97ms First-Packet Latency: Qwen3-TTS Beats ElevenLabs in Voice Cloning Across 10 Languages
Alibaba's Qwen team has released a 10-model family of text-to-speech systems that achieve 97ms first-packet latency and beat commercial competitors like ElevenLabs and GPT-4o in voice cloning quality, all under Apache 2.0.
Text-to-speech technology has advanced rapidly, with systems like CosyVoice [1, 2] and Seed-TTS [4] demonstrating that autoregressive language models can produce high-fidelity speech from just seconds of reference audio. Yet most open-source TTS systems still lag behind commercial offerings in at least one critical dimension: latency, multilingual coverage, voice control, or long-form stability. The Qwen team at Alibaba has now released Qwen3-TTS, a family of 10 open-source models that simultaneously addresses all of these challenges, achieving state-of-the-art performance across multiple benchmarks while delivering first-packet latency as low as 97 milliseconds.
Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS introduces a novel dual-tokenizer architecture that lets developers choose between semantic richness and ultra-low latency depending on their deployment needs. The entire model family is released under Apache 2.0, making it one of the most comprehensive open-source TTS releases from a major research lab.
The Dual-Tokenizer Architecture
At the core of Qwen3-TTS is a design choice that distinguishes it from competing approaches: two complementary speech tokenizers optimized for different deployment scenarios.
Qwen-TTS-Tokenizer-25Hz is a single-codebook tokenizer built upon the Qwen2-Audio encoder [9]. It produces 25 tokens per second of speech, emphasizing semantic content through a two-stage training process. First, it continues pretraining Qwen2-Audio on ASR tasks with vector quantization, then fine-tunes with mel-spectrogram reconstruction to inject acoustic detail. Waveform synthesis uses a block-wise Diffusion Transformer (DiT) with flow matching, requiring a 16-token lookahead before producing the first audio chunk.
