73% on BrowseComp: Meituan's 560B Open-Source Model Leads Agentic Benchmarks
Meituan's LongCat team has released the most capable open-source agentic reasoning model - trained on 10,000+ simulated environments to handle the messy reality of tool-use in production.
As reasoning models mature, the AI frontier is shifting toward agentic systems that can interact with tools, search the web, and execute multi-step tasks in real-world environments. Building on the reasoning-via-reinforcement-learning paradigm established by DeepSeek-R1 [1], Meituan's LongCat team has released LongCat-Flash-Thinking-2601, a 560-billion parameter Mixture-of-Experts model that achieves state-of-the-art performance on agentic benchmarks while remaining fully open-source.
Unlike DeepSeek-V3.2-Thinking [2] which achieves strong results through parameter scaling, LongCat introduces a fundamentally different approach: environment scaling. By training across 10,000+ simulated environments spanning 20+ domains, the model learns generalizable tool-use behaviors rather than benchmark-specific patterns. The result is a model that achieves 73.1% on BrowseComp (vs. DeepSeek's 67.6%) and 88.2% on tau2-Bench [4], while maintaining robustness to the noisy, imperfect conditions of real-world deployment.
The Environment Scaling Approach
Traditional agentic training relies on curated task sets with clean environments. LongCat takes a different path: automated environment construction that converts high-level domain specifications into executable tool graphs, each containing 60+ tools organized in dense dependency graphs.
The pipeline begins with domain definitions and synthesizes domain-specific tool sets, database schemas, and tool implementations. Each generated environment undergoes unit testing and debugging validation, achieving over 95% success rate in converting schema-level designs into fully executable tools. The resulting collection covers domains from airline booking to retail management to telecommunications.
To ensure environment complexity without breaking executability, LongCat employs verifiability-preserving expansion. Starting from a seed tool chain, BFS-style graph expansion adds new tools only when their dependencies are already satisfied by instantiated tools with properly constructed database states. This controlled growth maintains reliable supervision signals while progressively increasing task difficulty.
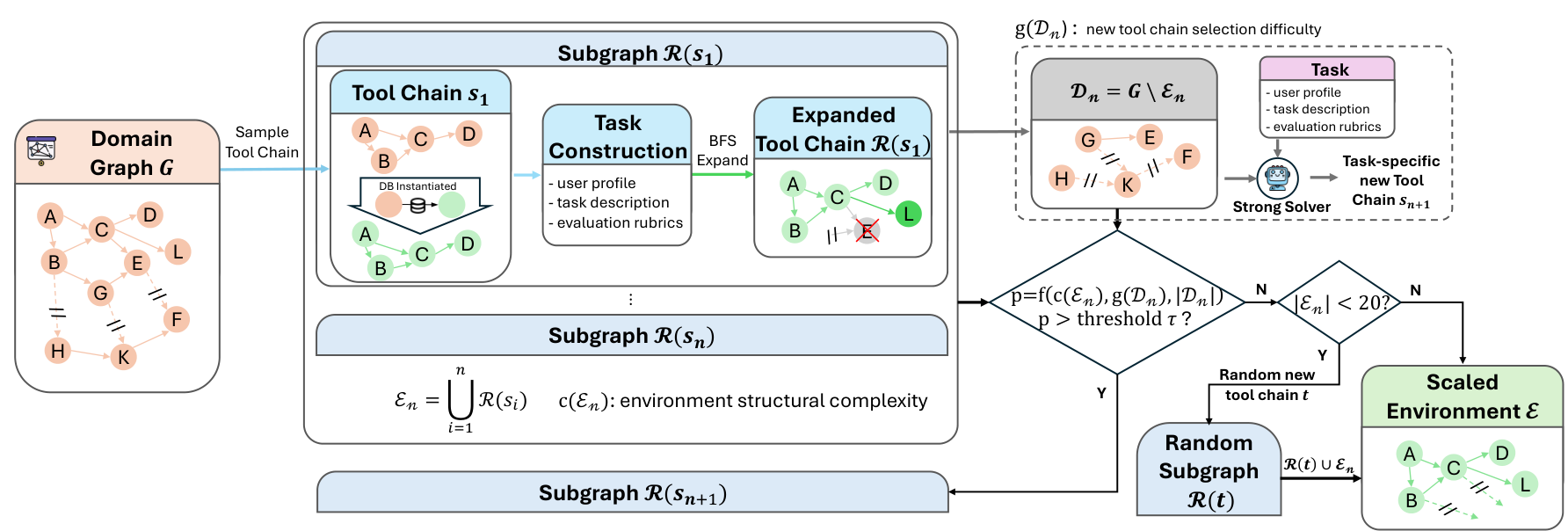 Environment PipelineAutomated construction of executable domain graphs, from domain specification through tool generation to dependency analysis.
