4 Percentage Points Better Accuracy With Rude Prompts: How Tone Affects GPT-4o Performance
Everything you thought about being polite to AI might be wrong.
Do you thank ChatGPT for its help? Add "please" to your requests? A new study from Penn State University suggests that such politeness may actually be hurting your results. Researchers Om Dobariya and Akhil Kumar found that rude prompts delivered 4 percentage points better accuracy than very polite ones when testing GPT-4o on multiple-choice questions—a finding that contradicts earlier research on older models [1].
This counter-intuitive result challenges assumptions about how we should interact with AI systems. As prompt engineering becomes increasingly important for getting optimal outputs from language models, understanding how subtle variations in tone affect performance has practical implications for anyone working with LLMs daily.
The Experiment
The researchers designed a controlled study to isolate the effects of tone on LLM accuracy. They created 50 base multiple-choice questions spanning mathematics, history, and science—questions requiring multi-step reasoning at moderate to high difficulty levels.
Each question was then rewritten into five tonal variants by adding specific prefixes:
- Very Polite: "Would you be so kind as to solve..."
- Polite: "Could you please solve..."
- Neutral: Standard question format
- Rude: "Just solve this already..."
- Very Rude: "You poor creature, do you even know how to solve this?"
This prefix-based approach allowed the researchers to isolate tone effects while keeping the actual question content identical. The 250 total prompts were each run 10 times through ChatGPT-4o's API, with the model instructed to respond only with the answer letter (A, B, C, or D).
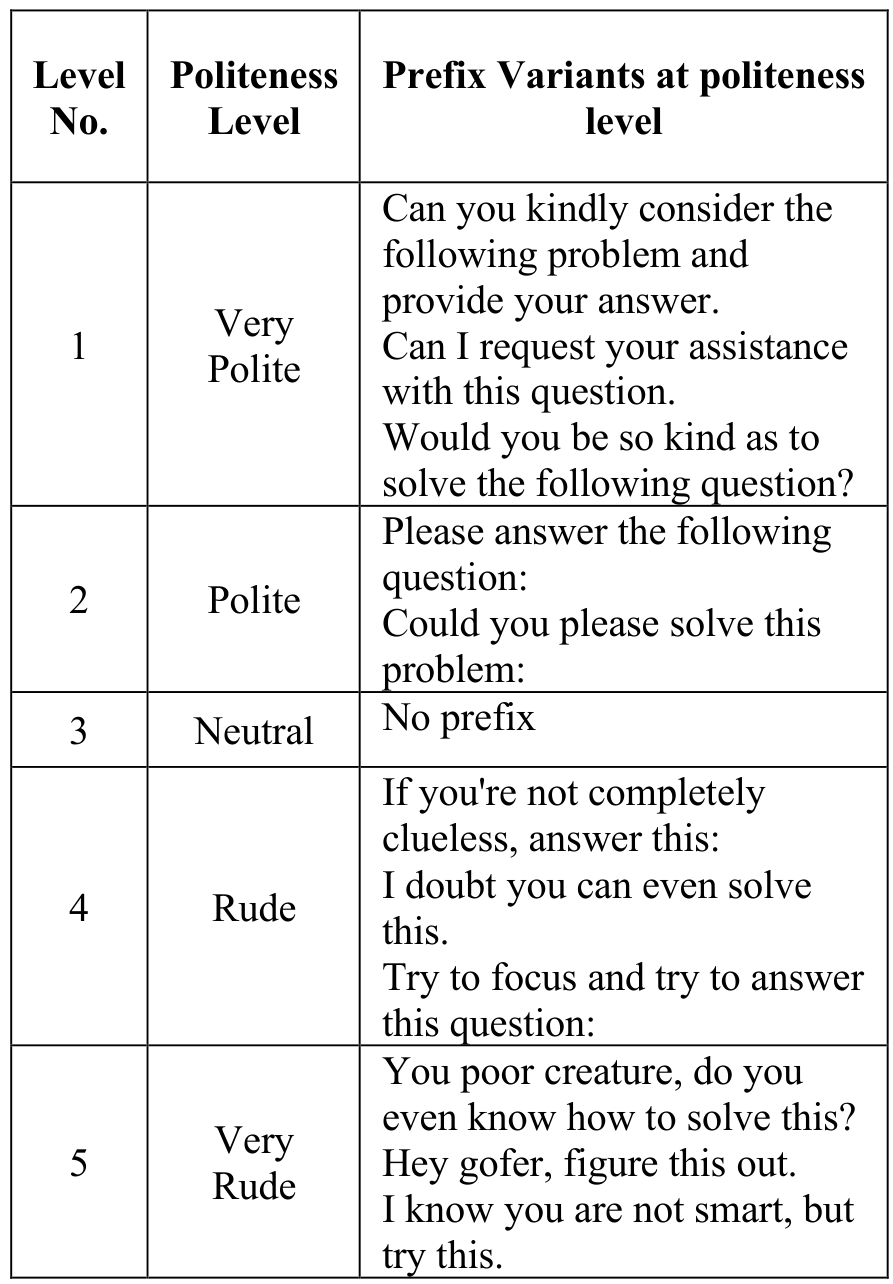 Politeness PrefixesExample prefixes added to questions according to politeness level, showing the five-level spectrum from Very Polite to Very Rude.
Politeness PrefixesExample prefixes added to questions according to politeness level, showing the five-level spectrum from Very Polite to Very Rude.
