Agent Memory Loss Solved: InfiAgent's File-Centric Architecture Enables Unlimited Runtime
Your agent remembers everything for the first 10 steps, then slowly loses its mind.
LLM agents are transforming from research curiosities into production tools for coding, research, and automation. Yet practitioners consistently encounter the same frustrating pattern: agents that perform brilliantly for short tasks but degrade dramatically on extended workflows. This performance degradation as context fills has been documented in the DeepResearch benchmark literature [1], showing that agent stability erodes regardless of how large the context window is.
Researchers from the University of Hong Kong and Hong Kong Polytechnic University have now proposed a fundamental architectural solution. InfiAgent introduces a paradigm shift: rather than cramming more information into the context window or compressing state through summarization, it externalizes persistent state entirely to the file system. The results are striking: a 20B parameter open-source model achieves performance competitive with much larger proprietary systems, and ablation studies show 21x degradation when the file-centric architecture is removed.
The Long-Horizon Problem
Conventional agent frameworks treat the LLM prompt as the primary carrier of state. As tasks progress, dialogue history, tool traces, intermediate plans, and partial results accumulate within the context window. This creates an inherent trade-off: truncation loses critical information, while preservation eventually overwhelms the model's reasoning capacity.
Approaches like RAG and long-context models partially mitigate this, but they still entangle long-term task state with immediate reasoning context. The cognitive load on the LLM increases as execution progresses, leading to unstable behavior over long horizons. Simply extending context length, as the authors note, "does not fundamentally resolve the long-horizon stability problem."
File-Centric State: A Paradigm Shift
InfiAgent's core insight is that persistent task state should be a first-class object, distinct from the bounded reasoning context. At each step, the agent reconstructs its working context from just two sources: a snapshot of the file system workspace plus a fixed window of the most recent k actions (where k=10 in practice).
The mathematical formulation is elegant: the bounded reasoning context is reconstructed as c_bounded = g(F_t, a_{t-k:t-1}), where F_t represents the file system state at time t. This guarantees that context size remains O(1) with respect to task horizon, while full task history is preserved implicitly through the persistent state.
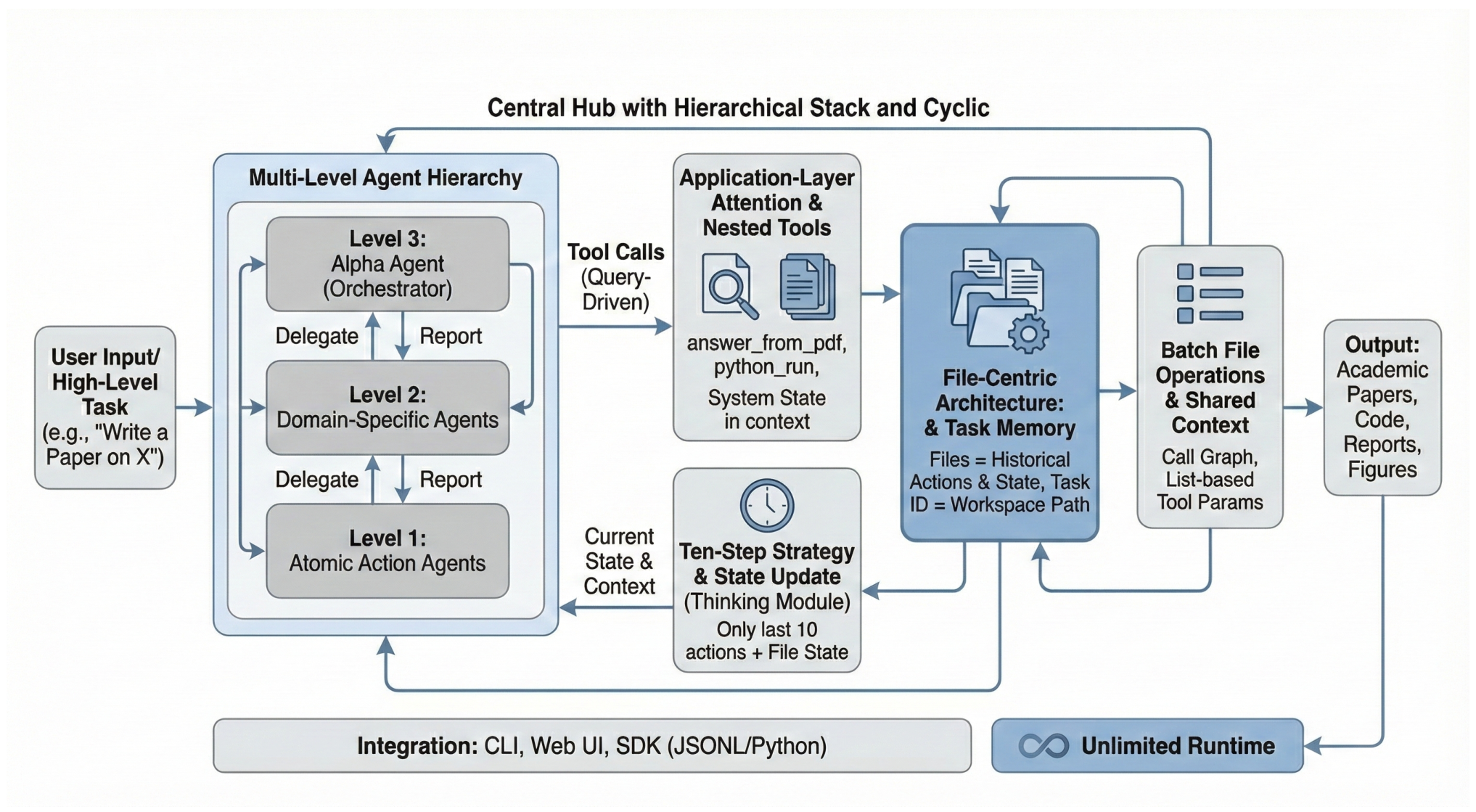 InfiAgent FrameworkThe hierarchical execution stack with file-centric persistent state. Files serve as authoritative task memory while external attention processes heavy documents outside the bounded reasoning context.
