Mirage of Synthesis: DREAM's Agentic Framework Catches What Static Benchmarks Miss
Your AI research agent scored 85% on the benchmark — but it's citing outdated facts, reasoning in circles, and its sources don't actually say what it claims.
Your AI research agent scored 85% on the benchmark — but it's citing outdated facts, reasoning in circles, and its sources don't actually say what it claims. The benchmark never noticed. DREAM did.
Deep Research Agents (DRAs) from OpenAI, Google, and Alibaba are increasingly deployed to generate analyst-grade reports — yet the benchmarks certifying their quality may be fundamentally misleading. A recent survey [9] highlighted critical gaps in existing evaluation frameworks, and concurrent work [1, 6, 7] underscores the urgency of this problem. Building on the Agent-as-a-Judge paradigm [2], researchers from AWS Agentic AI and Georgia Tech now propose DREAM (Deep Research Evaluation with Agentic Metrics), a framework that makes evaluation itself agentic, exposing failures that static benchmarks systematically miss.
The core issue is what the authors term the Mirage of Synthesis — an illusion of quality where surface-level fluency and citation alignment obscure underlying factual errors, temporal obsolescence, and flawed reasoning. A report can cite the right-looking sources, read beautifully, and still be wrong. Current evaluators, lacking the ability to verify claims against live evidence, cannot catch these defects.
The Capability Parity Principle
DREAM is built on a simple but powerful insight: the evaluator should possess similar capabilities as the agent it evaluates. If a DRA can search the web, reason over retrieved documents, and synthesize information, its evaluator must be able to do the same. This "capability parity" principle directly challenges the dominant LLM-as-a-Judge paradigm [5], which relies on a static LLM scoring outputs without external tool access.
Conventional evaluators like G-eval [4] can measure fluency and structural quality, but they cannot verify whether a cited claim is actually true, whether information is current, or whether reasoning chains hold up under scrutiny. DREAM addresses this by deploying tool-calling agents as evaluators.
How DREAM Works: Two-Phase Agentic Evaluation
DREAM operates in two phases. In Protocol Creation, query-independent Static Metrics (Writing Quality, Factuality, Citation Integrity, Domain Authoritativeness) are combined with Adaptive Metrics generated by a Protocol Creation Agent equipped with web search, ArXiv, and GitHub tools. This agent researches the query to create Key-Information Coverage (KIC) checklists with temporally-aware yes/no questions, and Reasoning Quality (RQ) probes with structured validation plans. Human evaluation validates this pipeline: KIC checklists scored 0.92 average quality versus 0.79 for LLM-only, while RQ probes scored 0.93 versus 0.70 — confirming that agentic protocol creation produces substantially better evaluation criteria.
In Protocol Execution, each metric is routed to the appropriate evaluator based on its capability requirements. Three evaluator types handle distinct tasks:
- LLM Evaluator handles Writing Quality and KIC — metrics requiring judgment against rubrics or checklists.
- Agent Evaluator executes RQ validation plans by retrieving external evidence and scoring reasoning soundness.
- Workflow Evaluator runs multi-step verification pipelines for Factuality (claim extraction → neutralized search → dual-stream evidence → judgment), Citation Integrity (claim attribution + citation faithfulness), and Domain Authoritativeness.
The Factuality pipeline is particularly notable. Rather than simply checking whether claims match their cited sources — which is all that existing FACT-style metrics do — DREAM extracts claims, constructs neutralized queries to avoid confirmation bias, and searches for both supporting and opposing evidence before rendering a verdict.
