11% Better Than Human: Chroma 1.0's Real-Time Voice Cloning for Spoken Dialogue
The first open-source model that can have a real-time conversation in your voice - not a generic AI voice, but specifically cloned from a short audio sample.
Voice AI has reached a crossroads. Developers building conversational AI applications face an uncomfortable choice: use expensive commercial APIs like ElevenLabs for high-quality voice cloning, or accept generic AI voices from open-source dialogue systems. Until now, no solution offered both real-time dialogue and personalized voice synthesis in a single, deployable package.
Researchers from FlashLabs have released Chroma 1.0, the first open-source end-to-end spoken dialogue model that combines low-latency real-time interaction with high-fidelity personalized voice cloning. Building on the multimodal architectures pioneered by Qwen2.5-Omni [1] and the neural audio codec approach from VALL-E [3], Chroma achieves a 10.96% improvement in speaker similarity over human baseline recordings while maintaining a Real-Time Factor of 0.43—generating speech 2.3 times faster than playback speed.
The Voice Cloning Gap in Dialogue Systems
Current end-to-end spoken dialogue systems like GLM-4-Voice [4] focus on semantic accuracy and reasoning capabilities but generate responses in fixed, generic voices. Conversely, voice cloning systems like Seed-TTS [5] and CosyVoice 3 [6] produce impressive speaker-matched audio but operate only as text-to-speech pipelines—they cannot engage in real-time dialogue.
Traditional approaches using cascaded ASR-LLM-TTS pipelines introduce additional problems: high latency from serial processing, error propagation between components, and loss of paralinguistic information like speaker timbre, emotion, and prosody. The result is conversational AI that either sounds generic or responds too slowly for natural interaction.
How Chroma Works: Four-Component Architecture
Chroma 1.0 addresses this gap through a tightly coupled four-component architecture that processes speech directly without intermediate text conversion:
Chroma Reasoner serves as the multimodal understanding module, built on the Thinker module from Qwen2.5-Omni with Time-aligned Multimodal Rotary Position Embedding (TM-RoPE) for cross-modal attention. This frozen component extracts semantic representations from input speech and text.
Chroma Backbone is a 1 billion parameter LLaMA variant that generates coarse acoustic codes conditioned on voice cloning embeddings. The key innovation here is an interleaved text-audio token schedule at a 1:2 ratio, enabling synchronized streaming generation without waiting for complete text sequences.
Chroma Decoder is a lightweight 100 million parameter module that performs frame-synchronous inference to predict the remaining Residual Vector Quantization (RVQ) levels. This decoupled design reduces latency while preserving generation quality.
Chroma Codec Decoder follows the Mimi vocoder design from Moshi [2], using a causal CNN to reconstruct continuous waveforms from discrete codebook sequences. The system uses 8 codebooks (N=8) for real-time efficiency, significantly reducing the autoregressive refinement steps required.
For voice cloning, reference audio and its transcript are encoded via CSM-1B and prepended to condition the Backbone on target speaker characteristics. The end-to-end architecture preserves fine-grained speaker features throughout generation, unlike two-stage approaches that create a voice profile separately from synthesis.
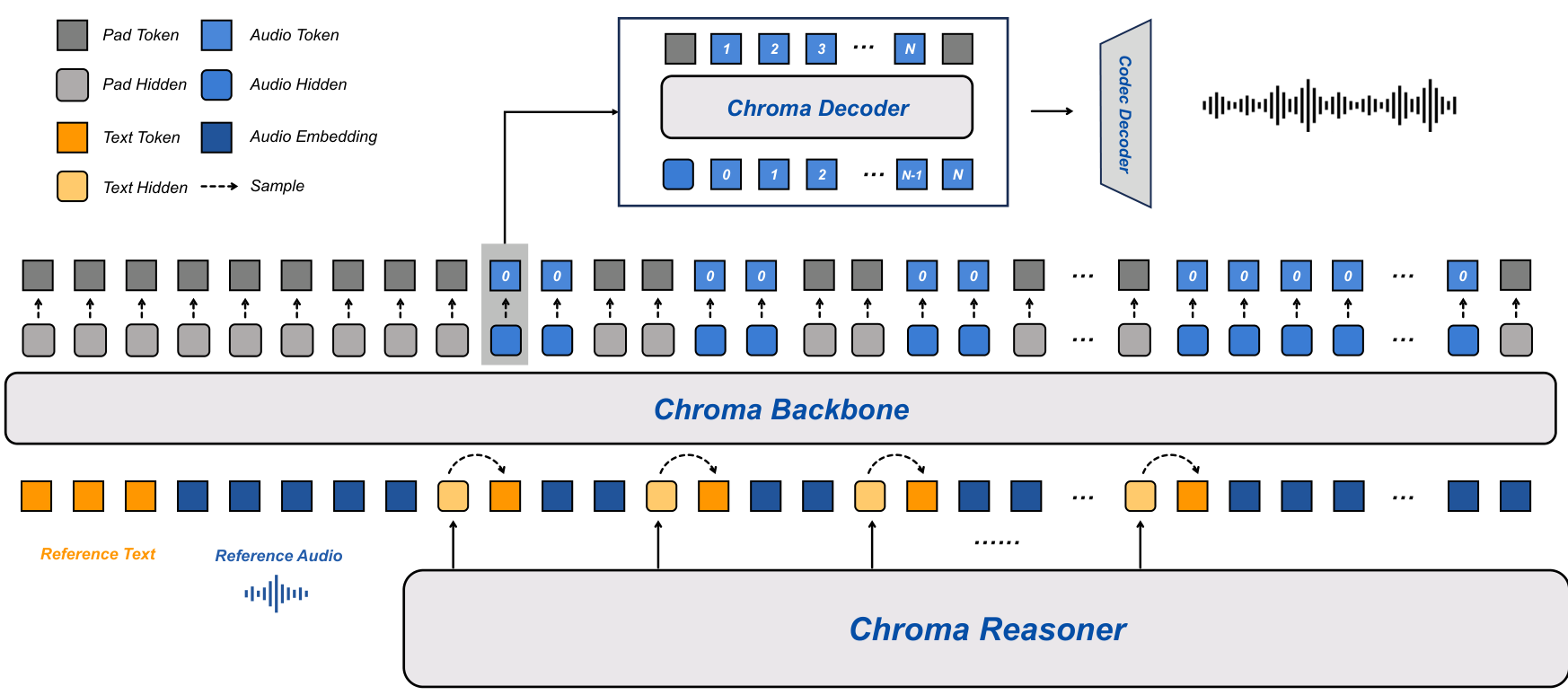 Chroma ArchitectureThe four-component system showing the Reasoner outputting text tokens and hidden states, the Backbone generating coarse acoustic codes with interleaved text-audio embeddings at 1:2 ratio, the Decoder predicting remaining RVQ levels, and the Codec Decoder reconstructing the waveform.