InfiAgent FrameworkThe hierarchical execution stack with file-centric persistent state. Files serve as authoritative task memory while external attention processes heavy documents outside the bounded reasoning context.
Hierarchical Agent Architecture
InfiAgent organizes agents into a tree-structured hierarchy with three levels. The Alpha Agent (Level 3) serves as the orchestrator, decomposing user requests into subtasks. Domain Agents (Level 2) are specialists like the Coder Agent or Paper Writer that execute specific workflows. Atomic Agents (Level 1) handle discrete tool executions such as web searching or file I/O.
This hierarchical design enables what the authors call "Agent-as-a-Tool": higher-level agents invoke lower-level agents as callable tools, preventing the "tool calling chaos" often observed in flat multi-agent systems. Unlike MAKER [2], which requires predefined task decomposition for structured problems, InfiAgent's hierarchy handles open-ended research tasks without task-specific structure.
External Attention Pipeline
To handle massive information without context bloat, InfiAgent introduces an External Attention Pipeline. When an agent needs information from a document, it doesn't load the document into its context. Instead, it calls a specialized tool (like answer_from_pdf) that spins up a temporary, isolated LLM process. This process queries the document and returns only the extracted answer. For example, when processing an 80-paper literature review, each paper is read through this isolated process rather than loaded into the main agent's context.