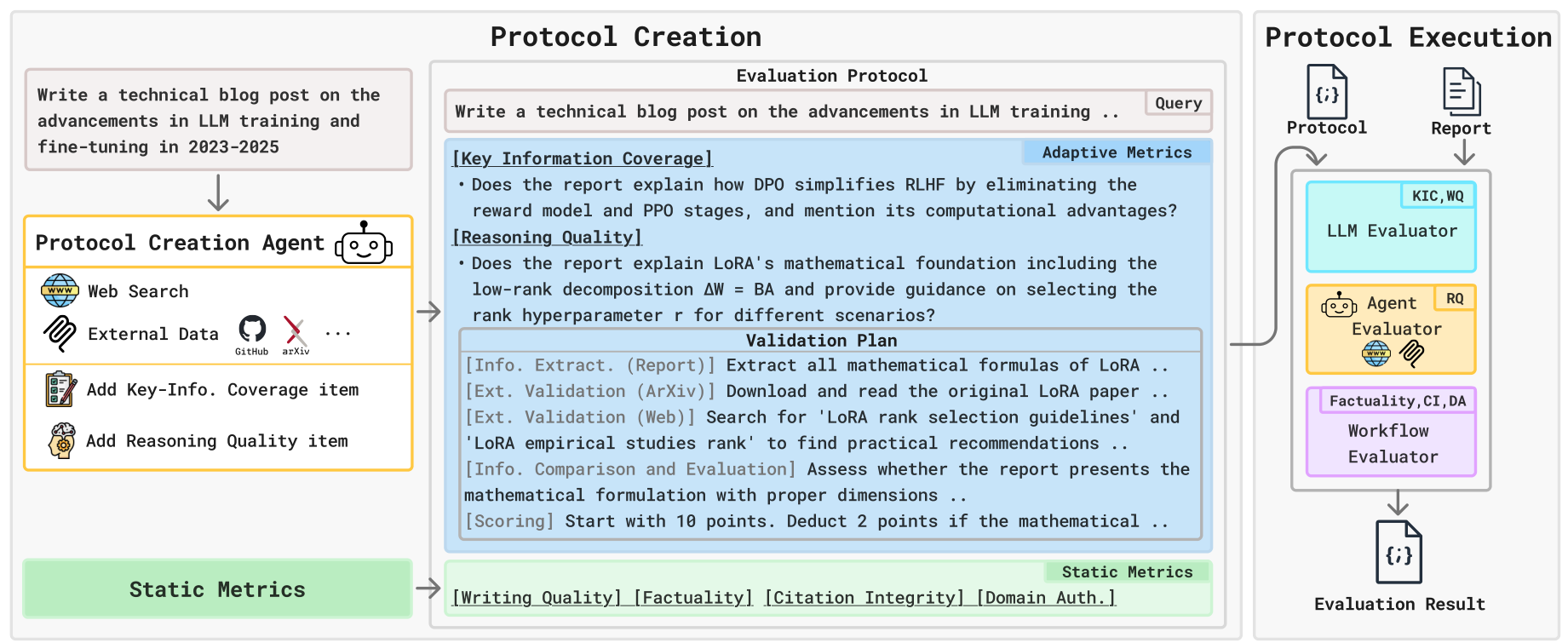 DREAM ArchitectureThe two-phase framework showing Protocol Creation (left) with static and adaptive metrics, and Protocol Execution (right) routing metrics to LLM, Agent, and Workflow evaluators.
DREAM ArchitectureThe two-phase framework showing Protocol Creation (left) with static and adaptive metrics, and Protocol Execution (right) routing metrics to LLM, Agent, and Workflow evaluators.
Figure 2: The two-phase DREAM framework showing Protocol Creation (left) with static and adaptive metrics, and Protocol Execution (right) routing metrics to LLM, Agent, and Workflow evaluators.
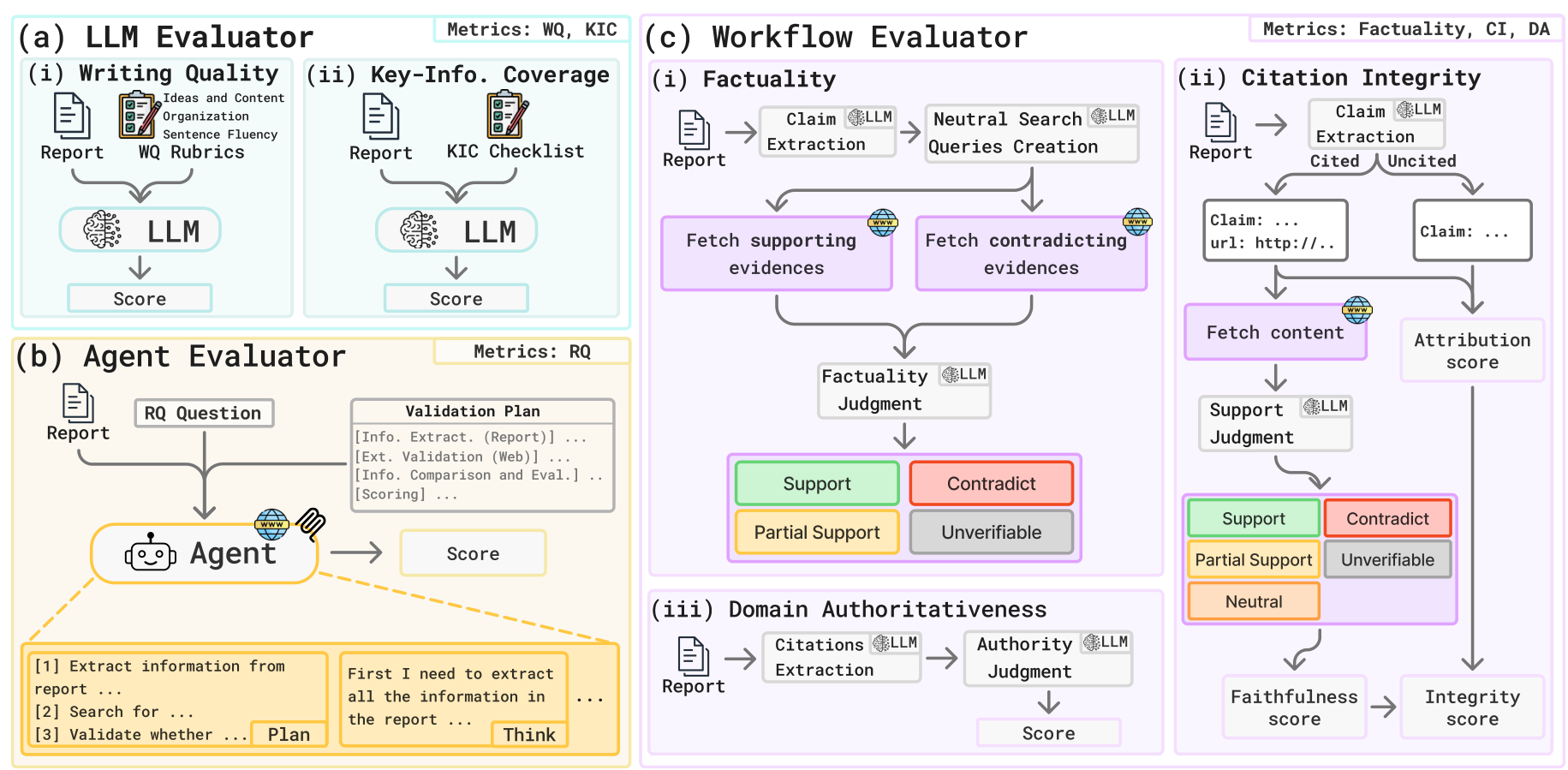 Evaluator TypesDetailed view of the three Protocol Execution evaluators: LLM Evaluator for writing quality and coverage, Agent Evaluator for reasoning verification, and Workflow Evaluator for factuality, citation integrity, and domain authoritativeness.
Evaluator TypesDetailed view of the three Protocol Execution evaluators: LLM Evaluator for writing quality and coverage, Agent Evaluator for reasoning verification, and Workflow Evaluator for factuality, citation integrity, and domain authoritativeness.
Figure 3: Detailed view of the three Protocol Execution evaluators showing internal pipelines for LLM, Agent, and Workflow evaluation.
Benchmark Autopsy: Where Static Evaluation Fails
