8x Terminal Performance Gains: NVIDIA's Data Recipe Lets 32B Beat 480B
NVIDIA's 32B model outperforms a 480B competitor on terminal tasks, proving that what you train on matters more than how big your model is.
Terminal agents like Claude Code and Codex CLI have demonstrated that LLMs can navigate command-line environments to compile code, train models, and configure systems. Yet the training data strategies powering these capabilities have remained opaque, forcing researchers into costly trial-and-error. A new study from NVIDIA addresses this transparency gap head-on, releasing both a systematic data engineering framework and the first comprehensive open-source playbook for building competitive terminal agents.
The paper introduces Terminal-Task-Gen, a synthetic data generation pipeline, and Terminal-Corpus, the resulting open-source dataset. Using these resources to fine-tune models from the Qwen3 [2] family, the team trains Nemotron-Terminal -- a family of models that achieve dramatic gains on Terminal-Bench 2.0 [1]. The 32B variant improves from 3.4% to 27.4%, an 8x gain that outperforms the 480B Qwen3-Coder (23.9%). While frontier agents using advanced scaffolding reach much higher scores on the current leaderboard (77.3% for Droid [8] with GPT-5.3-Codex), these results demonstrate that data engineering alone can bridge the gap between small open-source models and much larger ones.
The Data Pipeline: Two Complementary Strategies
Terminal-Task-Gen combines two data generation approaches that address distinct bottlenecks.
Dataset Adaptation converts existing high-quality prompt datasets into terminal format. Math prompts (163K from OpenMathReasoning), code prompts (35K from OpenCodeReasoning), and SWE prompts (32K from SWE-Bench-Train [9] and variants) are mapped into the Terminal-Bench task structure using the Terminus 2 system prompt template. This provides broad foundational coverage by leveraging existing problem repositories.