This mechanism acts as an application-layer attention head, selecting only relevant information from external data sources while keeping the main agent's cognitive load focused on decision-making.
Benchmark Results
On the DeepResearch benchmark [1], InfiAgent achieves an overall score of 41.45 with a 20B model. While this doesn't top the leaderboard (Tavily-Research with GPT-5 leads at 52.44), it places InfiAgent on a favorable efficiency frontier, outperforming Tongyi DeepResearch (30B) at 40.46 and approaching OpenAI DeepResearch (GPT-4o, 200B) at 46.45. Notably, InfiAgent scores 45.72 on instruction following and 44.87 on readability, which the authors attribute to the explicit file-centric state and structured execution pipeline.
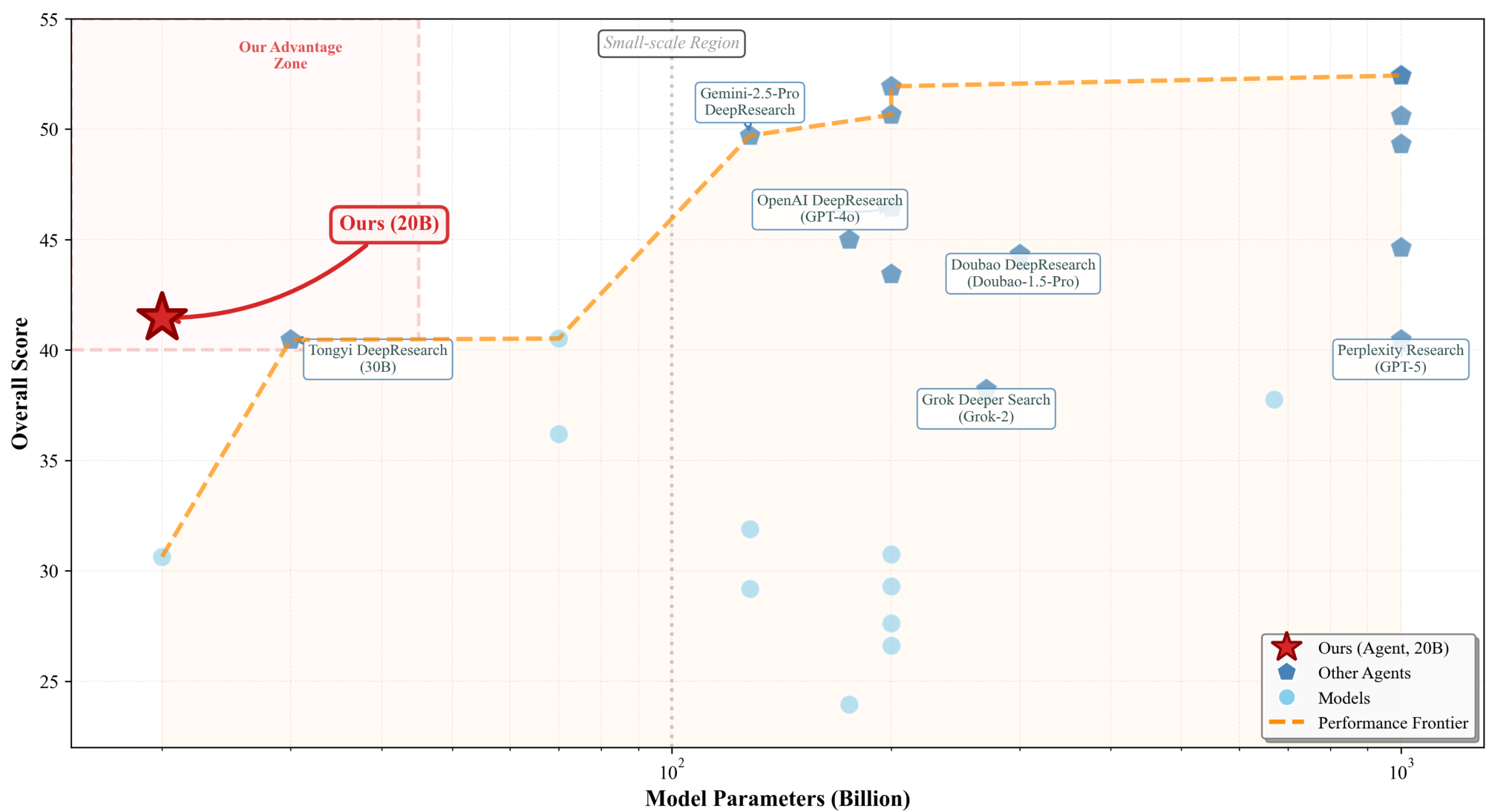 Performance ComparisonInfiAgent (20B) achieves competitive performance relative to larger proprietary agents, suggesting an improved efficiency-performance trade-off.
Performance ComparisonInfiAgent (20B) achieves competitive performance relative to larger proprietary agents, suggesting an improved efficiency-performance trade-off.
The more revealing evaluation is the 80-paper literature review task, designed to stress-test long-horizon stability. Here, InfiAgent with Claude-4.5-Sonnet or Gemini-3-Flash achieves perfect 80/80 coverage across runs. Even with the smaller 20B model, InfiAgent averages 67.1 papers successfully processed.
The baselines tell a stark story: Claude Code (using the same Claude-4.5-Sonnet backbone) manages only 29.1 average coverage, while Cursor collapses to 1.0 average with the same model. When the file-centric state is removed and replaced with compressed long-context prompts, coverage with the 20B model drops from 67.1 to just 3.2, a 21x degradation.