Qwen-TTS-Tokenizer-12Hz operates at just 12.5 tokens per second using a 16-layer multi-codebook design inspired by Mimi [3]. The first codebook captures semantic content guided by WavLM [10], while 15 residual layers encode acoustic detail through progressive vector quantization. A lightweight causal ConvNet decoder reconstructs waveforms without any lookahead requirement, enabling immediate audio emission from the first available token. On the LibriSpeech test-clean benchmark, this tokenizer achieves state-of-the-art reconstruction quality with PESQ of 3.21 and speaker similarity of 0.95, surpassing all prior semantic-aware codecs including Mimi (2.88 PESQ, 0.87 SIM).
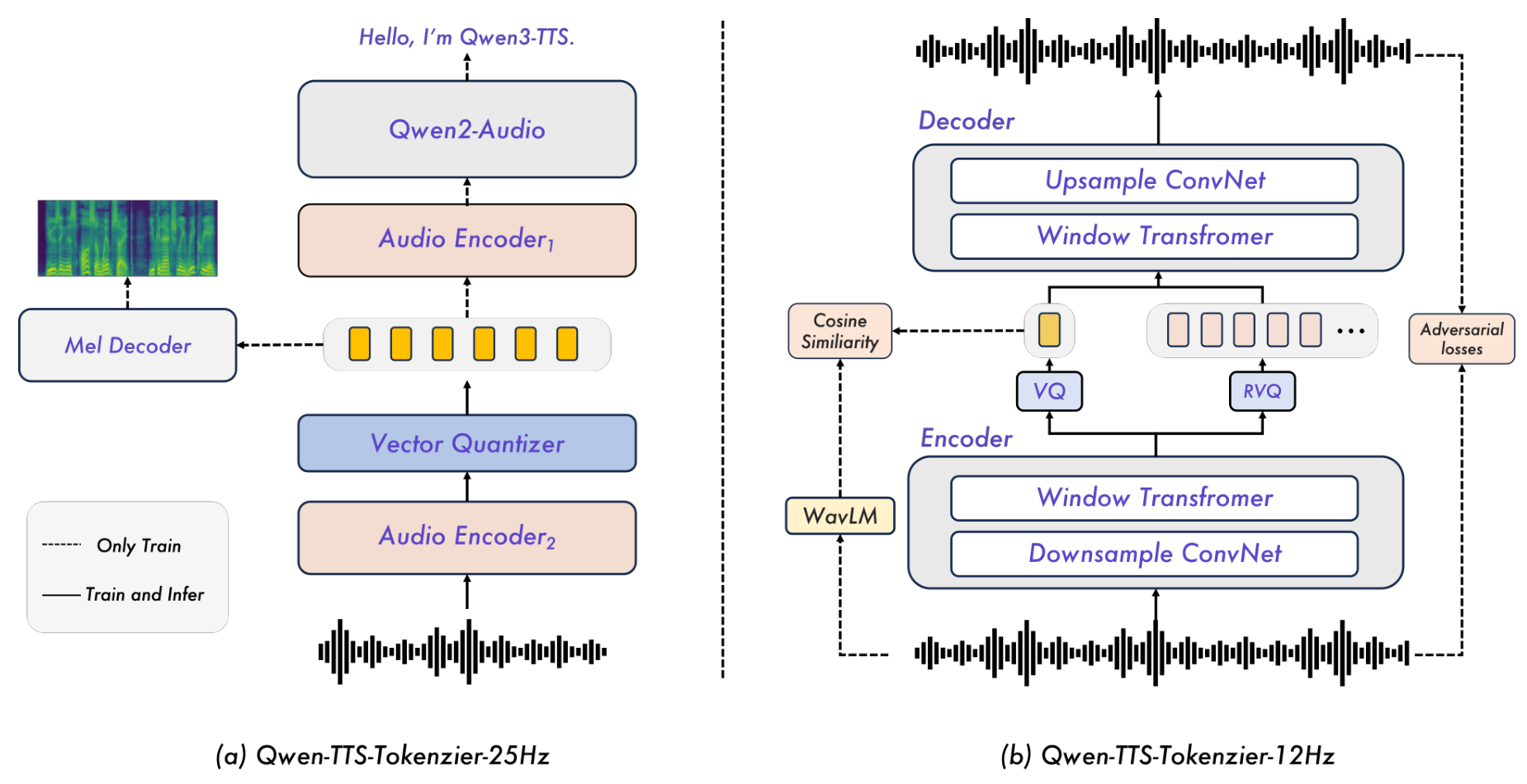 Tokenizer ArchitectureThe two complementary tokenizer designs: Qwen-TTS-Tokenizer-25Hz (left) uses Qwen2-Audio with a mel decoder, while Qwen-TTS-Tokenizer-12Hz (right) uses a causal encoder-decoder with semantic-acoustic disentanglement.
Tokenizer ArchitectureThe two complementary tokenizer designs: Qwen-TTS-Tokenizer-25Hz (left) uses Qwen2-Audio with a mel decoder, while Qwen-TTS-Tokenizer-12Hz (right) uses a causal encoder-decoder with semantic-acoustic disentanglement.
Streaming with Dual-Track Language Modeling
The generation backbone leverages the Qwen3 LM family with a dual-track representation: text tokens and acoustic tokens are concatenated along the channel axis. Upon receiving each text token, the model immediately predicts the corresponding acoustic token. For the 12Hz variant, a Multi-Token Prediction (MTP) module generates all 16 codebook layers from a single backbone pass, minimizing latency while capturing fine acoustic detail.
