When Should AI Agents Ask for Help? CMU's CowCorpus Maps Four Human Collaboration Styles
Your AI web agent keeps interrupting you to ask if it should click the button, or worse, it barrels ahead and books the wrong flight.
AI agents for web browsing are getting more capable by the month, with tools like Claude Computer Use, OpenAI's Operator, and open-source browser extensions all competing to automate everything from flight booking to job searching. But a fundamental UX problem remains unsolved: these agents either interrupt users constantly for confirmation or charge ahead making mistakes. Unlike frameworks like Magentic-UI [3] that design interaction mechanisms top-down, researchers at Carnegie Mellon University and Duke University have taken a data-driven approach, studying how humans actually collaborate with web agents to build models that predict the right moments to engage users.
Their work introduces CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4,200 interleaved human and agent actions. By analyzing these interaction traces, the team identified four distinct patterns of human-agent collaboration and trained models that improve intervention prediction accuracy by 61.4-63.4% over base language models. When deployed in a live Chrome extension called PlowPilot, these intervention-aware agents produced a 26.5% increase in user-rated usefulness.
The Problem: Agents Don't Know When to Ask
Current web agents operate on a spectrum between two extremes. Fully autonomous agents proceed without checking in, often making costly mistakes at critical decision points. Overly cautious agents request confirmation at every step, negating the benefit of automation. As Bansal et al. [9] have documented, this creates a heavy oversight burden that undermines trust and productivity.
The core issue is that agents lack a principled understanding of when and why humans intervene. The CMU team formalized this as a step-wise binary classification problem within a Partially Observable Markov Decision Process (POMDP). At each step, the agent observes the current webpage (screenshot and accessibility tree), considers its action history, and decides whether to proceed autonomously or ask the user.
CowCorpus: 400 Real Collaboration Sessions
