Agent Memory Fragmentation Solved: EverMemOS Achieves 93% on LoCoMo via Engram-Inspired Lifecycle
Current memory systems for AI agents fail not because they lose information, but because they never organize it.
As LLMs evolve from stateless chat interfaces into persistent agents managing months of user interactions, a fundamental problem emerges: these systems remember facts but fail to organize experiences into coherent knowledge. Unlike approaches such as Zep [1] that maintain temporal knowledge graphs or Mem0 [3] that extract structured facts, a new system called EverMemOS tackles the root cause -- the absence of a mechanism to consolidate fragmented episodes into stable semantic structures.
Researchers from EverMind and Shanda Group introduce EverMemOS, a self-organizing Memory Operating System that models agent memory as a biological engram-inspired lifecycle. The system achieves 93.05% accuracy on LoCoMo and 83.00% on LongMemEval, representing relative improvements of 9.2% and 6.7% over the strongest baselines -- with particularly dramatic gains on multi-hop reasoning (+12.1%) and temporal questions (+16.1%).
The Three-Phase Memory Lifecycle
EverMemOS is structured around three phases inspired by how biological memory systems encode, consolidate, and reconstruct experiences [8].
Phase I: Episodic Trace Formation converts the unbounded stream of dialogue into discrete memory primitives called MemCells. A Semantic Boundary Detector identifies topic shifts via sliding window, creating raw episode histories. These are synthesized into concise third-person narratives (Episodes), from which Atomic Facts are extracted for precision matching. Crucially, the system also generates time-bounded Foresight signals -- forward-looking inferences annotated with validity intervals that distinguish temporary states (like taking antibiotics for two weeks) from permanent changes (like graduating).
Phase II: Semantic Consolidation organizes MemCells into higher-order thematic clusters called MemScenes. When a new MemCell arrives, the system computes its embedding and compares it against existing MemScene centroids. If similarity exceeds a threshold, the MemCell is assimilated; otherwise, a new MemScene is instantiated. This online clustering maintains thematic structure without batch reprocessing. Scene-level summaries also drive a User Profile that separates stable traits from temporary states.
