90% Attention Sparsity with Zero Quality Loss: SALAD Speeds Up Video Diffusion 1.7x
Sparse attention alone can't hit 90% sparsity without breaking video quality - SALAD adds a lightweight linear attention branch as a safety net.
Video generation has emerged as one of the most computationally demanding tasks in AI. Models like Wan, Sora, and Kling can produce stunning results, but the quadratic complexity of attention mechanisms creates a significant bottleneck when processing the thousands of tokens in a typical video sequence. Training-free sparse attention methods have offered some relief, but they plateau at around 40-60% sparsity before quality degrades noticeably.
Researchers from Tsinghua University and Kuaishou Technology (the team behind the Kling video generation service) have developed SALAD (High-Sparsity Attention paralleling with Linear Attention for Diffusion Transformer), a method that achieves 90% sparsity while actually improving generation quality compared to full attention. The key insight: sparse attention alone loses critical cross-token information, but a lightweight linear attention branch can compensate for this loss with minimal computational overhead.
The Sparsity Ceiling Problem
Prior work on efficient video diffusion has taken two main approaches. Training-free methods like SVG2 [5] and PAROAttention use clever masking patterns to skip attention computations, achieving 45-56% sparsity with minimal quality loss. Training-based approaches like VMoBA [3] can reach 80-95% sparsity but require massive computational resources - VMoBA needs approximately 182 GPU hours training on 36 million video clips.
The fundamental challenge is that ultra-sparse attention (above 80%) restricts cross-token interactions so severely that even LoRA fine-tuning [2] cannot fully recover the lost information. As shown in the paper's analysis, videos generated with 90% sparse attention plus LoRA tuning still exhibit artifacts like object duplication and temporal inconsistencies that stem from the intrinsic limitations of sparse attention.
How SALAD Works
SALAD introduces a parallel linear attention branch that runs alongside sparse attention. While sparse attention handles the majority of sequence modeling with restricted token interactions, the linear attention branch provides global context through O(N) complexity operations.
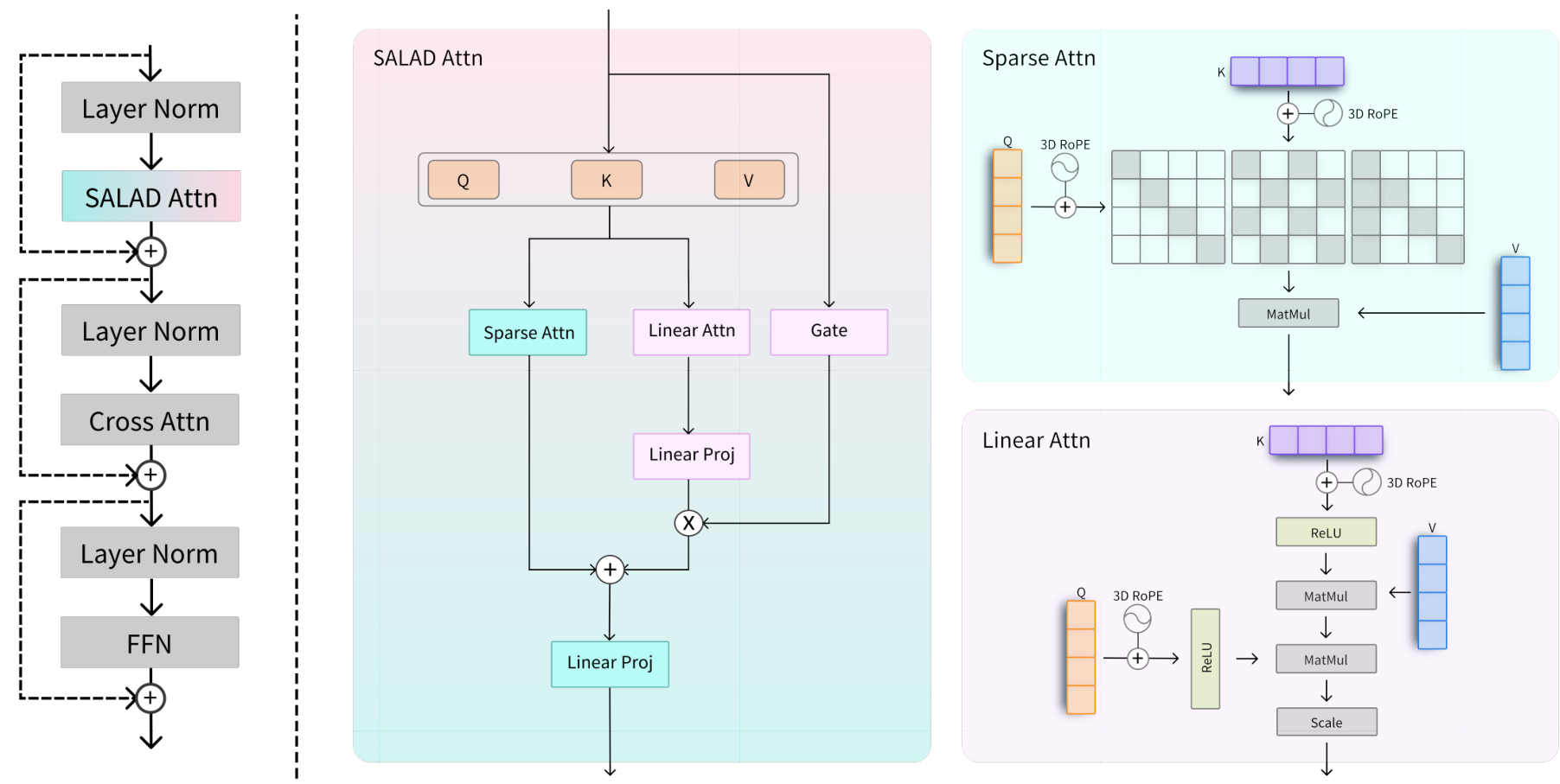 SALAD ArchitectureThe SALAD attention module shows parallel sparse and linear attention branches with shared Q/K/V projections and an input-dependent gating mechanism.
