6x Fewer Tokens, Better OCR: DeepSeek's Visual Causal Flow Beats GPT-4o and Gemini
What if vision models could read documents the way humans do - following the logical flow of content rather than mechanically scanning left-to-right, top-to-bottom?
When reading a complex document, humans do not scan mechanically from top-left to bottom-right. Instead, our eyes follow semantic patterns - jumping between related content, tracing logical structures, and building understanding through causally-informed sequences. Yet conventional vision-language models force visual tokens into rigid raster-scan ordering, creating a fundamental mismatch between how documents are structured and how models process them.
Researchers from DeepSeek-AI have addressed this limitation with DeepSeek-OCR 2, introducing a novel encoder architecture called DeepEncoder V2 that dynamically reorders visual tokens based on image semantics. Building on their previous work [1], the team achieves state-of-the-art results among end-to-end models while using just 1,120 visual tokens - compared to the 6,000+ tokens required by competing approaches like Qwen2.5-VL [4] and InternVL3.
The Reading Order Problem
Existing vision-language models flatten 2D image patches into 1D sequences using fixed raster-scan ordering. When processing a multi-column document, a table with complex structure, or a form with scattered fields, this rigid ordering ignores the semantic relationships that make content coherent. The result: models must work harder to reconstruct logical reading flow from positionally-encoded tokens that bear no relation to meaning.
DeepEncoder V2 takes inspiration from human visual perception. Rather than imposing spatial ordering through positional encodings like RoPE [2], it introduces "causal flow queries" - learnable tokens that progressively attend to visual features and reorder them based on content semantics before the language model processes them.
How Visual Causal Flow Works
The architecture consists of three main components working in cascade.
Vision Tokenizer: Following DeepEncoder [1], images pass through an 80M-parameter SAM-based encoder with convolutional layers, achieving 16x token compression through window attention. This significantly reduces the token count before global attention operations.
LLM-Style Vision Encoder: This is where the innovation lies. Rather than using a CLIP ViT [7] like most VLMs, DeepEncoder V2 employs Qwen2-0.5B [5] - a 500M parameter language model architecture - as the vision encoder. Visual tokens use bidirectional attention (like ViT), while newly introduced causal flow queries use causal attention (like LLM decoders).
Causal Flow Queries: The key mechanism. Learnable query tokens (equal in number to visual tokens) are appended as a suffix. Through a customized attention mask, each query can attend to ALL visual tokens plus all preceding queries. This enables progressive causal reordering - the queries learn to output visual information in semantically meaningful order rather than spatial order.
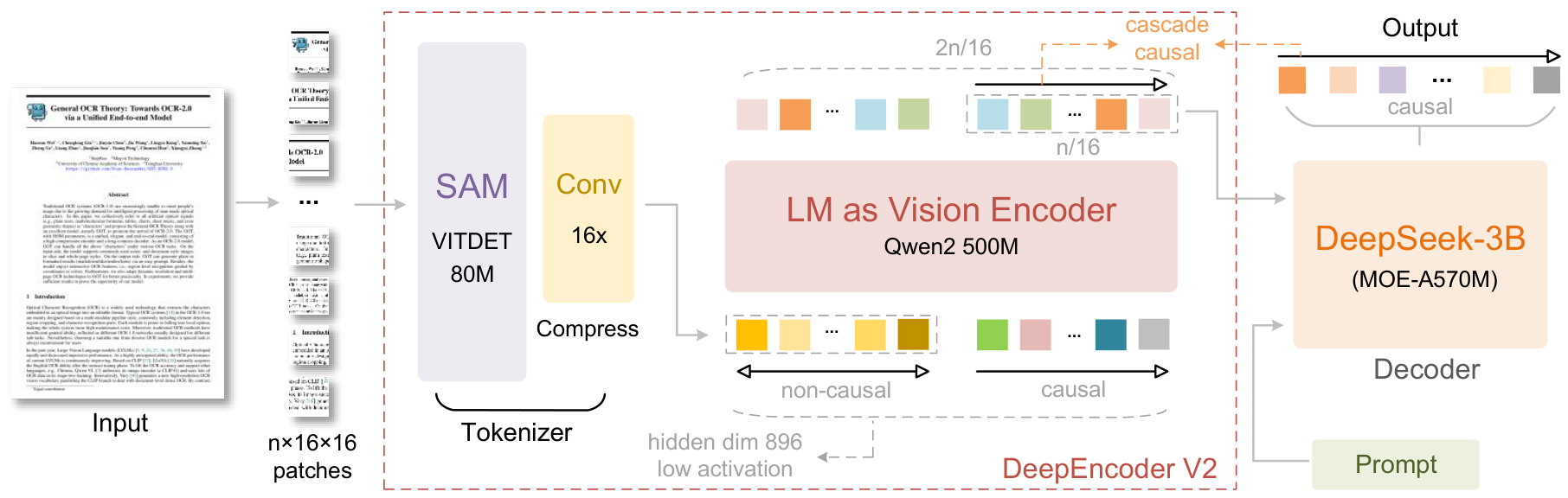 DeepEncoder V2 ArchitectureThe system replaces CLIP with an LLM-style encoder, combining bidirectional attention for visual tokens with causal attention for learnable queries that reorder visual information.