Phase III: Reconstructive Recollection performs retrieval as active reconstruction rather than static lookup. Given a query, the system fuses dense and BM25 retrieval via Reciprocal Rank Fusion, scores MemScenes by constituent relevance, and selects the top 10. Within selected scenes, episodes are re-ranked and time-expired Foresight is filtered out. An LLM-based sufficiency verifier then evaluates whether the retrieved context is adequate -- if insufficient, the system generates 2-3 complementary follow-up queries targeting the missing information. This verification-and-rewriting loop fires for approximately 31% of queries on LoCoMo, ensuring the final context is both necessary and sufficient for downstream reasoning.
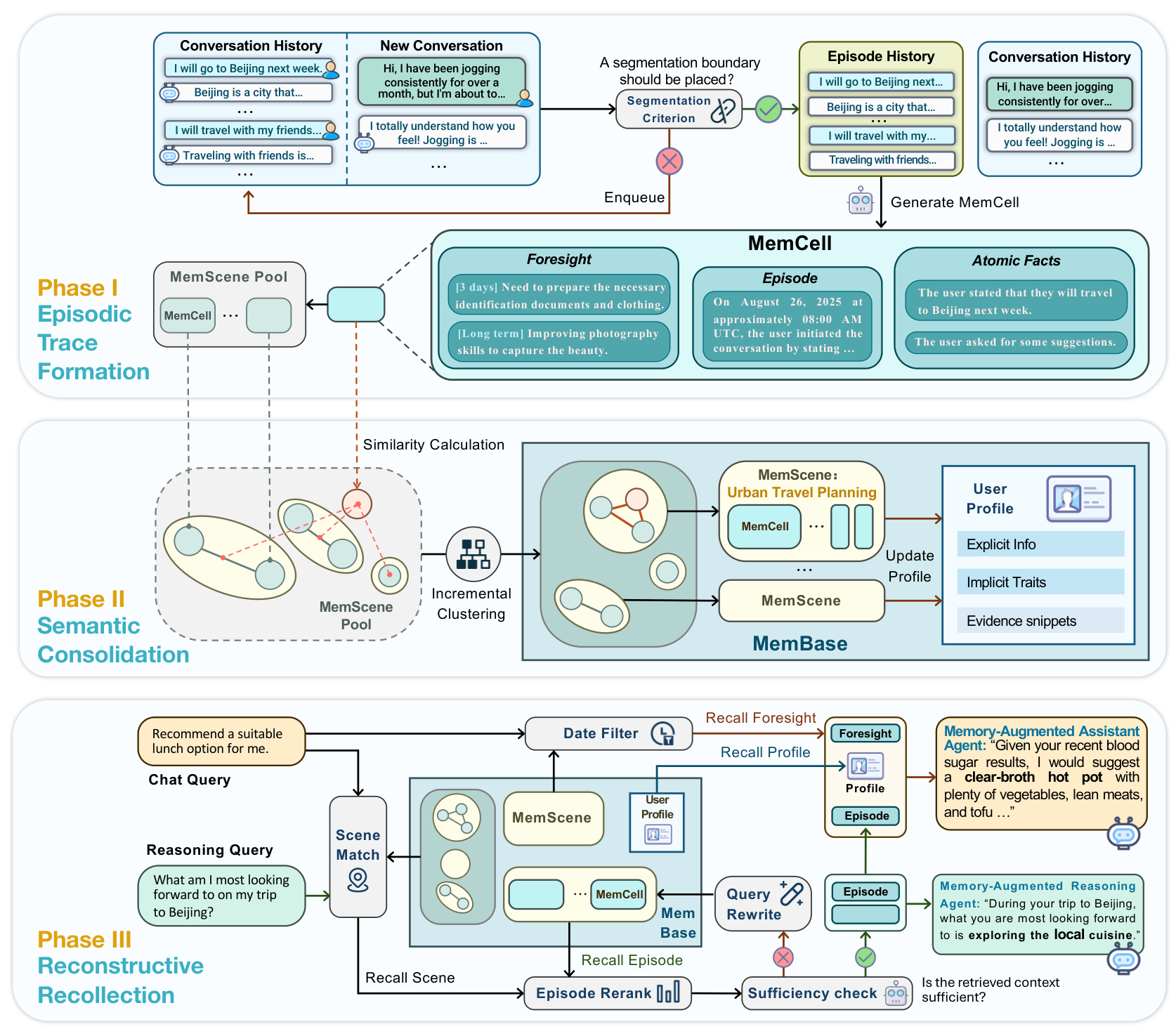 EverMemOS ArchitectureThe complete three-phase workflow: Episodic Trace Formation segments dialogue into MemCells, Semantic Consolidation clusters them into MemScenes with profile updates, and Reconstructive Recollection performs guided retrieval with sufficiency verification.
EverMemOS ArchitectureThe complete three-phase workflow: Episodic Trace Formation segments dialogue into MemCells, Semantic Consolidation clusters them into MemScenes with profile updates, and Reconstructive Recollection performs guided retrieval with sufficiency verification.
Benchmark Results
EverMemOS sets new state-of-the-art results on both major memory-augmented reasoning benchmarks when using GPT-4.1-mini as the backbone.
On LoCoMo (1,540 questions across 10 ultra-long dialogues), EverMemOS achieves 93.05% overall accuracy, surpassing the previous best system Zep [1] at 85.22%. The gains are most pronounced on questions requiring evidence integration: multi-hop accuracy reaches 91.84% (+12.1% over Zep) and temporal reasoning hits 89.72% (+16.1% over Zep). Single-hop accuracy reaches 96.67%.
On LongMemEval (500 questions spanning ~115k tokens per conversation), EverMemOS scores 83.00% overall versus MemOS [2] at 77.80%. The largest gain appears on knowledge update tasks (89.74%, +20.6% relative), demonstrating the value of semantic consolidation for tracking evolving user states.