SALAD ArchitectureThe SALAD attention module shows parallel sparse and linear attention branches with shared Q/K/V projections and an input-dependent gating mechanism.
The architecture consists of four key components:
Shared Projections: Both branches use the same Query, Key, and Value projections, minimizing parameter overhead. Only about 4.99% additional parameters are introduced beyond the pretrained model.
ReLU-Based Linear Attention: The linear branch uses ReLU activation to approximate attention weights, enabling associative reordering that reduces complexity from O(N^2) to O(Nd^2). Critically, SALAD integrates 3D Rotary Position Embeddings (3D RoPE) into the linear attention branch to handle spatial-temporal relationships in video sequences.
Input-Dependent Scalar Gate: Rather than using a fixed hyperparameter to balance the branches, SALAD learns a gate function that dynamically adjusts the linear attention contribution based on input content. The input hidden states pass through a linear layer and sigmoid activation, then are averaged across tokens to produce a scalar gate value.
Zero-Initialized Projection: The projection layer after the linear attention branch uses zero initialization, enabling training to start from the vanilla sparse attention model and gradually incorporate the linear branch's contribution.
The Gating Mechanism
The gate design is crucial to SALAD's performance. The authors observed that the linear attention branch has significantly lower rank than sparse attention (average rank of 6.17 vs 1171.7), indicating it captures different, complementary information rather than duplicating the sparse branch's work.
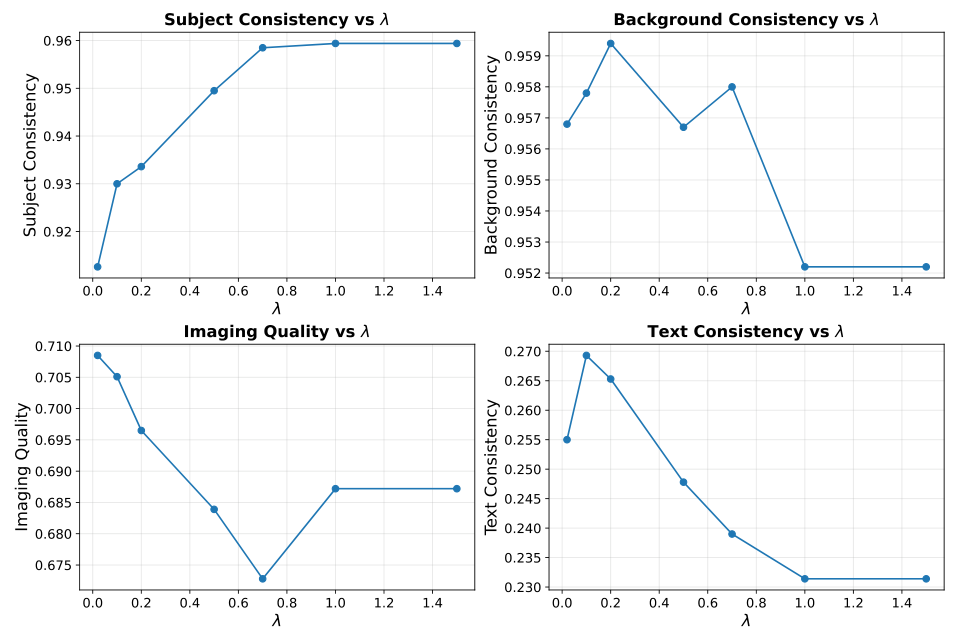 Gate EffectsEffect of different gate scaling values on video quality metrics - values between 0.5-1.0 provide optimal balance.
Gate EffectsEffect of different gate scaling values on video quality metrics - values between 0.5-1.0 provide optimal balance.
Experiments with fixed gate values show that the contribution of linear attention must be carefully constrained. When the gate is set to 0 (LoRA only), the model produces severe color distortions. At 1.5, the model fails to generate meaningful outputs. The learned input-dependent gate typically ranges between 0.1 and 0.4, allowing the model to adaptively balance global context injection across different layers and content types.
