Prompt Fatigue Solved: Vibe AIGC Turns Users Into 'Commanders' of Multi-Agent Creative Workflows
What if the problem with AI content generation isn't the models—it's that we're using them wrong?
Despite remarkable advances in generative AI, content creators still face a fundamental frustration: hours spent in trial-and-error "prompt engineering" to coax coherent results from increasingly capable models. Building on the Vibe Coding philosophy popularized by Andrej Karpathy [1], researchers from Nanjing University and Kuaishou Technology have introduced Vibe AIGC—a paradigm that reconceptualizes content generation as orchestrated multi-agent workflows rather than single-shot inference.
The paper argues that the trajectory of generative AI has hit a "usability ceiling" despite significant improvements in visual fidelity. The core problem is what the authors term the Intent-Execution Gap: the fundamental disparity between a creator's high-level, multi-dimensional vision and the stochastic (random, probabilistic) nature of current generation models, which operate as "black boxes"—systems whose internal workings are opaque to users. Users are relegated to "prompt engineers" who must engage in what the paper colorfully describes as "latent space fishing" to produce coherent results.
The Vibe AIGC Philosophy
The central insight of Vibe AIGC is a shift in user role from "Prompt Engineer" to "Commander." Rather than crafting precise prompts and hoping for the best, users provide a Vibe—a high-level representation encompassing aesthetic preferences, functional goals, and systemic constraints. The system then autonomously determines implementation details.
This mirrors the transition seen in software development with Vibe Coding [1], where developers increasingly provide strategic vision while AI handles tactical code generation. Vibe AIGC extends this philosophy to multimodal content creation, arguing that natural language has reached sufficient "semantic density" to serve as a meta-syntax for complex creative workflows.
The paper draws a clear distinction: current tools require users to specify the "How," while Vibe AIGC only requires the "What and the Vibe." As the authors put it: "The next frontier of artificial intelligence is not larger models, but smarter orchestration."