Controlled experiments reveal stark sensitivity differences between DREAM and DeepResearch Bench (DRB) [1], the leading benchmark with 100 PhD-level tasks.
Temporal Sensitivity. When DRA reports were generated with simulated outdated knowledge cutoffs, DREAM-KIC scores degraded from 79.35 (current) to 44.80 (Jan 2025) to 22.34 (Jan 2024) — a ~72% total drop monotonically tracking information staleness. DRB-RACE Comprehensiveness showed only ~10% degradation across the same conditions, remaining nearly flat even for reports built on year-old information.
Reasoning Flaw Detection. In a controlled experiment with matched pairs of well-reasoned and deliberately malformed reports, DREAM-RQ produced a mean 35.16% score degradation (median 40.12%), while DRB-RACE showed a mean of only 10.93% (median 9.08%) — the paper characterizes this as approximately 4x greater sensitivity. Notably, DRB-RACE sometimes scored malformed reports higher than well-reasoned ones — the Mirage of Synthesis in action.
 Reasoning Flaw DetectionDensity distributions of relative score degradation between well-reasoned and malformed reports, showing DREAM-RQ centered at ~40% degradation versus DRB-RACE at ~9%.
Reasoning Flaw DetectionDensity distributions of relative score degradation between well-reasoned and malformed reports, showing DREAM-RQ centered at ~40% degradation versus DRB-RACE at ~9%.