On PersonaMem-v2 (5,000 questions across 9 scenarios), combining episodes with the consolidated User Profile achieves 53.25% accuracy -- a 9.32-point improvement over episodes-only (43.93%), confirming that semantic consolidation provides complementary signal beyond episodic retrieval alone.
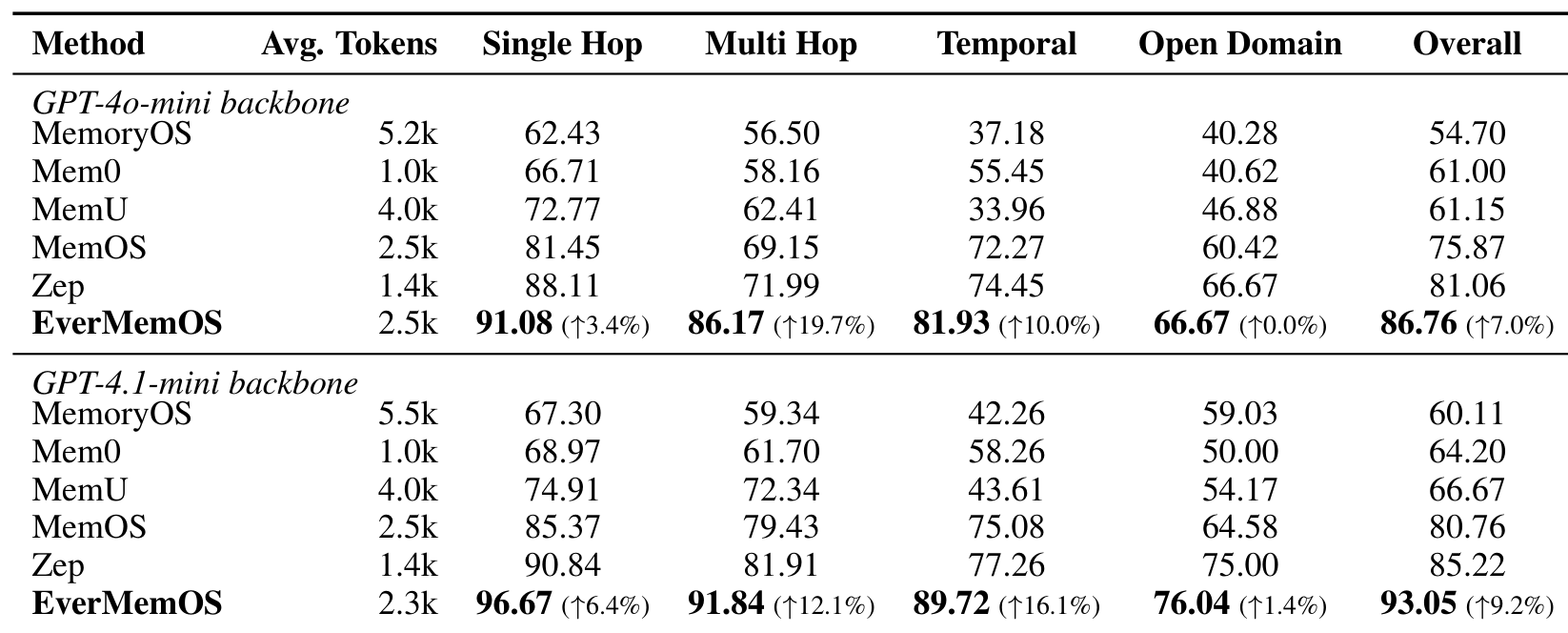 LoCoMo ResultsMain results on LoCoMo showing EverMemOS outperforming all baselines across single-hop, multi-hop, temporal, and open-domain question types under both GPT-4o-mini and GPT-4.1-mini backbones.
LoCoMo ResultsMain results on LoCoMo showing EverMemOS outperforming all baselines across single-hop, multi-hop, temporal, and open-domain question types under both GPT-4o-mini and GPT-4.1-mini backbones.
Notably, EverMemOS achieves these results with moderate token budgets (2.3k average retrieved tokens), positioned between Zep's lean 1.4k and MemoryOS's expensive 5.5k. The performance-versus-cost frontier demonstrates that at K=10 episodes, EverMemOS attains both lower token usage and higher accuracy than all baselines.