DeepEncoder V2 ArchitectureThe system replaces CLIP with an LLM-style encoder, combining bidirectional attention for visual tokens with causal attention for learnable queries that reorder visual information.
The attention mask structure is elegantly simple: a block matrix where the top-left quadrant (visual tokens) uses full bidirectional attention, while the bottom-right quadrant (causal queries) uses triangular causal masking. The queries can see all visual tokens but only preceding queries, enforcing progressive ordering.
Two Cascaded 1D Reasoners for 2D Understanding
The architecture creates what the researchers call "two-cascaded 1D causal reasoning structures." The encoder performs reading logic reasoning (reordering visual tokens through queries), while the decoder executes visual task reasoning over the causally-ordered sequence. This decomposition may represent a path toward genuine 2D reasoning using 1D language model primitives.
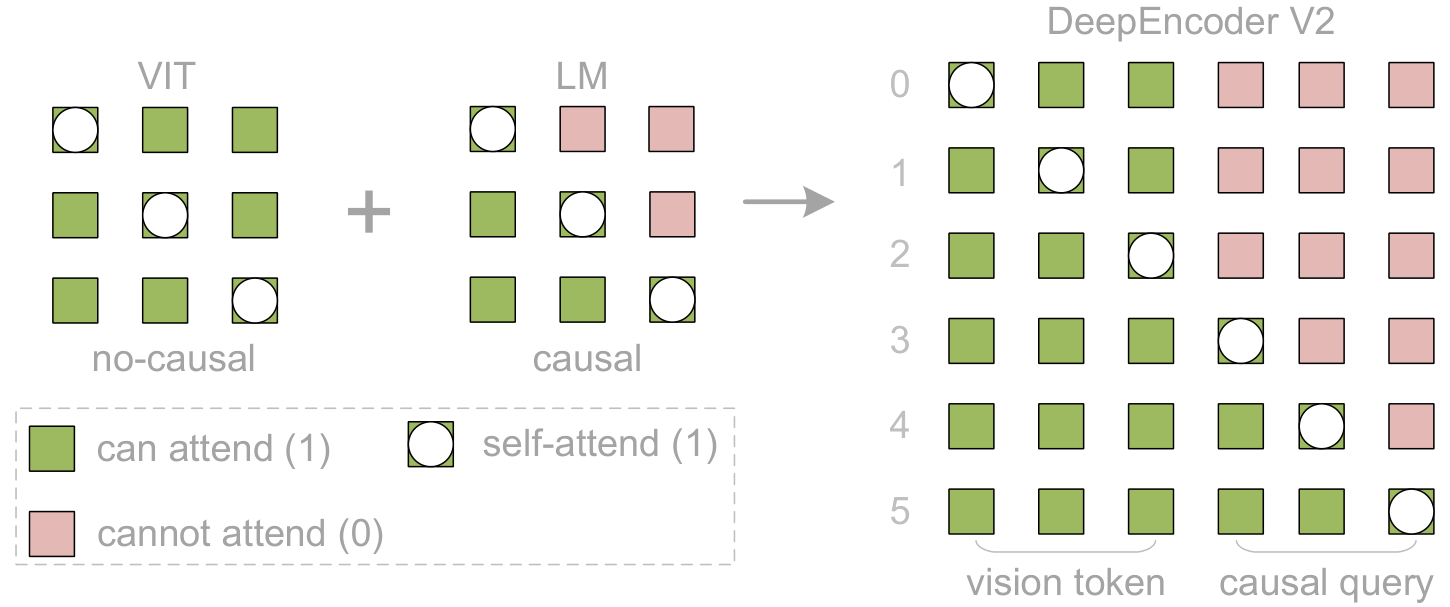 Attention Mask DesignVisual tokens maintain bidirectional attention for global context, while causal flow queries use triangular masking to progressively attend to all visual tokens and preceding queries.