Architecture: The Meta Planner at the Core
The Vibe AIGC architecture centers on a Meta Planner—a cognitive core that translates natural language intent into executable system architectures. The Meta Planner functions as a system architect, deconstructing high-level vibes into verifiable and adaptive agentic pipelines. As illustrated in Figure 5, the architecture flows from Commander Instructions through hierarchical layers to final output.
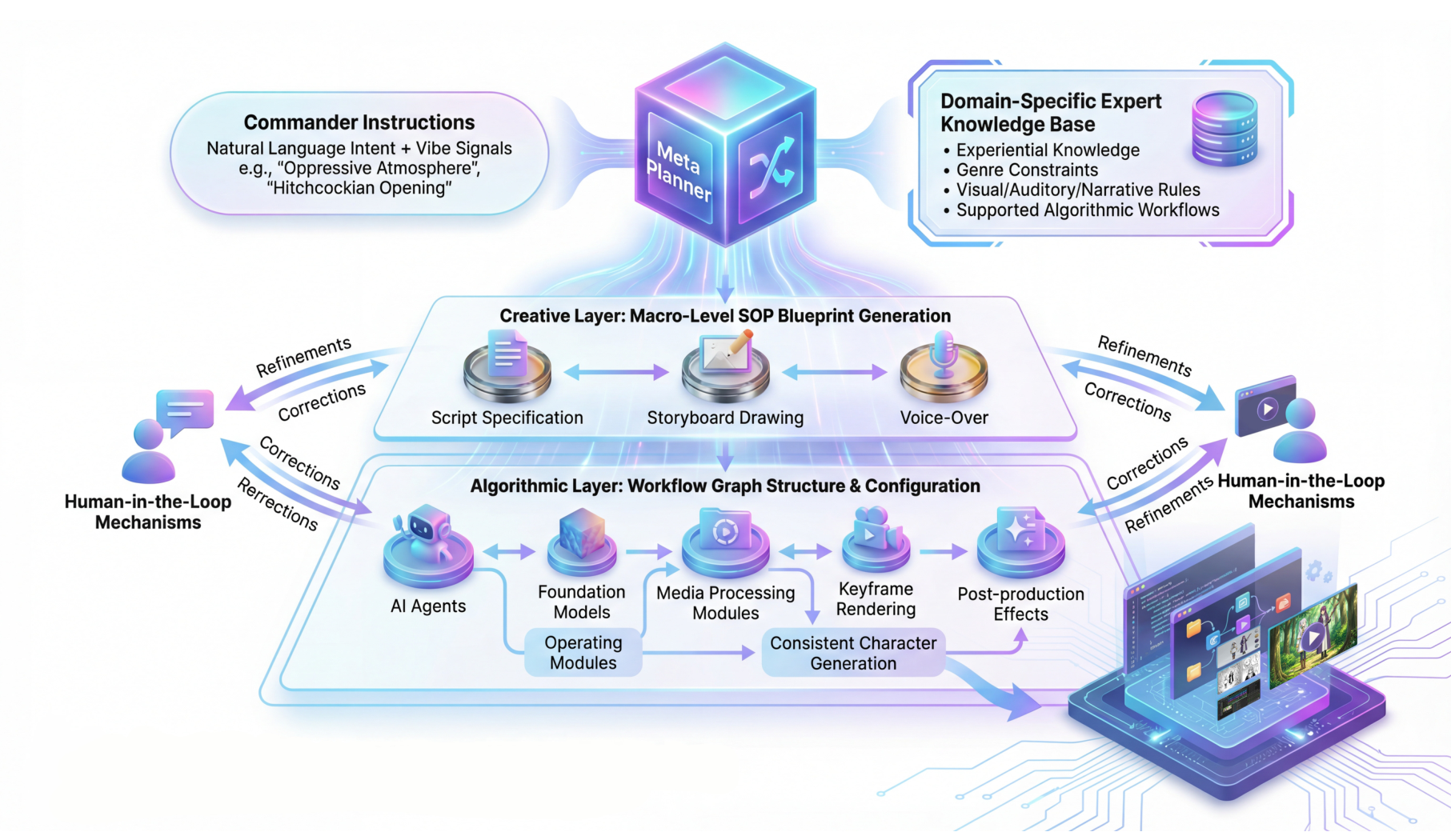 Vibe AIGC Architecture
The complete system showing Commander Instructions flowing through the Meta Planner to Creative and Algorithmic Layers, with Human-in-the-Loop refinement mechanisms.
Vibe AIGC Architecture
The complete system showing Commander Instructions flowing through the Meta Planner to Creative and Algorithmic Layers, with Human-in-the-Loop refinement mechanisms.
The architecture operates through several interconnected components:
Domain-Specific Expert Knowledge Base: Stores professional skills, experiential knowledge, and algorithmic workflow registries. This enables the system to translate abstract vibes—like "oppressive atmosphere"—into concrete engineering constraints such as low-key lighting, close-up shots, and low-saturation filters.
Hierarchical Orchestration: The system maps tasks through two layers of abstraction. The Creative Layer generates macro-level SOP blueprints (script specification, storyboard drawing, voice-over), while the Algorithmic Layer configures workflow graph structures and selects optimal component ensembles from an atomic tool library.
Human-in-the-Loop Mechanisms: Rather than re-rolling random seeds, feedback like "make it darker" or "increase tension" reconfigures workflow logic itself, enabling meaningful iterative refinement.
Preliminary Systems in Action
The paper demonstrates feasibility through three working prototypes:
AutoPR transforms research paper promotion from a fragmented manual workflow into a one-click agentic pipeline. As shown in Figure 2, multiple specialized agents handle content extraction, visual analysis, textual enrichment, and platform-specific adaptation.