Synthetic Task Generation goes further, offering fine-grained control over task design. The pipeline supports two methods: seed-based generation transforms existing problems into terminal tasks with concrete software requirements and pytest test cases, while skill-based generation synthesizes novel tasks from a curated taxonomy of primitive skills across 9 domains (security, data processing, software engineering, and others). Each generated task combines 3-5 skills for compositional problem-solving rather than isolated skill application.
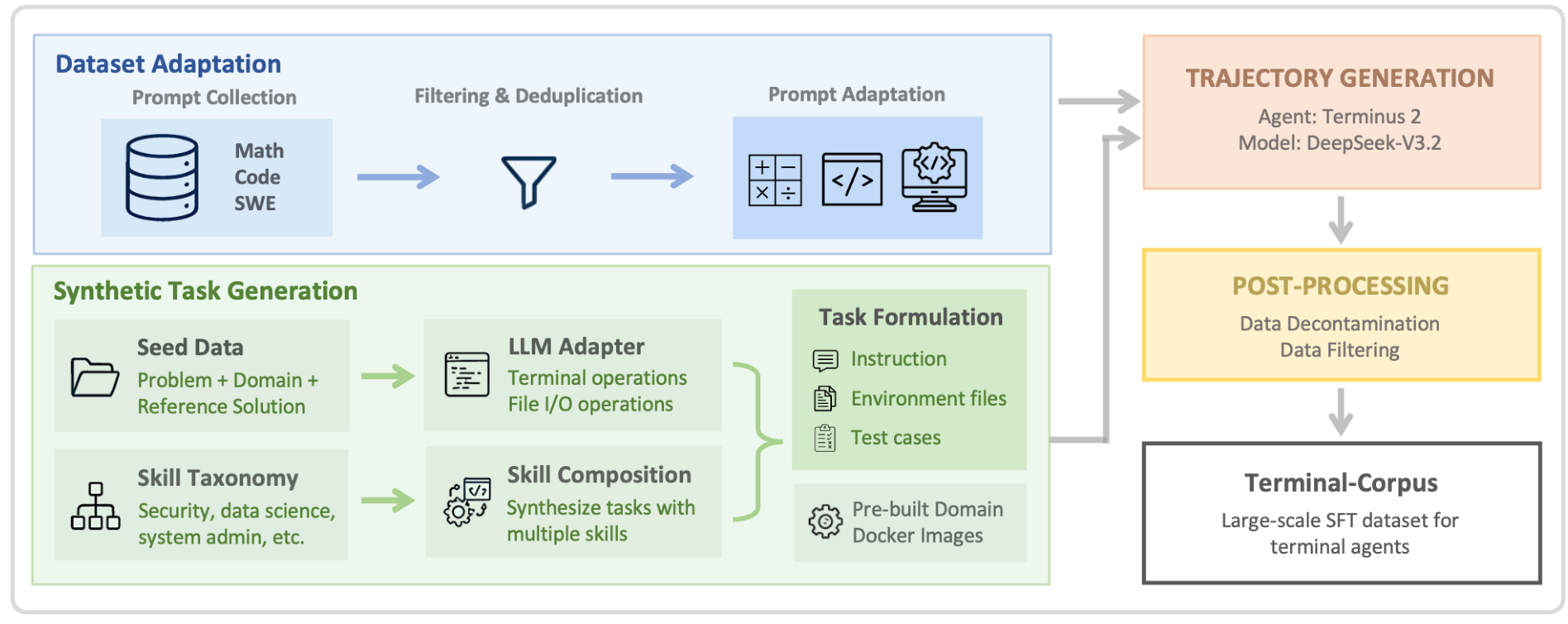 Terminal-Task-Gen PipelineOverview of the Terminal-Task-Gen framework showing how Dataset Adaptation and Synthetic Task Generation feed into Trajectory Generation with Dockerized environments, followed by Post-Processing to yield the final SFT dataset.
Terminal-Task-Gen PipelineOverview of the Terminal-Task-Gen framework showing how Dataset Adaptation and Synthetic Task Generation feed into Trajectory Generation with Dockerized environments, followed by Post-Processing to yield the final SFT dataset.
A critical engineering decision enables the pipeline to scale: instead of generating a unique Dockerfile per task like prior multi-agent approaches [10, 4], the team maintains just 9 pre-built, domain-specific Docker images. This eliminates Dockerfile validation overhead, reduces resource footprint, and decouples environment from task generation. All trajectories are generated using DeepSeek-V3.2 [3] as the teacher model, orchestrated through the Harbor framework on HPC clusters with 32-128 GPUs depending on model size.
The Counter-Intuitive Finding: Keep the Failures