Attention Mask DesignVisual tokens maintain bidirectional attention for global context, while causal flow queries use triangular masking to progressively attend to all visual tokens and preceding queries.
Only the causal query outputs - the latter half of the encoder sequence - are passed to the DeepSeek-3B MoE decoder (3B parameters, ~500M active). This creates a clean separation: the encoder handles visual reordering, the decoder handles content generation.
Benchmark Results
On OmniDocBench v1.5 [8], a comprehensive document parsing benchmark with 1,355 pages across 9 document types, DeepSeek-OCR 2 achieves 91.09% overall score - the best among end-to-end models.
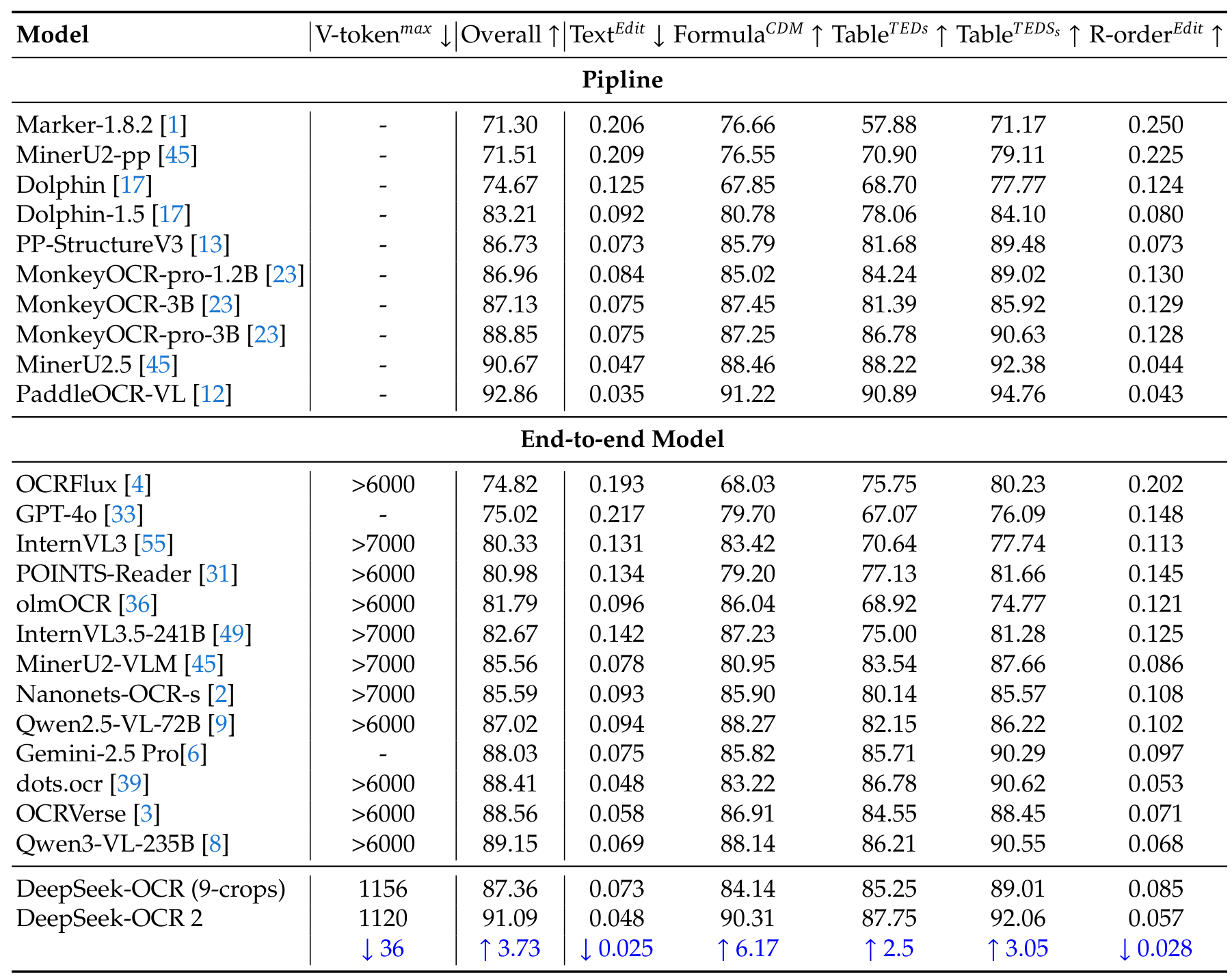 OmniDocBench ResultsComprehensive comparison showing DeepSeek-OCR 2 achieving 91.09% with only 1120 max visual tokens, outperforming models using 6000+ tokens.