Environment PipelineAutomated construction of executable domain graphs, from domain specification through tool generation to dependency analysis.
DORA: Async RL at Industrial Scale
Agentic reinforcement learning presents unique infrastructure challenges. Multi-turn interactions create long-tailed, latency-skewed trajectories, and environment heterogeneity causes workload imbalance across accelerators. LongCat addresses these through DORA (Dynamic ORchestration for Asynchronous Rollout), an extension of Meituan's asynchronous training system.
DORA decouples rollout and training into a producer-consumer architecture. The RolloutManager handles lightweight control metadata while multiple RolloutControllers manage virtual rollout groups in a data-parallel manner. Within each group, LLM generation, environment execution, and reward computation execute at individual sample granularity rather than waiting for batch barriers.
The system supports multi-version asynchronous training, where trajectories from different model versions are immediately enqueued upon completion. This eliminates the need for synchronization, achieving 2-4x speedup over synchronous training across production jobs. At scale, DORA sustains up to 32,000 environments executing concurrently across roughly 400 physical machines.
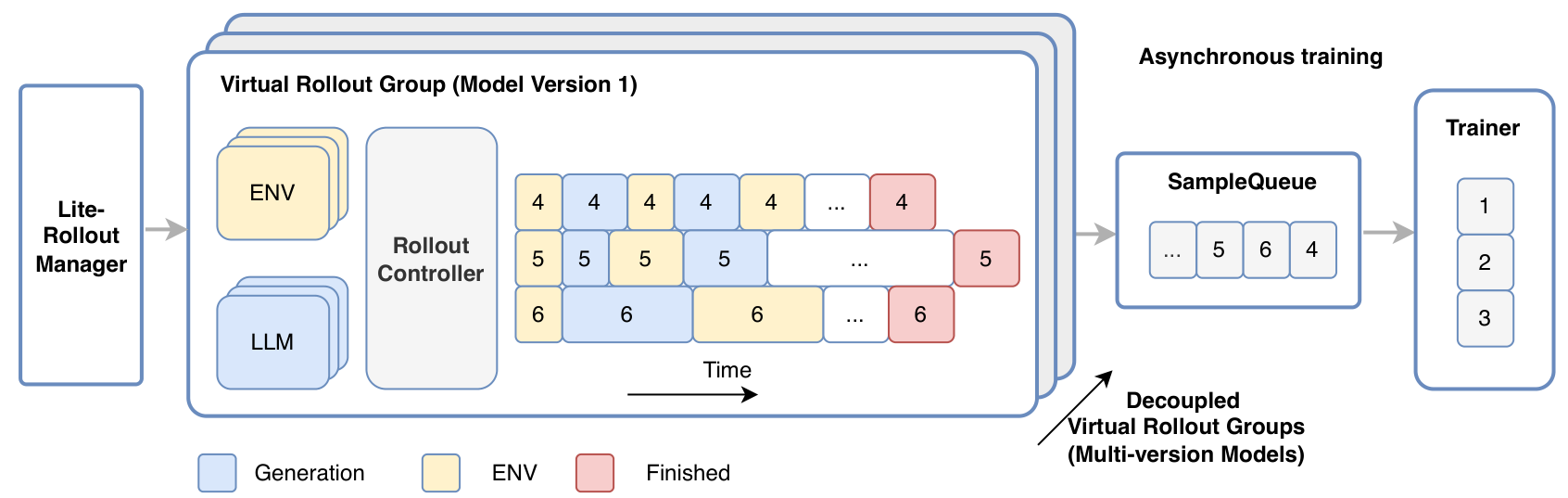 DORA ArchitectureExecution workflow showing the producer-consumer architecture with asynchronous rollout and multi-version model support.
DORA ArchitectureExecution workflow showing the producer-consumer architecture with asynchronous rollout and multi-version model support.