Figure 5: Density distributions showing DREAM-RQ produces consistent degradation for malformed reports (centered at ~40%), while DRB-RACE shows weak sensitivity with malformed reports sometimes outscoring well-reasoned ones.
Factual Error Sensitivity. When factually incorrect but well-cited claims were injected at increasing rates, DREAM-Factuality degraded monotonically, closely tracking the true error rate. DRB-FACT scores remained completely invariant across all corruption levels, because the metric validates claims solely against the provided (misleading) sources rather than against ground truth.
 DREAM ResultsThree-panel illustration showing active reasoning verification against external sources (left), factual error sensitivity where DREAM degrades with corruption while DRB-FACT stays flat (middle), and temporal validity sensitivity where DREAM-KIC drops with older cutoffs while DRB-RACE stays flat (right).
DREAM ResultsThree-panel illustration showing active reasoning verification against external sources (left), factual error sensitivity where DREAM degrades with corruption while DRB-FACT stays flat (middle), and temporal validity sensitivity where DREAM-KIC drops with older cutoffs while DRB-RACE stays flat (right).
Figure 1: Three-panel comparison showing DREAM's sensitivity advantages: active reasoning verification (left), factual error detection (middle), and temporal validity tracking (right).
Open-Source DRAs Under the Microscope
Applying DREAM to three open-source DRAs revealed a critical pattern: these systems produce informative, well-written reports but suffer from severely poor citation grounding. Smolagents Open DR achieved the highest aggregate scores (Factuality: 58.15, KIC: 75.95, RQ: 69.16), but Citation Integrity scores were critically low across all systems — Tongyi scored just 1.03, Smolagents 4.78, and LangChain 15.92 on a 100-point scale. This suggests open-source DRAs are generating reports that look well-sourced but whose citations frequently do not support the claims attributed to them.
Research Context
This work builds on two lines of research: the Agent-as-a-Judge paradigm [2], which pioneered agentic evaluation in structured domains like code generation, and atomic factuality methods like FActScore [3] and FacTool [8], which introduced claim-level decomposition for verifying long-form text.
What's genuinely new:
- The "Mirage of Synthesis" concept — formalizing how fluency and citation alignment systematically obscure factual, temporal, and reasoning defects
- The "capability parity" principle instantiated through a two-phase agentic protocol with three specialized evaluator types
- Temporally-aware evaluation criteria generated through live web search, enabling detection of information decay that static rubrics entirely miss
- Dual-stream evidence extraction with neutralized queries to avoid confirmation bias in factuality assessment
Compared to DeepResearch Bench [1], DREAM offers dramatically higher sensitivity to the failure modes that matter most for trustworthy research outputs. For scenarios requiring lower cost, reproducibility, or evaluation without external API dependencies, static benchmarks like DRB [1], LiveResearchBench [6], or ResearchRubrics [7] remain practical alternatives.
Open questions:
- What is the actual computational cost of a full DREAM evaluation versus static benchmarks? The paper identifies this as a limitation but provides no quantification.
- How robust is DREAM across backbone LLMs? The primary experiments use Claude Sonnet 4.5, and while a sensitivity analysis with DeepSeek-V3.2 and Kimi-K2.5 shows stable agent rankings, absolute scores fluctuate — suggesting further cross-model validation is needed.
- Can DREAM effectively evaluate proprietary frontier DRAs (OpenAI, Google, Perplexity), which generate the highest-quality reports?
Check out the Paper. All credit goes to the researchers.
References
[1] Du, M. et al. (2025). DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv. arXiv
[2] Zhuge, M. et al. (2024). Agent-as-a-Judge: Evaluate Agents with Agents. arXiv. arXiv
[3] Min, S. et al. (2023). FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. EMNLP 2023. arXiv
[4] Liu, Y. et al. (2023). G-eval: NLG Evaluation Using GPT-4 with Better Human Alignment. arXiv. arXiv
[5] Zheng, L. et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023. arXiv
[6] Wang, J. et al. (2025). LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild. arXiv. arXiv
[7] Sharma, M. et al. (2025). ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents. arXiv. arXiv
[8] Chern, I. et al. (2023). FacTool: Factuality Detection in Generative AI. arXiv. arXiv
[9] Huang, Y. et al. (2025). Deep Research Agents: A Systematic Examination and Roadmap. arXiv. arXiv