Building on CowPilot [1], their earlier collaborative web navigation framework, the researchers recruited 20 participants to complete 20 web tasks each: 10 standardized tasks from the Mind2Web benchmark [2] spanning travel, shopping, and government services, plus 10 free-form tasks of the participant's own choosing.
The resulting dataset captures 2,748 agent action steps and 1,476 human action steps, with step-level annotations marking exactly when users paused, resumed, or overrode agent execution. Analysis revealed three core reasons users intervene: error correction (agent selects wrong element or gets stuck in loops), preference misalignment (agent ignores price constraints or ambiguous instructions), and assistive takeover (complex UI elements like captchas or dynamic layouts that agents cannot handle).
Four Types of Human-Agent Collaboration
Using four behavioral metrics -- intervention frequency, intervention intensity, normalized intervention position, and handback rate -- the team applied k-means clustering to identify four distinct collaboration styles.
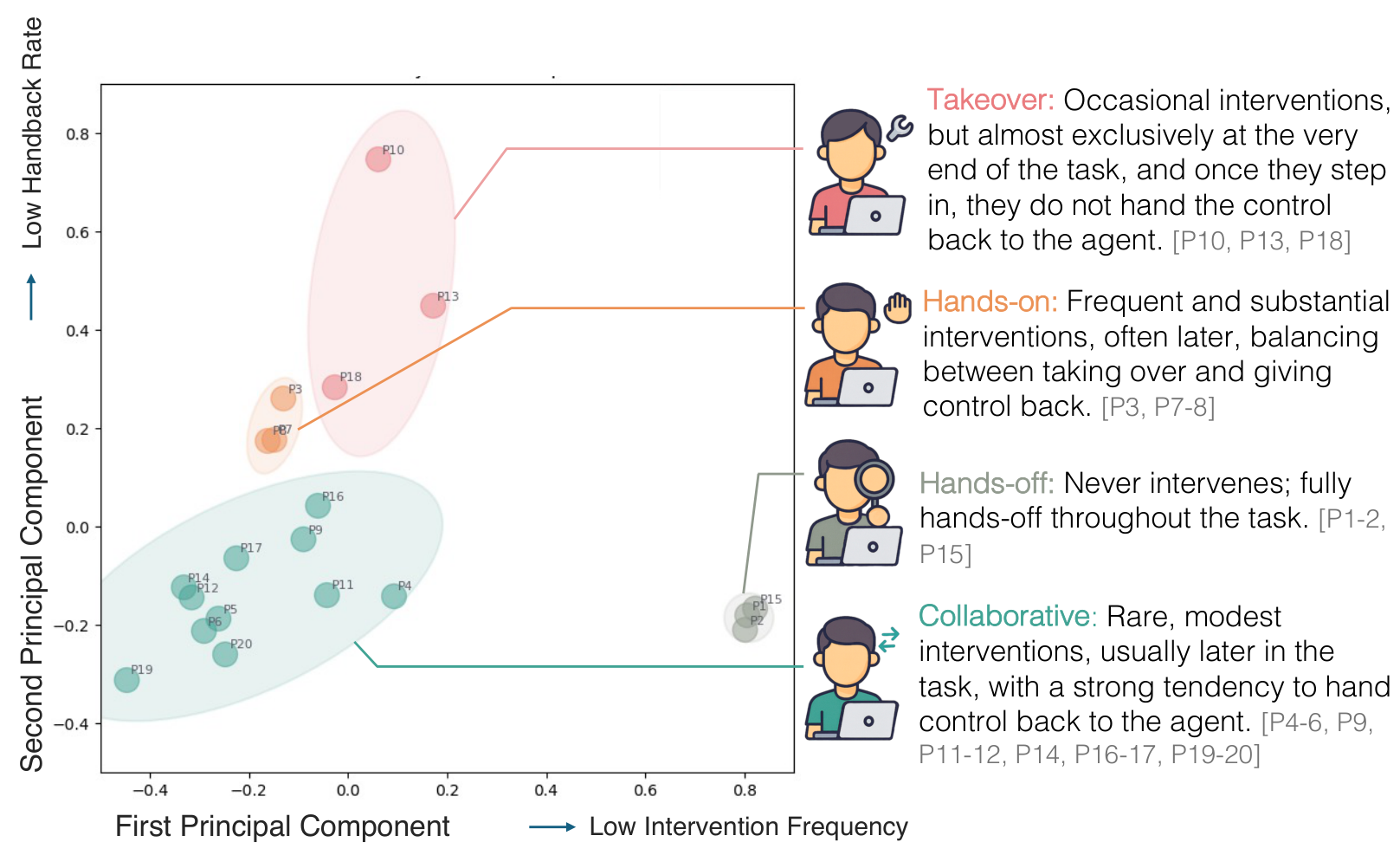 Collaboration PatternsPCA visualization of four user interaction clusters: Takeover, Hands-on, Hands-off, and Collaborative, showing how users differ in intervention frequency and control sharing behavior.
Collaboration PatternsPCA visualization of four user interaction clusters: Takeover, Hands-on, Hands-off, and Collaborative, showing how users differ in intervention frequency and control sharing behavior.
Hands-off users rarely intervene, letting the agent handle most tasks end-to-end. Collaborative users intervene selectively and consistently return control to the agent -- short, targeted corrections that keep the collaboration flowing. Hands-on users intervene frequently with high intensity, regularly alternating control with the agent. Takeover users intervene infrequently but when they do, they retain control and finish the task themselves rather than handing back.
These patterns proved consistent across tasks for individual users, suggesting that collaboration style is a stable user trait rather than task-dependent behavior.
Small Fine-Tuned Models Beat GPT-4o and Claude
The team trained intervention prediction models using supervised fine-tuning on CowCorpus interaction traces. They introduced the Perfect Timing Score (PTS), a metric that penalizes not just incorrect predictions but temporally misaligned ones -- predicting intervention too early incurs a penalty based on the squared distance from the actual intervention point.