Robust Training for Real-World Deployment
A key insight driving LongCat's design is that real-world environments are inherently imperfect. Users exhibit diverse interaction styles, tools fail unpredictably, and responses contain noise. Rather than training on idealized conditions and hoping for post-hoc adaptation, LongCat explicitly incorporates environmental imperfections into the training process.
The approach models two major noise sources: instruction noise (ambiguity and variability in user interaction patterns) and tool noise (execution failures, inconsistent responses, partial results). A curriculum-based strategy progressively introduces these imperfections, starting from mild perturbations and increasing difficulty as the model demonstrates sufficient robustness.
The impact is significant. On tau2-Bench's noise-augmented variant, LongCat achieves 67.1% versus 65.0% for GPT-5.2-Thinking-xhigh and 57.3% for Claude-Opus-4.5-Thinking. On VitaBench-Noise, it reaches 20.5% compared to 20.8% for Gemini-3-Pro.
Heavy Thinking Mode: Test-Time Scaling
To push reasoning capability beyond existing limits, LongCat introduces Heavy Thinking mode, which jointly scales reasoning width and depth at inference time. Unlike simple majority voting or self-consistency approaches that merely count answer frequencies, Heavy Thinking performs reflective reasoning over diverse trajectories.
In the first stage, a thinking model generates responses in parallel, producing diverse reasoning trajectories that explore different solution paths. In the second stage, a summary model conducts reflective reasoning over these trajectories - synthesizing the intermediate reasoning steps and aggregating outcomes through actual analysis rather than simple answer counting. An additional RL stage specifically trains the summary phase to improve this aggregation quality.
With Heavy Thinking enabled, LongCat achieves perfect 100% on AIME-25 (matching Claude-Opus-4.5 and GPT-5.2) and 86.8% on IMO-AnswerBench, surpassing all evaluated models including Gemini-3-Pro's 86.7%.
Benchmark Results
LongCat-Flash-Thinking-2601 establishes new state-of-the-art performance among open-source models on agentic benchmarks while remaining competitive on traditional reasoning tasks.
On agentic search, the model achieves 73.1% on BrowseComp with context management (vs. 67.6% for DeepSeek-V3.2-Thinking) and 77.7% on BrowseComp-ZH (vs. 66.6% for GLM-4.7-Thinking). On RW Search, a challenging real-world search benchmark, it reaches 79.5%, second only to GPT-5.2-Thinking's 82.0%.