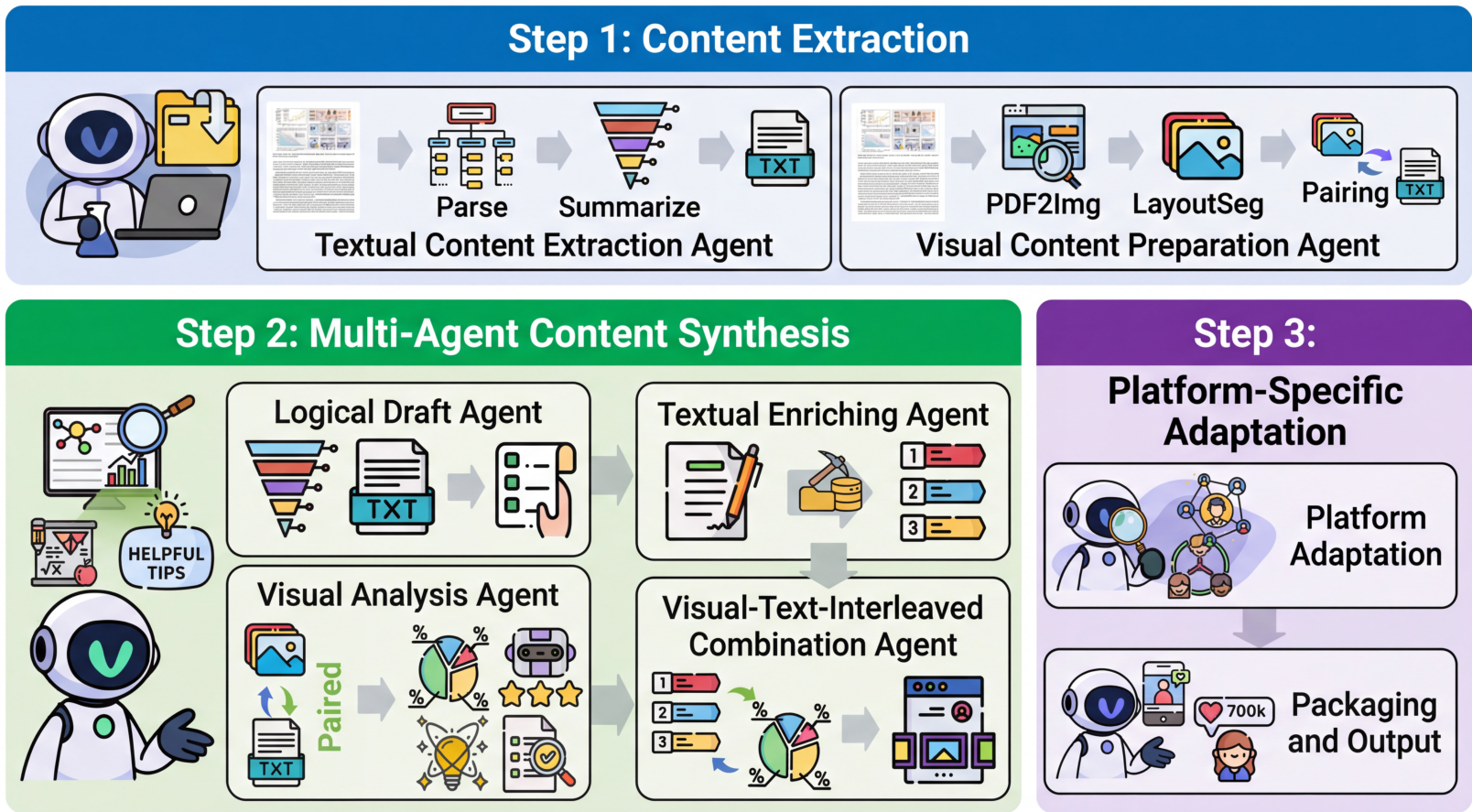 AutoPR Pipeline
Multi-agent workflow showing content extraction, synthesis across multiple specialized agents, and platform-specific output adaptation.