Fine-tuned Gemma 27B achieved a PTS of 0.303, outperforming Claude 4 Sonnet (0.293), GPT-4o (0.147), and Gemini 2.5 Pro (0.262). Even the smaller LLaVA 8B, after fine-tuning, reached a PTS of 0.201, beating GPT-4o despite being a fraction of its size. Proprietary models, despite strong general reasoning, proved overly conservative -- they struggled to balance respecting user autonomy with proactive assistance.
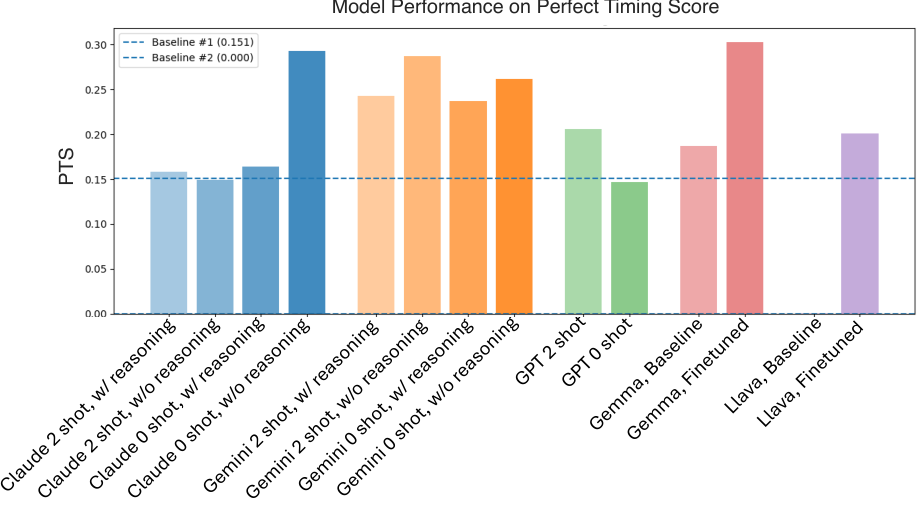 Benchmark ResultsPerfect Timing Score comparison showing fine-tuned open-weight models outperforming larger proprietary models on intervention prediction.
Benchmark ResultsPerfect Timing Score comparison showing fine-tuned open-weight models outperforming larger proprietary models on intervention prediction.
Style-conditioned models -- fine-tuned on data from specific user clusters -- outperformed general models when matched to the right user type, showing diagonal dominance in the cross-evaluation matrix. The one exception was the Takeover group, where the Hands-on model performed best, likely due to data sparsity: the Takeover cluster contained only 11 intervention steps compared to 37 for Hands-on.
PlowPilot: Intervention-Aware Agents in the Wild
To validate these findings beyond offline metrics, the team deployed their intervention prediction model in PlowPilot, a Chrome extension that wraps the CowPilot agent with an intervention-awareness layer. Rather than confirming with users at every step, PlowPilot prompts for input only when the model predicts a high likelihood of user intervention.
In a preliminary user study with 4 returning participants, PlowPilot achieved a 26.5% improvement in user-rated usefulness across six dimensions compared to the baseline CowPilot agent. Importantly, the underlying execution agent remained identical -- the improvement came entirely from better timing of when to engage the user.