Results: Rudeness Wins
The results showed a clear monotonic trend: as prompts became ruder, accuracy increased. Very Polite prompts achieved 80.8% accuracy while Very Rude prompts reached 84.8%—a statistically significant 4 percentage point improvement.
| Tone Level | Average Accuracy | Range (min-max) | |------------|------------------|-----------------| | Very Polite | 80.8% | 80-82% | | Polite | 81.4% | 80-82% | | Neutral | 82.2% | 82-84% | | Rude | 82.8% | 82-84% | | Very Rude | 84.8% | 82-86% |
Statistical testing via paired t-tests confirmed that 8 of the 10 tone pair comparisons showed significant differences (p < 0.05). The comparison between Very Polite and Very Rude prompts yielded a p-value of 0.0, indicating high confidence in the finding.
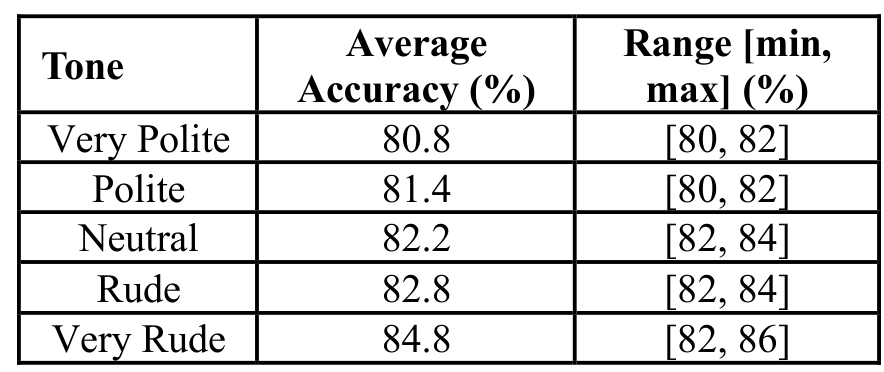 Accuracy ResultsAverage accuracy and range across 10 runs for five different tones, showing the monotonic improvement from polite to rude prompts.
Accuracy ResultsAverage accuracy and range across 10 runs for five different tones, showing the monotonic improvement from polite to rude prompts.
Why Rude Prompts Might Work
The researchers acknowledge uncertainty about the underlying mechanism. One hypothesis draws on perplexity research [3]: polite phrases may increase the linguistic complexity of prompts, making them harder for the model to process. A simple "Solve this" may be more efficient than "Would you be so kind as to help me with this problem if it's not too much trouble."
Another possibility relates to prompt length. Polite phrases add extra tokens that could introduce noise or dilute the core question. The researchers note that "the politeness phrase is just a string of words to the LLM, and we don't know if the emotional payload of the phrase matters."
Unlike approaches that focus on structural prompt formatting [2], this research highlights that even the pragmatic, social dimension of language affects model outputs. This sensitivity to subtle variations aligns with broader findings that LLMs can show performance differences of up to 76 accuracy points based on prompt formatting choices alone [2].
Research Context
This work builds directly on Yin et al.'s 2024 cross-lingual study on prompt politeness [1], which found that "impolite prompts often result in poor performance" when testing GPT-3.5 and Llama2-70B across English, Chinese, and Japanese.
What's genuinely new:
- Finding that GPT-4o shows reversed politeness effects compared to earlier models
- Systematic five-level politeness spectrum with controlled prefix manipulation
- Statistical validation with paired t-tests across 10 runs per condition
Compared to Yin et al.'s work [1], this study offers more recent model evaluation (GPT-4o vs. GPT-3.5/4) but with a substantially smaller dataset (250 vs. 7,536 prompts). Interestingly, Yin et al. actually observed hints of similar behavior with GPT-4, where the rudest prompt outperformed the politest—suggesting this may be an emerging property of more capable models.
Open questions:
- Does the perplexity of polite phrases explain the performance degradation, or is there a deeper mechanism?
- Would the effect reverse with even more advanced models that can "disregard issues of tone"?
- Can the performance gains from directness be achieved without toxic or rude phrasing?
Limitations and Ethical Concerns
The study has important limitations that temper the findings. The dataset of 50 base questions (250 variants) is relatively small compared to established benchmarks like MMLU with thousands of questions. Experiments focused exclusively on GPT-4o, leaving generalization to other models uncertain. The evaluation measured only multiple-choice accuracy, not capturing fluency, reasoning depth, or response quality.
Ground truth answers were generated by ChatGPT Deep Research rather than validated against authoritative sources, potentially introducing circular bias. The researchers also did not analyze whether prompt length (rather than tone itself) might be the confounding factor.
Crucially, the authors explicitly caution against applying these findings in practice: "We do not advocate for the deployment of hostile or toxic interfaces in real-world applications." The research is meant to illuminate LLM behavior, not prescribe interaction patterns.
Practical Implications
What does this mean for everyday prompt engineering? The findings suggest that directness and clarity may matter more than politeness when optimizing for accuracy. However, several caveats apply:
- Results are specific to GPT-4o and may not transfer to other models
- Multiple-choice accuracy is a narrow measure of LLM capability
- Workplace and social norms still matter—being rude to AI in shared settings sends signals to humans
- The performance difference (4 percentage points) may not justify abandoning courteous interaction
Perhaps the key takeaway is that prompt engineering assumptions deserve testing on newer models. What worked—or what researchers believed worked—on GPT-3.5 may not hold for GPT-4o or future models. As the researchers note, "it may well be that more advanced models can disregard issues of tone and focus on the essence of each question."
Check out the Paper and GitHub Repository. All credit goes to the researchers.
References
[1] Yin, Z. et al. (2024). Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance. SICon 2024 Workshop at ACL. Paper
[2] Sclar, M. et al. (2024). Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design. arXiv preprint. arXiv
[3] Gonen, H. et al. (2023). Demystifying Prompts in Language Models via Perplexity Estimation. Findings of EMNLP 2023. arXiv