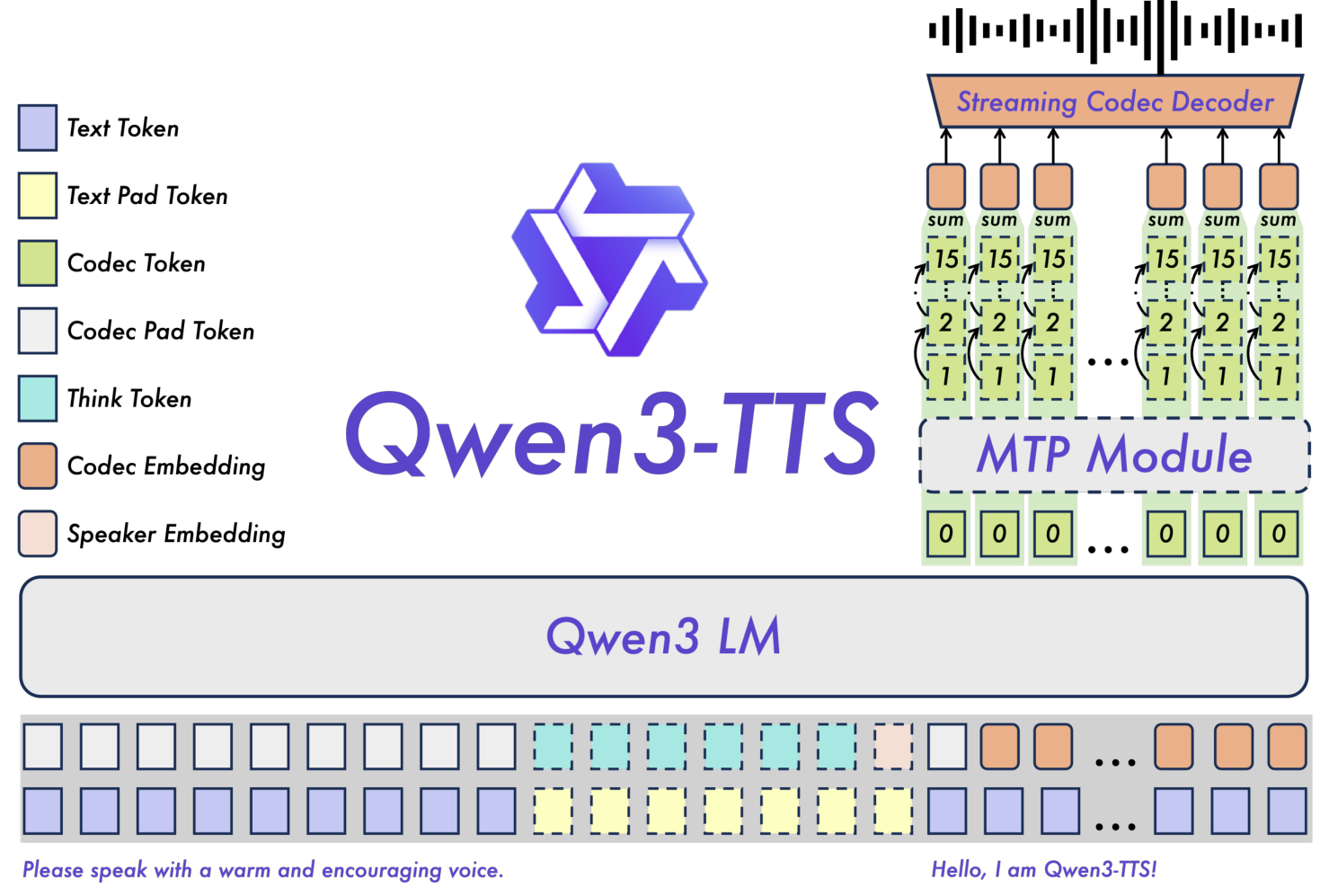 System OverviewThe complete Qwen3-TTS architecture showing dual-track token representation, Qwen3 LM backbone, MTP module for multi-codebook prediction, and streaming codec decoder.
System OverviewThe complete Qwen3-TTS architecture showing dual-track token representation, Qwen3 LM backbone, MTP module for multi-codebook prediction, and streaming codec decoder.
The result is striking streaming performance: the 12Hz-0.6B variant achieves 97ms first-packet latency at concurrency 1, compared to 138ms for the 25Hz-0.6B variant. Even under 6x concurrency load, the 12Hz models maintain 299ms latency with a real-time factor (RTF) of just 0.434, meaning the system generates audio more than twice as fast as real-time playback speed.
Benchmark Results
Qwen3-TTS establishes state-of-the-art across multiple evaluation dimensions.