For agentic tool use, LongCat achieves 88.2% on tau2-Bench (vs. 80.6% for DeepSeek), 29.3% on VitaBench (open-source SOTA), and 35.8% on Random Complex Tasks with arbitrarily generated tools (SOTA across all evaluated models).
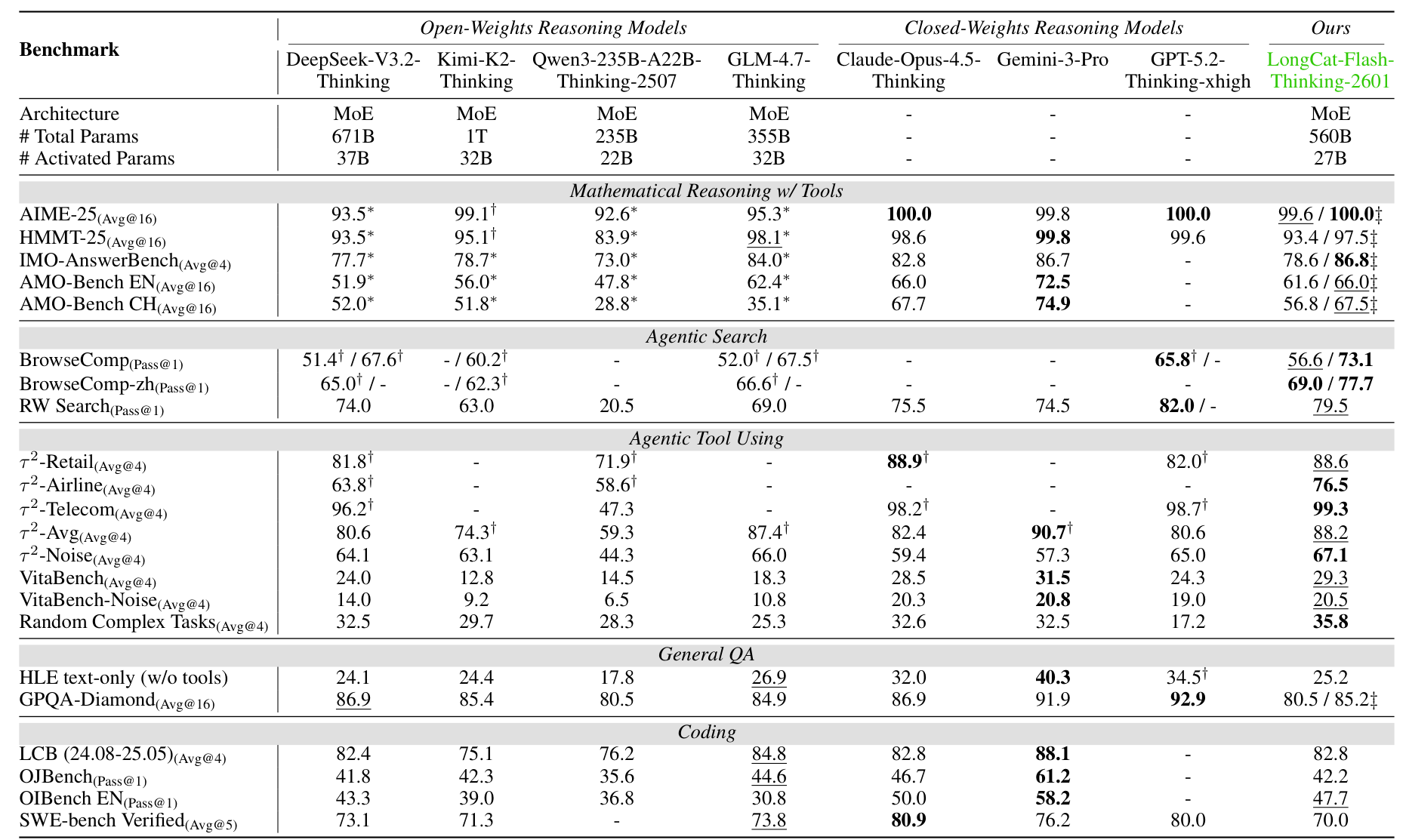 Main Results TableComprehensive benchmark comparison showing performance across Code, Math, Agentic Tool Use, Agentic Search, and General QA categories.
Main Results TableComprehensive benchmark comparison showing performance across Code, Math, Agentic Tool Use, Agentic Search, and General QA categories.
Research Context
This work builds directly on LongCat-Flash-Chat [6] for pre-training and the reasoning-via-RL paradigm from DeepSeek-R1 [1]. It extends Meituan's prior LongCat-Flash-Thinking work with environment scaling and robust training innovations.
What's genuinely new: The automated environment scaling pipeline converting domain specifications to executable 60+ tool graphs is unprecedented at this scale. Verifiability-preserving BFS expansion maintains database consistency as environments grow. The DORA system's 2-4x async speedup and curriculum-based noise injection for deployment robustness represent concrete infrastructure contributions.
Compared to DeepSeek-V3.2-Thinking [2], LongCat leads on agentic search and tool use but trails on general coding (SWE-bench 70.0% vs DeepSeek's 73.1% and closed-source leaders like Claude-Opus-4.5 at 80.9%). For practitioners needing agentic capabilities with noise robustness, LongCat is the open-source leader. For software engineering tasks, DeepSeek or closed-source alternatives may be preferable.
Open questions:
- How do the 10,000+ synthetic environments transfer to truly novel real-world domains?
- What is the compute cost overhead of Heavy Thinking mode vs accuracy gain?
- Can the environment scaling approach be applied to multimodal agentic tasks?
Check out the Paper, GitHub, and HuggingFace Model. All credit goes to the researchers.
References
[1] DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint. arXiv
[2] DeepSeek-AI et al. (2025). DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. arXiv preprint. arXiv
[3] MoonshotAI. (2025). Kimi-K2 Technical Report. Technical Report. Link
[4] Barres, V. et al. (2025). tau2-bench: Evaluating Conversational Agents in a Dual-Control Environment. arXiv preprint. arXiv
[5] Wei, J. et al. (2025). BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents. arXiv preprint. arXiv
[6] Meituan LongCat Team. (2025). LongCat-Flash Technical Report. arXiv preprint. arXiv
[7] Zheng, C. et al. (2025). Group Sequence Policy Optimization. arXiv preprint. arXiv