AutoPR Pipeline
Multi-agent workflow showing content extraction, synthesis across multiple specialized agents, and platform-specific output adaptation.
AutoMV generates music videos through a collaborative pipeline where a Screenwriter Agent drafts scripts based on musical attributes, a Director Agent manages a Character Bank for consistency, and verification agents ensure visual coherence across full-length songs. Unlike single-shot video generation [4], this approach maintains character and stylistic consistency throughout.
Poster Copilot demonstrates agentic layout reasoning for graphic design, translating abstract vibe instructions into concrete design parameters—geometric composition, color palettes, and layer hierarchies—while maintaining human-in-the-loop feedback for refinement.
The Hard Questions
The authors commendably address fundamental challenges to their paradigm:
The Bitter Lesson: As Rich Sutton famously argued, scaling tends to win. The Intent-Execution Gap might be temporary—future scaled models could potentially parse vibes in a single shot without multi-agent overhead.
Verification Crisis: Unlike code with unit tests, vibes are inherently subjective. There's no universal test for "cinematic atmosphere" or "melancholic pacing," risking what the authors call "aesthetic hallucination."
Compounding Failures: Multi-agent systems lack the equivalent of a compiler. Minor semantic drift in an upstream agent can cause catastrophic hallucinations throughout the workflow. Recent work on multi-agent failure modes [6] has documented these cascading error patterns.
Research Context
This work builds on Vibe Coding [1] and extends agentic synthesis concepts demonstrated in OpenAI's Deep Research [2].
What's genuinely new:
- Systematic formalization of the "Intent-Execution Gap" as a fundamental limitation
- Hierarchical Creative/Algorithmic layer decomposition for content generation
- Domain-Specific Expert Knowledge Base for translating abstract vibes into engineering constraints
- User role reconceptualization from prompt engineer to commander
Compared to ViMax [5], the most similar agentic video generation system, Vibe AIGC offers a more comprehensive theoretical framework but less concrete implementation. ViMax provides RAG-based script engines and specific storyboard systems; Vibe AIGC proposes a paradigm-level architecture. For scenarios requiring immediate, production-ready agentic video generation, ViMax or commercial tools like HeyGen may be more practical today. For scenarios requiring conceptual grounding and research direction, Vibe AIGC provides the theoretical foundation.
Open questions:
- Can scaling laws eventually enable single models to parse vibes without multi-agent overhead?
- How can objective verification mechanisms be developed for subjective aesthetic outputs?
- What constitutes a complete Domain-Specific Expert Knowledge Base for creative tasks?
Practical Implications
The paper advocates using Vibe AIGC principles when creating complex, long-horizon content requiring temporal consistency, when users have high-level creative vision but lack technical expertise, or when tasks require coordination of multiple specialized tools. Model-centric approaches like Kling [3] or Stable Video Diffusion [4] remain preferable when single-shot generation quality is paramount, latency constraints prevent multi-agent overhead, or users prefer direct manipulation over delegated control.
As multi-agent architectures become increasingly central to enterprise AI deployments, the infrastructure for Vibe AIGC's vision is growing more accessible. Whether this paradigm becomes dominant—or whether larger models simply close the Intent-Execution Gap through brute-force scaling—remains an open question that will define the next chapter of generative AI.
Check out the Paper. All credit goes to the researchers.
References
[1] Karpathy, A. (2025). Vibe Coding. X/Twitter post. Wikipedia
[2] OpenAI. (2025). Introducing Deep Research. OpenAI Blog. Link
[3] Kuaishou. (2026). Kling O1: Unified Multimodal Video Model. News Release. Link
[4] Blattmann, A. et al. (2023). Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets. arXiv preprint. arXiv
[5] HKUDS. (2025). ViMax: Agentic Video Generation. GitHub. GitHub
[6] Cemri, M. et al. (2025). Why Do Multi-Agent LLM Systems Fail?. ICLR 2025. arXiv