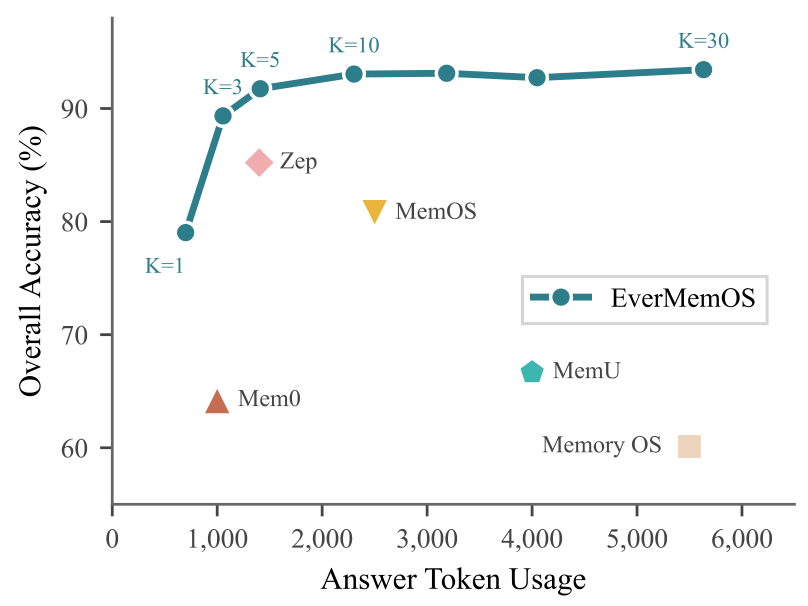 Cost-Accuracy FrontierPerformance vs. token cost on LoCoMo by varying the retrieved episode count (K), showing EverMemOS achieves the best accuracy-efficiency trade-off.
Cost-Accuracy FrontierPerformance vs. token cost on LoCoMo by varying the retrieved episode count (K), showing EverMemOS achieves the best accuracy-efficiency trade-off.
Ablation: What Each Component Contributes
A systematic ablation isolates the contribution of each architectural layer. On LoCoMo, removing MemScenes (using flat MemCell retrieval) drops overall accuracy from 93.05% to 89.16%, confirming that scene-level organization aids cross-turn evidence integration. Removing MemCells entirely (retrieving over raw dialogue) further drops performance to 81.82%. Without any external memory, accuracy collapses to 0.52%. The pattern is consistent on LongMemEval (83.00% to 79.60% to 71.20% to 5.00%), with each structural layer contributing measurably.
The episode segmentation strategy also matters: EverMemOS's semantic boundary detection outperforms both fixed heuristics (token chunking) and ground-truth session boundaries, suggesting that conversation sessions are not always optimal retrieval units.
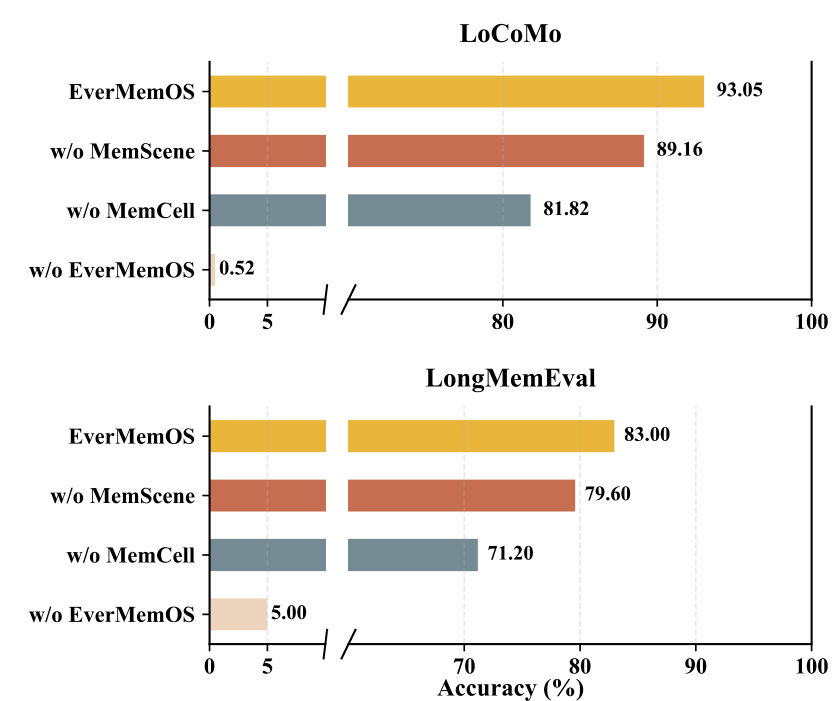 Ablation ResultsPerformance degradation as architectural components are removed, showing stepwise capability loss from EverMemOS to w/o MemScene to w/o MemCell to w/o EverMemOS on both benchmarks.