Perhaps the most practically useful result is a finding that goes against conventional wisdom. When filtering training trajectories, retaining failed and incomplete attempts actually improves performance. Filtering to only successful trajectories drops performance from 12.4% to 5.06% on the 8B model -- a 2.45x degradation. The authors argue that exposure to realistic error states and recovery patterns provides valuable training signal, teaching models robustness rather than just correct execution.
Other data engineering insights reinforce the "less filtering is more" theme: combining all data sources outperforms any individual subset, single-stage mixed training beats two-stage curriculum learning, and extending context length to 65K tokens slightly hurts rather than helps, since long-tail trajectories tend to be noisy and less informative.
Results: Small Models, Big Gains
The Nemotron-Terminal family demonstrates substantial improvements across all model sizes on Terminal-Bench 2.0 [1]:
- Nemotron-Terminal-8B: 2.5% to 13.0% (5.3x improvement)
- Nemotron-Terminal-14B: 4.0% to 20.2% (5x improvement, surpassing the 120B GPT-OSS at 18.7%)
- Nemotron-Terminal-32B: 3.4% to 27.4% (8.1x improvement, outperforming the 480B Qwen3-Coder at 23.9%)
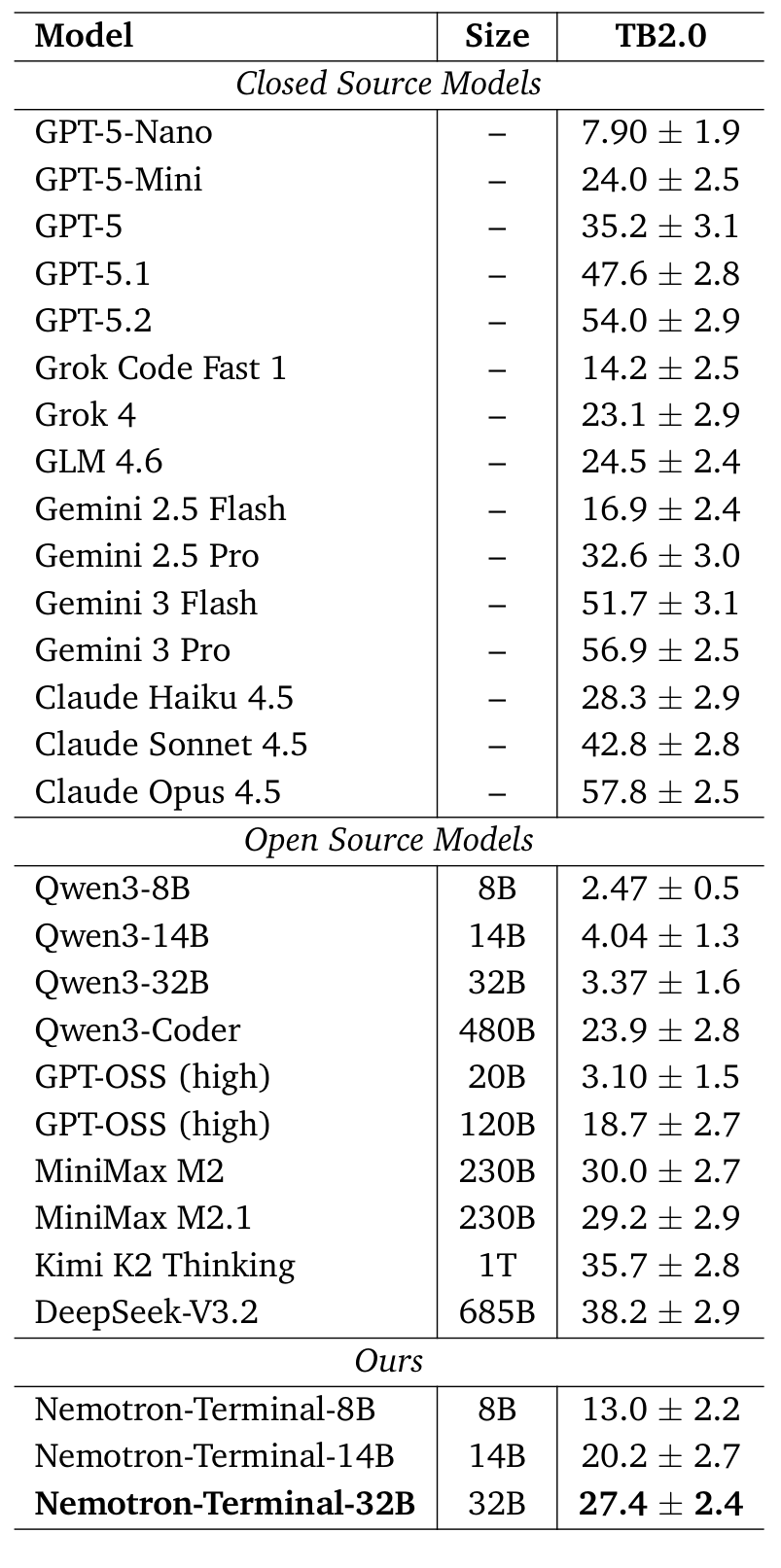 Terminal-Bench ResultsComprehensive Terminal-Bench 2.0 results comparing Nemotron-Terminal against closed-source and open-source models. The 32B variant outperforms models with up to 15x more parameters.
Terminal-Bench ResultsComprehensive Terminal-Bench 2.0 results comparing Nemotron-Terminal against closed-source and open-source models. The 32B variant outperforms models with up to 15x more parameters.
The per-category breakdown tells an even more striking story. Synthetic data unlocks capabilities that were completely absent in the base models: Data Querying jumps from 0% to 60%, Model Training from 0% to 50%, and Data Processing from 5% to 50% for the 32B model. However, Mathematics and Games remain at 0% across all sizes, indicating fundamental capability gaps that data engineering alone cannot bridge.