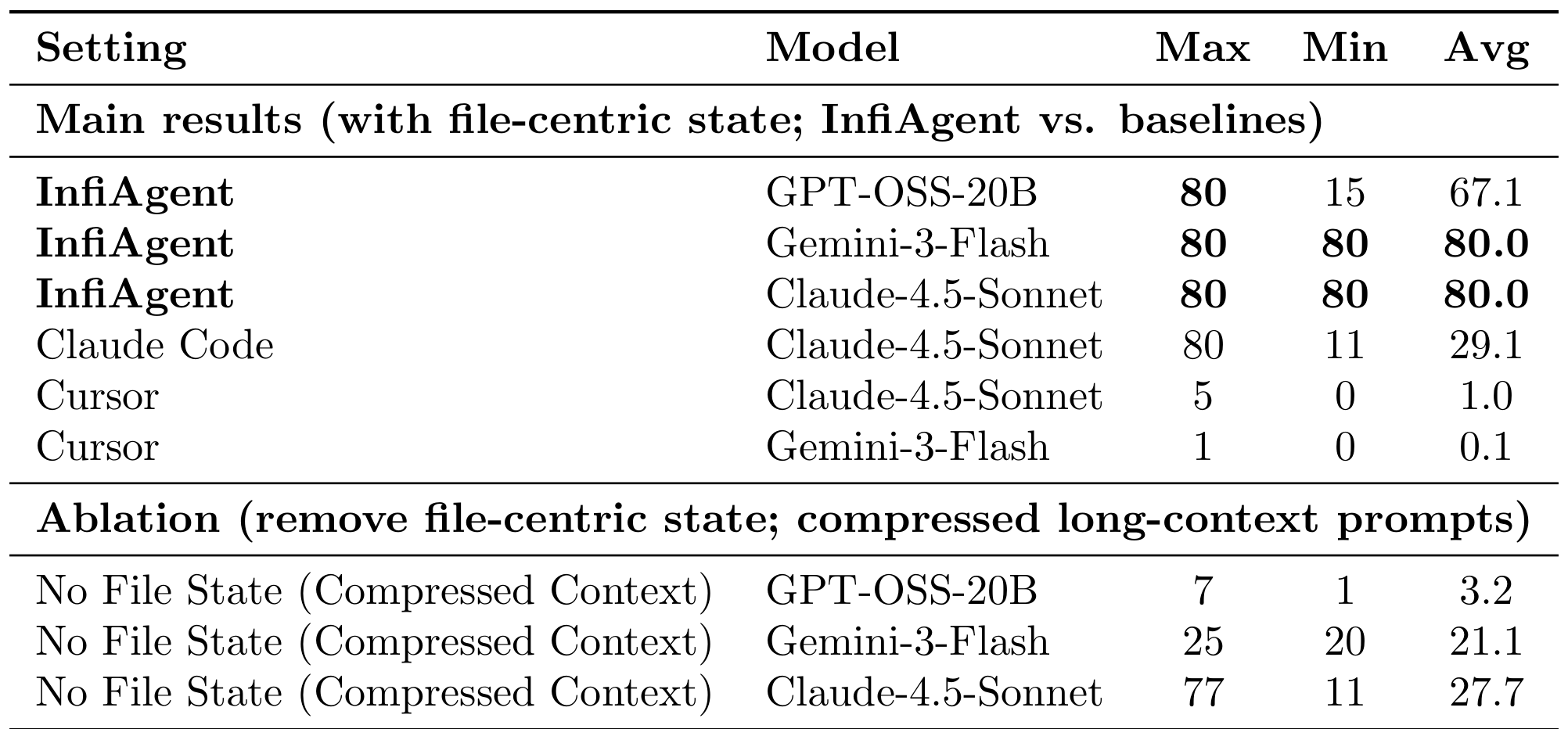 Coverage ResultsLong-horizon task reliability showing InfiAgent's consistent high coverage versus baseline degradation. The ablation demonstrates that file-centric state is the key enabler.
Coverage ResultsLong-horizon task reliability showing InfiAgent's consistent high coverage versus baseline degradation. The ablation demonstrates that file-centric state is the key enabler.
Real-World Applications
The framework has been instantiated as InfiHelper, a semi-general agent demonstrating versatility across domains. In computational biology, it conducted dry-lab experiments simulating protein compositions. In logistics, it performed automated shift scheduling optimization. In academic research, expert blind review of generated full-length papers found they achieved human-level quality, meeting acceptance criteria for standard conferences.
Research Context
This work builds on the DeepResearch benchmark findings [1] that document agent performance degradation over extended contexts. It also draws from MAKER [2], which showed that extreme decomposition can enable million-step execution for structured tasks.
What's genuinely new: The file-centric state abstraction that treats persistent state as distinct from prompt context; the Zero Context Compression principle where no information is discarded from authoritative state; and the empirical demonstration that long context cannot substitute for explicit state externalization.
Compared to MAKER [2], which achieves zero errors on structured logic problems through voting-based verification, InfiAgent trades guaranteed correctness for generality. For open-ended research workflows, InfiAgent offers practical applicability; for tasks requiring verifiable correctness, MAKER remains the stronger choice.
Open questions:
- How does InfiAgent scale to tasks requiring hundreds of files in persistent state?
- Can the file-centric abstraction extend to collaborative multi-agent settings?
- How can hallucination propagation through persistent state be detected and corrected?
Limitations
The authors acknowledge several constraints. The multi-level hierarchy introduces latency overhead as agent tree depth increases. Hallucination accumulation remains a risk, particularly with smaller models on extremely long tasks. The architecture strictly enforces serial execution to ensure state consistency, limiting efficiency for inherently parallelizable workflows.
Perhaps most significantly, file-centric state doesn't enhance the underlying model's reasoning. If incorrect information is written to files, it propagates to all downstream steps. The framework is better suited for knowledge-intensive workflows than real-time interactive applications.
Check out the Paper and GitHub (587 stars). All credit goes to the researchers.
References
[1] Shojaee, P. et al. (2025). DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv preprint. arXiv
[2] Meyerson, E. et al. (2025). Solving a Million-Step LLM Task with Zero Errors. arXiv preprint. arXiv