Zero-Shot Voice Cloning: On the Seed-TTS benchmark [4], Qwen3-TTS-12Hz-1.7B achieves a Word Error Rate of 1.24 on English, surpassing CosyVoice 3 [2] (1.45), MiniMax-Speech [5] (1.65), and Seed-TTS (2.25). The 12Hz variants consistently outperform their 25Hz counterparts, suggesting that coarser temporal resolution helps autoregressive models better capture long-term dependencies.
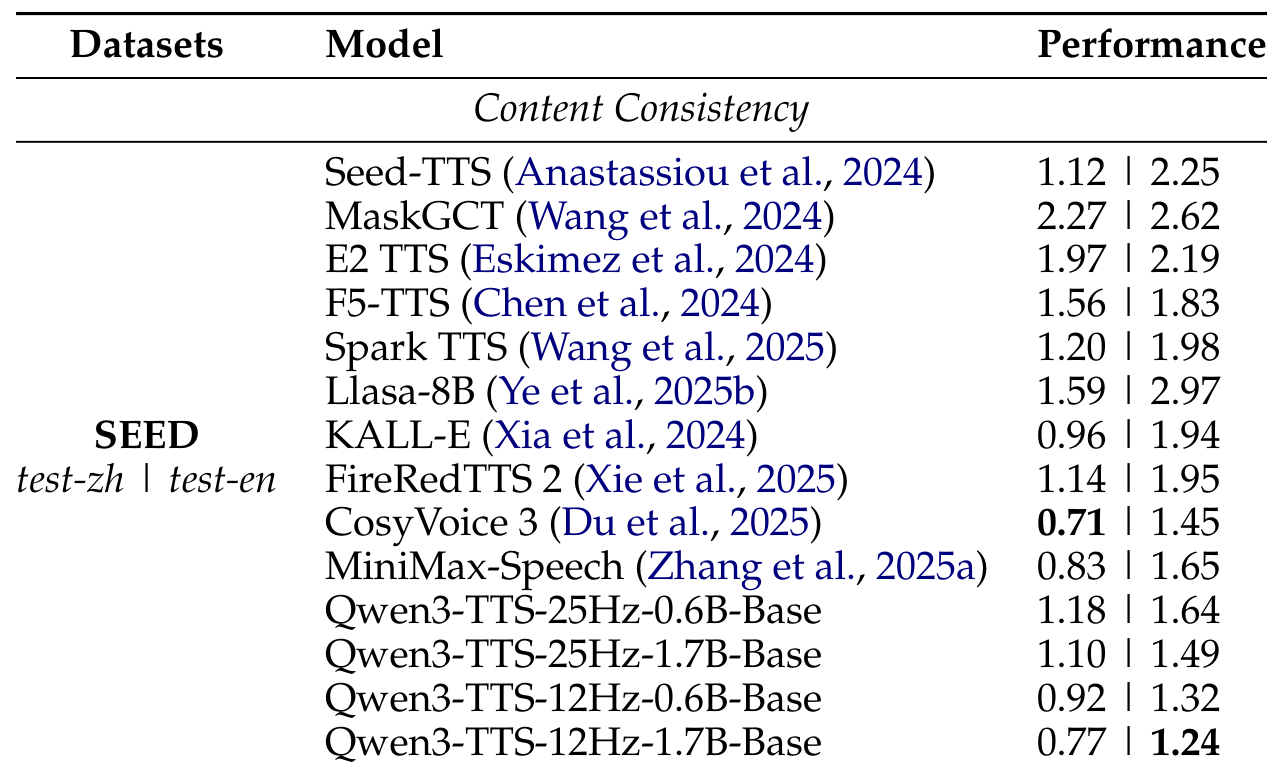 Zero-Shot ResultsComparison of Word Error Rate across zero-shot TTS systems on the Seed-TTS benchmark, showing Qwen3-TTS-12Hz-1.7B achieving best English performance at 1.24 WER.
Zero-Shot ResultsComparison of Word Error Rate across zero-shot TTS systems on the Seed-TTS benchmark, showing Qwen3-TTS-12Hz-1.7B achieving best English performance at 1.24 WER.