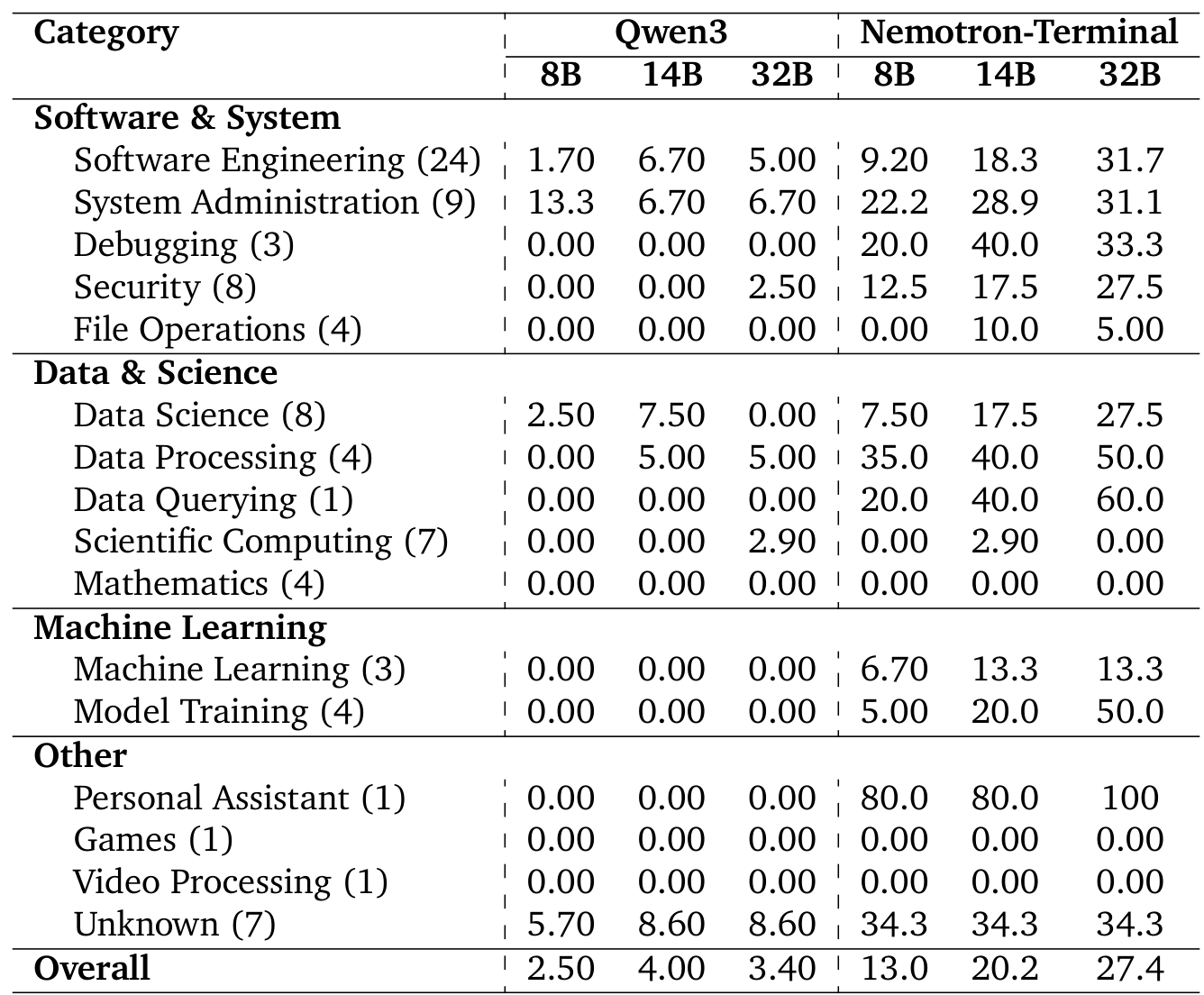 Category BreakdownPer-category Terminal-Bench 2.0 scores showing where Nemotron-Terminal most improves over Qwen3 baselines, with dramatic gains in Data Querying, Model Training, and Data Processing.
Category BreakdownPer-category Terminal-Bench 2.0 scores showing where Nemotron-Terminal most improves over Qwen3 baselines, with dramatic gains in Data Querying, Model Training, and Data Processing.