Ablation ResultsPerformance degradation as architectural components are removed, showing stepwise capability loss from EverMemOS to w/o MemScene to w/o MemCell to w/o EverMemOS on both benchmarks.
Research Context
This work builds on the Memory Operating System paradigm pioneered by MemGPT [5], which first applied the OS metaphor to LLM memory management. The concurrent landscape includes MemOS [2] (unified memory scheduling), Zep [1] (temporal knowledge graphs), Mem0 [3] (production-grade fact extraction), MemoryOS [4] (hierarchical three-tier storage), and Nemori [9] (a related cognitive-science-inspired approach using Event Segmentation Theory).
What is genuinely novel: The MemCell primitive with time-bounded Foresight (validity intervals for temporal awareness), the online incremental MemScene clustering, and the agentic sufficiency verification loop distinguish EverMemOS from flat-storage and graph-based alternatives. However, individual components (hybrid retrieval, episode segmentation, re-ranking) are well-established -- the contribution is their integration into a principled lifecycle.
Compared to Zep [1] (the previous LoCoMo leader), EverMemOS excels when multi-turn evidence integration is required. For low-latency production scenarios requiring minimal token budgets, Zep's 1.4k-token retrieval with knowledge graph structure may still be preferable.
Open questions include how EverMemOS performs with open-source LLM backbones (all experiments use GPT-4.1-mini), what the actual wall-clock latency overhead is in production, and whether the Foresight validity intervals are accurately estimated by the LLM.
Limitations
The authors acknowledge evaluation is limited to text-only conversational benchmarks, and the LLM-mediated lifecycle operations increase latency relative to single-pass baselines. The system's most novel capabilities -- Foresight filtering and profile stability -- are demonstrated only through qualitative case studies, as existing benchmarks do not evaluate these dimensions. The clustering threshold requires per-dataset tuning (0.70 for LoCoMo, 0.50 for LongMemEval), and stress-testing on ultra-long timelines (years of interaction) remains unexplored.
Check out the Paper and GitHub Repo. All credit goes to the researchers.
References
[1] Rasmussen, P. et al. (2025). Zep: A Temporal Knowledge Graph Architecture for Agent Memory. arXiv preprint. arXiv
[2] Li, Z. et al. (2025). MemOS: A Memory OS for AI System. arXiv preprint. arXiv
[3] Chhikara, P. et al. (2025). Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv preprint. arXiv
[4] Kang, J. et al. (2025). Memory OS of AI Agent. arXiv preprint. arXiv
[5] Packer, C. et al. (2024). MemGPT: Towards LLMs as Operating Systems. NeurIPS 2024. arXiv
[6] Maharana, A. et al. (2024). Evaluating Very Long-Term Conversational Memory of LLM Agents. arXiv preprint. arXiv
[7] Wu, D. et al. (2025). LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. arXiv preprint. arXiv
[8] Josselyn, S. et al. (2015). Finding the Engram. Nature Reviews Neuroscience. Paper
[9] Nan, J. et al. (2025). Nemori: Self-Organizing Agent Memory Inspired by Cognitive Science. arXiv preprint. arXiv