Benchmark Results
Testing on the Wan2.1-1.3B model at 480p resolution with 77 frames, SALAD with spatial-temporal sliding window attention achieves:
| Metric | SALAD | Full Attention | |--------|-------|----------------| | Sparsity | 90% | 0% | | Speedup | 1.72x | - | | Subject Consistency | 96.54 | 95.88 | | Background Consistency | 96.37 | 96.17 | | Image Quality | 66.09 | 65.93 | | Text Consistency | 25.55 | 25.31 |
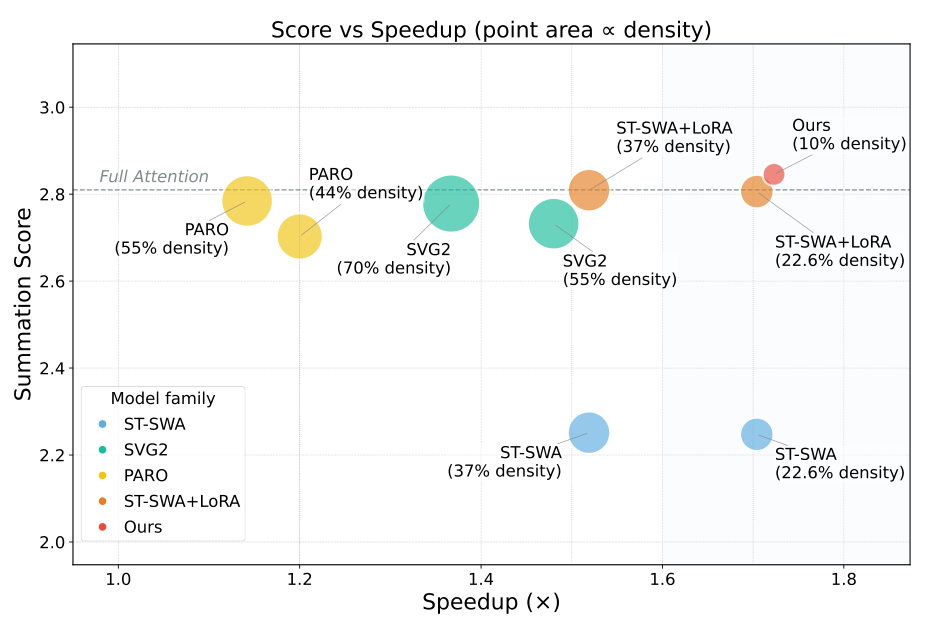 Results ComparisonSALAD achieves the best quality-efficiency trade-off, with smallest point size indicating lowest computational density.
Results ComparisonSALAD achieves the best quality-efficiency trade-off, with smallest point size indicating lowest computational density.
The VBench scores indicate that SALAD not only maintains but slightly exceeds full attention quality across all metrics - a counter-intuitive result that the authors attribute to the regularization effect of combining sparse and linear attention.
Training Efficiency
Perhaps the most practical advantage of SALAD is its training efficiency. While SLA [4], a similar sparse-linear attention approach, requires 20,000 videos and a batch size of 64, SALAD achieves comparable results with:
- 2,000 open-source video samples (from Mixkit)
- 1,600 training steps with batch size 8
- Approximately 20.6 GPU hours total
This makes SALAD accessible to academic researchers and smaller teams who cannot afford the 182 GPU hours and 36 million video dataset that VMoBA [3] requires.
Research Context
This work builds on DiTFastAttn [1], which introduced attention compression for diffusion transformers through headwise sliding-window patterns, and LoRA [2], which provides parameter-efficient fine-tuning for the attention projection matrices.
What's genuinely new: The input-dependent scalar gating mechanism that dynamically balances sparse and linear attention based on content; the zero-initialization strategy that enables stable training from a sparse baseline; and demonstrating that 90% sparsity can actually improve quality with only 2,000 training videos.
Compared to SLA [4], the most similar approach that classifies attention weights into critical/marginal/negligible categories, SALAD achieves comparable results with 10x less training data. For scenarios requiring no training overhead, training-free methods like SVG2 [5] may be preferable despite their lower sparsity ceiling.
Open questions:
- Why does the linear attention branch learn such low rank (average 6.17)? Is this a fundamental limitation or a training artifact?
- Can the approach transfer to other video diffusion architectures like CogVideoX or HunyuanVideo?
- How does performance scale to higher resolutions and longer video sequences?
Limitations
The evaluation is conducted on a single model (Wan2.1-1.3B) at fixed resolution (480p) and duration (77 frames). Generalization to other architectures and scaling to higher resolutions remains to be validated. The training data (Mixkit) is also smaller and less diverse than datasets used by competitors.
Check out the Paper. All credit goes to the researchers.
References
[1] Yuan, Z. et al. (2024). DiTFastAttn: Attention Compression for Diffusion Transformer Models. NeurIPS 2024. arXiv
[2] Hu, E. et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022. arXiv
[3] Wu, J. et al. (2025). VMoBA: Mixture-of-Block Attention for Video Diffusion Models. arXiv preprint. arXiv
[4] Zhang, J. et al. (2025). SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention. arXiv preprint. arXiv
[5] Yang, S. et al. (2025). Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation. arXiv preprint. arXiv