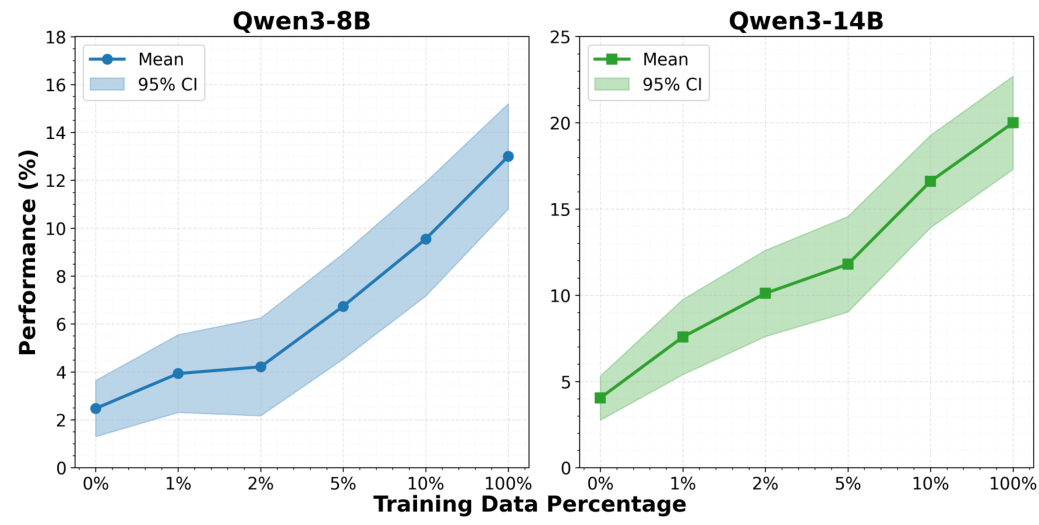 Scaling ResultsTraining data scale experiments showing consistent performance improvements for both Qwen3-8B and Qwen3-14B as data volume increases, with the larger model exhibiting greater gains.
Scaling ResultsTraining data scale experiments showing consistent performance improvements for both Qwen3-8B and Qwen3-14B as data volume increases, with the larger model exhibiting greater gains.
Scaling experiments show that performance increases consistently with training data volume, and larger models extract more value from additional data. The 14B model achieves greater absolute gains per data increment than the 8B, confirming that both model capacity and data scale are critical factors.
Research Context
This work builds on the Evol-Instruct [5] paradigm for synthetic data scaling and the AgentInstruct [6] framework for taxonomy-driven dataset generation, adapting these approaches specifically for terminal agent training. The prompt datasets are drawn from NVIDIA's Nemotron-Cascade [7] pipeline. DeepSeek-V3.2 [3] serves as the teacher model for trajectory generation, selected for its strong Terminal-Bench performance (38.2%).
What's genuinely new: The first open-source study of data engineering for terminal agents, the pre-built Docker image strategy for scalable task generation, and the empirical demonstration that retaining failed trajectories improves training outcomes.
Compared to LiteCoder-Terminal [4], which achieves competitive results on Terminal-Bench 1.0 with fewer than 1,000 training samples, Nemotron-Terminal trades data efficiency for higher absolute performance using approximately 490K samples. For teams with limited compute, LiteCoder's data-efficient approach may be more practical. Meanwhile, agent scaffolding approaches like Factory AI's Droid [8] achieve much higher scores (77.3% on the current TB2.0 leaderboard) by combining frontier models with sophisticated agent engineering rather than improving the base model -- a complementary strategy.
Open questions: Would reinforcement learning yield further gains beyond SFT? Why do Mathematics and Games categories show zero improvement despite math-heavy training data? How do these data engineering techniques transfer to other base model families?
Check out the Paper and HuggingFace Collection. All credit goes to the researchers.
References
[1] Merrill, M. et al. (2026). Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces. arXiv. arXiv
[2] Yang, A. et al. (2025). Qwen3 Technical Report. arXiv. arXiv
[3] Liu, A. et al. (2025). DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv. arXiv
[4] Peng, X. et al. (2025). LiteCoder-Terminal: Lightweight Terminal Agents with <1k Synthesized Trajectories. HuggingFace Blog. Link
[5] Xu, C. et al. (2023). WizardLM: Empowering Large Language Models to Follow Complex Instructions. arXiv. arXiv
[6] Mitra, A. et al. (2024). AgentInstruct: Toward Generative Teaching with Agentic Flows. arXiv. arXiv
[7] Wang, B. et al. (2025). Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models. arXiv. arXiv
[8] Singhal, A. et al. (2025). Droid: The #1 Software Development Agent on Terminal-Bench. Factory AI News. Link
[9] Jimenez, C. et al. (2023). SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?. arXiv. arXiv
[10] Austin, D. (2025). Terminal bench agentic data pipeline. GitHub. GitHub