still Needs
The paper is a conceptual contribution, not an empirical one. No benchmark for measuring adaptation speed is proposed, no experiment validates SAI's advantages as a research organizing principle, and the definition of "utility" — which bounds the entire framework's scope — is explicitly left to future work. The authors also exclude the consciousness dimension (Searle's Chinese Room argument), meaning SAI addresses only operational definitions of intelligence.
Beyond the authors' acknowledged limitations, the No Free Lunch argument [6] is applied selectively: it is used to dismiss definitions requiring universality, but SAI's own requirement to "exceed humans at any task humans can do" may face similar combinatorial challenges at scale. The paper's impact will ultimately depend on whether concrete SAI benchmarks emerge in follow-up work.
Check out the Paper. All credit goes to the researchers.
Resources
- Paper on arXiv
- MarkTechPost Coverage
- The Decoder Coverage
- Dr. Data Show Podcast
- ARC Prize 2025 Results
References
[1] Chollet, F. (2019). On the Measure of Intelligence. arXiv preprint. arXiv
[2] Hendrycks, D. et al. (2025). A Definition of AGI. arXiv preprint. arXiv
[3] Morris, M. R. et al. (2024). Position: Levels of AGI for Operationalizing Progress on the Path to AGI. ICML 2024. arXiv
[4] Legg, S., Hutter, M. (2007). Universal Intelligence: A Definition of Machine Intelligence. Minds and Machines. arXiv
[5] LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. Open Review. Paper
[6] Wolpert, D., Macready, W. (1997). No Free Lunch Theorems for Optimization. IEEE Transactions on Evolutionary Computation. Paper
[7] Finn, C. et al. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML 2017. arXiv
[8] Assran, M. et al. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. CVPR 2023. arXiv
[9] Ruder, S. (2017). An Overview of Multi-Task Learning in Deep Neural Networks. arXiv preprint. arXiv
[10] ARC Prize Foundation. (2025). ARC Prize 2025 Technical Report. arXiv preprint. arXiv