OmniDocBench ResultsComprehensive comparison showing DeepSeek-OCR 2 achieving 91.09% with only 1120 max visual tokens, outperforming models using 6000+ tokens.
The efficiency gains are striking:
| Model | Max V-Tokens | Overall Score | |-------|-------------|---------------| | DeepSeek-OCR 2 | 1,120 | 91.09% | | Qwen2.5-VL-72B | >6,000 | 87.02% | | Gemini-2.5 Pro | - | 88.03% | | GPT-4o | - | 75.02% |
Beyond raw accuracy, the reading order metric improved significantly - Edit Distance dropped from 0.085 to 0.057, validating that visual causal flow genuinely learns better reading patterns. In production deployment, repetition rates decreased from 6.25% to 4.17% for online images and from 3.69% to 2.88% for PDF processing.
Research Context
This work builds directly on DeepSeek-OCR [1], which introduced the visual token compression mechanism and MoE decoder architecture. The causal flow query design draws inspiration from DETR's object queries [3] and BLIP-2's Q-former [2], which pioneered learnable queries for feature decoding and token compression.
What is genuinely new:
- Using an LLM architecture (decoder-only transformer) as a vision encoder, not just decoder
- Causal flow queries that dynamically reorder visual tokens based on semantic understanding
- The two-cascaded 1D reasoning paradigm for 2D image understanding
Compared to Qwen2.5-VL-72B [4], the strongest general VLM on this benchmark, DeepSeek-OCR 2 trades generality for extreme efficiency - ideal for document-heavy workloads where throughput matters. For general vision-language tasks requiring maximum capability over efficiency, larger general-purpose models remain preferable.
Open questions:
- Does the causal flow actually learn semantically meaningful reading patterns, or just better positional encodings?
- Can this architecture scale to longer sequences like multi-page documents or videos?
- How does performance degrade on non-document images where "reading order" may not apply?
Limitations
The approach shows weaknesses on newspaper documents (>0.13 Edit Distance) due to the lower visual token limit and insufficient training data for dense text layouts. The authors acknowledge that genuine 2D reasoning remains aspirational - current work provides initial validation, and achieving multi-hop visual reordering may require substantially longer causal flow sequences.
Resources
Check out the Paper, GitHub, and Model Weights. All credit goes to the researchers.
References
[1] Wei, H. et al. (2025). DeepSeek-OCR: Contexts Optical Compression. arXiv preprint. arXiv
[2] Li, J. et al. (2023). BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. ICML 2023. arXiv
[3] Carion, N. et al. (2020). End-to-End Object Detection with Transformers. ECCV 2020. arXiv
[4] Bai, S. et al. (2025). Qwen2.5-VL Technical Report. arXiv preprint. arXiv
[5] Wang, P. et al. (2024). Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution. arXiv preprint. arXiv
[6] Wei, H. et al. (2024). General OCR Theory: Towards OCR-2.0 via a Unified End-to-End Model. arXiv preprint. arXiv
[7] Radford, A. et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML 2021. arXiv
[8] Ouyang, L. et al. (2025). OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations. CVPR 2025. GitHub