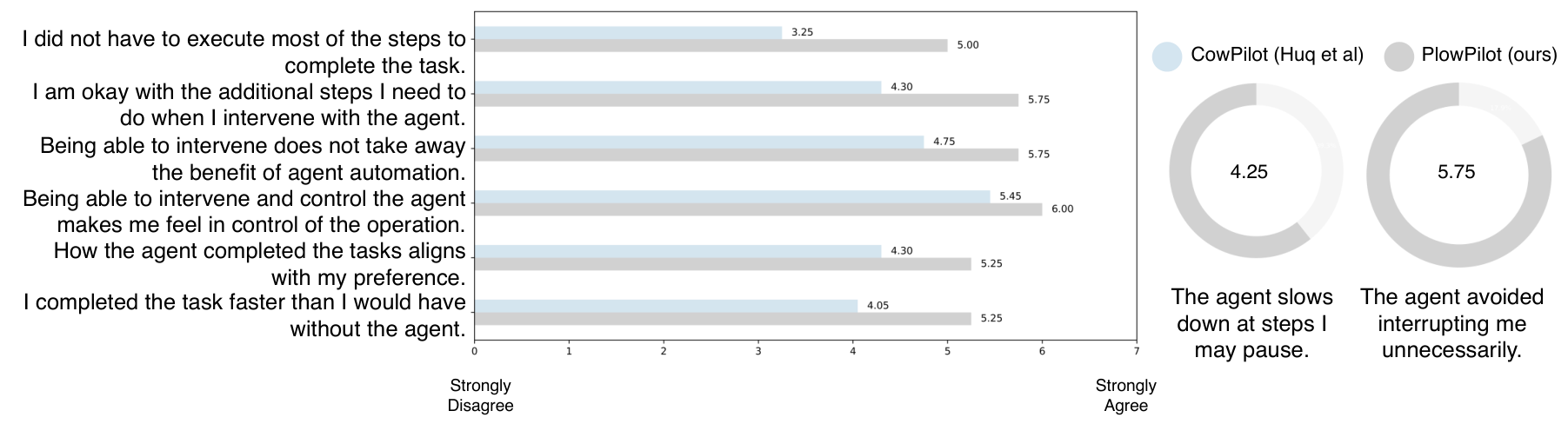 User Study ResultsLikert-scale comparison showing PlowPilot outperforms CowPilot across all six user satisfaction dimensions, with an average 26.5% improvement.
User Study ResultsLikert-scale comparison showing PlowPilot outperforms CowPilot across all six user satisfaction dimensions, with an average 26.5% improvement.
Research Context
This work builds on CowPilot [1], the same team's collaborative web navigation framework presented at NAACL 2025, and Mind2Web [2], the widely-used web agent benchmark that provided the standardized task distribution.
What's genuinely new: CowCorpus is the first dataset of real-user collaborative web navigation trajectories with step-level intervention annotations. The four-cluster taxonomy of collaboration styles provides an empirical foundation that previous frameworks lack. The PTS metric offers a more nuanced evaluation of intervention timing than standard binary classification metrics.
Compared to Magentic-UI [3] from Microsoft Research, which designs interaction mechanisms top-down (co-planning, action guards, co-tasking), CowCorpus models intervention patterns bottom-up from real user data. For scenarios requiring richer interaction modalities or broader tool support beyond web navigation, frameworks like Magentic-UI [3] or Collaborative Gym [4] may be more suitable.
Open questions: Do the four interaction patterns generalize beyond the 20 participants (aged 20-30) studied? How do collaboration styles evolve as users gain experience with an agent over weeks or months? The preliminary deployment study (n=4) provides encouraging results, but larger-scale validation is needed.
Check out the Paper, GitHub, and Models. All credit goes to the researchers.
References
[1] Huq, F. et al. (2025). CowPilot: A framework for autonomous and human-agent collaborative web navigation. NAACL 2025. Paper
[2] Deng, X. et al. (2024). Mind2Web: Towards a generalist agent for the web. NeurIPS 2024.
[3] Mozannar, H. et al. (2025). Magentic-UI: Towards human-in-the-loop agentic systems. arXiv preprint. arXiv
[4] Shao, Y. et al. (2025). Collaborative Gym: A framework for enabling and evaluating human-agent collaboration. arXiv preprint. arXiv
[5] Feng, K. et al. (2024). Cocoa: Co-planning and co-execution with AI agents. arXiv preprint. arXiv
[6] Hadfield-Menell, D. et al. (2016). Cooperative inverse reinforcement learning. NeurIPS 2016.
[7] Mitchell, M. et al. (2025). Fully autonomous AI agents should not be developed. arXiv preprint. arXiv
[8] Zhou, S. et al. (2023). WebArena: A realistic web environment for building autonomous agents. arXiv preprint.
[9] Bansal, G. et al. (2024). Challenges in human-agent communication. arXiv preprint.