Multilingual Quality: Across 10 languages, Qwen3-TTS achieves the highest speaker similarity scores in every language tested, outperforming both MiniMax-Speech and ElevenLabs. It also achieves the lowest WER in 6 of 10 languages including Chinese, English, Italian, French, Korean, and Russian.
Cross-Lingual Transfer: In Chinese-to-Korean voice cloning, Qwen3-TTS reduces the error rate by 66% compared to CosyVoice 3 (4.82 vs 14.4), demonstrating exceptional cross-lingual generalization.
Controllable Generation: On InstructTTSEval, the 12Hz-1.7B Voice Design variant achieves an Attribute Perception and Synthesis (APS) score of 85.2 in Chinese, establishing a new open-source state-of-the-art. On target speaker manipulation tasks, Qwen3-TTS achieves an APS of 83.0 compared to GPT-4o-mini-tts at 54.9, a gain of over 28 absolute points.
Long-Form Stability: The system synthesizes over 10 minutes of continuous speech with WER of 1.517 (Chinese) and 1.225 (English), compared to 5.505/6.917 for Higgs-Audio-v2 and 22.619/1.780 for VibeVoice.
Training at Scale
The training pipeline consists of three pre-training stages followed by post-training alignment:
- General Stage (S1): Over 5 million hours of multilingual speech data establish a monotonic mapping from text to speech across 10 languages.
- High-Quality Stage (S2): Continual pre-training on curated high-quality data to reduce hallucinations from noisy training data.
- Long-Context Stage (S3): Maximum token length extended from 8,192 to 32,768 with upsampled long speech data.
Post-training applies Direct Preference Optimization (DPO) with human feedback to align outputs with human preferences, followed by Generalized Sequence Preference Optimization (GSPO) with rule-based rewards for stability across tasks, and lightweight speaker fine-tuning for adopting specific voices. A probabilistically activated thinking pattern during training improves instruction following for complex voice descriptions.
Research Context
This work builds on the supervised semantic token approach from CosyVoice [1] and the semantic-acoustic disentangled quantization from Moshi/Mimi [3], combining them with Qwen's language model infrastructure [9].
What is genuinely new: The dual-tokenizer design offering complementary latency-quality tradeoffs within a single framework, the dual-track LM architecture for true streaming synthesis, and the MTP module for efficient multi-codebook generation are the primary innovations. The scale (5M hours, 10 languages, 10 model variants under Apache 2.0) is also unprecedented for an open-source TTS release.
Compared to the strongest competitor CosyVoice 3 [2], Qwen3-TTS trades marginally higher Chinese WER (0.77 vs 0.71) for substantially better English performance (1.24 vs 1.45), superior cross-lingual capabilities, and the ultra-low-latency 12Hz streaming option that CosyVoice lacks.
Open questions remain around perceptual quality (no MOS evaluations are reported), robustness with shorter reference audio or noisy environments, and the computational requirements for training at this data scale.
Check out the Paper and GitHub repo. All credit goes to the researchers.
References
[1] Du, Z. et al. (2024). CosyVoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint. arXiv
[2] Du, Z. et al. (2025). CosyVoice 3: Towards in-the-wild speech generation via scaling-up and post-training. arXiv preprint. arXiv
[3] Defossez, A. et al. (2024). Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint. arXiv
[4] Anastassiou, P. et al. (2024). Seed-TTS: A family of high-quality versatile speech generation models. arXiv preprint. arXiv
[5] Zhang, B. et al. (2025). MiniMax-Speech: Intrinsic zero-shot text-to-speech with a learnable speaker encoder. arXiv preprint. arXiv
[6] Wang, C. et al. (2023). Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint. arXiv
[7] Chen, Y. et al. (2024). F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. arXiv preprint. arXiv
[8] Defossez, A. et al. (2022). High fidelity neural audio compression. arXiv preprint. arXiv
[9] Xu, J. et al. (2025). Qwen2.5-Omni Technical Report. arXiv preprint. arXiv
[10] Chen, S. et al. (2022). WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. arXiv