Chroma ArchitectureThe four-component system showing the Reasoner outputting text tokens and hidden states, the Backbone generating coarse acoustic codes with interleaved text-audio embeddings at 1:2 ratio, the Decoder predicting remaining RVQ levels, and the Codec Decoder reconstructing the waveform.
Key Results: Speaker Similarity and Latency
The most striking result is Chroma's speaker similarity score. On the SEED-TTS-EVAL benchmark, Chroma achieves 0.81 SIM—surpassing the human baseline of 0.73 by 10.96% and outperforming both Seed-TTS [5] (0.76) and CosyVoice 3 [6] (0.72). This places Chroma at the top of all compared models for voice cloning fidelity.
For latency, Chroma achieves a Time-to-First-Token of 146.87ms and an average latency of 52.34ms per frame. The Real-Time Factor of 0.43 means the system generates speech more than twice as fast as needed for real-time playback.
On the URO-Bench dialogue benchmark [8], Chroma scores 57.44 overall with only 4 billion parameters. While this trails GLM-4-Voice's 69.09 score, that model uses 9 billion parameters and lacks voice cloning capability. Notably, Chroma achieves the highest score on the MLC oral conversation subset (60.26%) among all compared models.
Trade-offs: Naturalness vs Speaker Fidelity
Subjective human evaluation reveals an interesting trade-off. In Comparative Mean Opinion Score (CMOS) testing against ElevenLabs, Chroma nearly matches on speaker similarity (40.6% vs 42.4% preference) but trails significantly on naturalness (24.4% vs 57.2%).
The evaluation surfaced a counterintuitive finding: listeners preferred ElevenLabs-generated audio over actual human ground truth recordings 92% of the time. This suggests that optimizing for perceptual naturalness may not align with optimizing for speaker fidelity—commercial systems have learned to produce speech that sounds more "polished" than real human recordings.
Chroma's design explicitly prioritizes speaker identity preservation over perceptual polish, making it better suited for applications where voice authenticity matters more than manufactured naturalness.
Research Context
This work builds on Qwen2.5-Omni's Thinker module [1] for multimodal understanding and the Mimi vocoder from Moshi [2] for waveform reconstruction.
What's genuinely new:
- First open-source real-time end-to-end spoken dialogue model with personalized voice cloning
- Interleaved text-audio token schedule (1:2 ratio) enabling streaming without complete text sequences
- Decoupled lightweight Decoder (100M parameters) for frame-synchronous inference
- End-to-end architecture preserving fine-grained speaker characteristics throughout generation
Compared to GLM-4-Voice [4], the strongest dialogue competitor, Chroma trades 17% lower reasoning performance for unique voice cloning capability with 55% fewer parameters. Against ElevenLabs, Chroma nearly matches speaker similarity while providing end-to-end dialogue capability that the commercial system lacks entirely.
Open questions:
- How does voice cloning fidelity degrade with conversation length and multiple speaker turns?
- What is the minimum viable reference audio duration for acceptable voice cloning?
- Can the architecture be extended to full-duplex conversation while maintaining voice cloning?
Limitations
The system currently generates English output only, despite supporting multilingual input. Latency measurements were taken at concurrency of 1 without batch processing, which may not reflect production deployment scenarios. The authors also note that speaker similarity was evaluated at 24kHz while some baselines used 16kHz, potentially advantaging Chroma in those comparisons.
Beyond the authors' acknowledged limitations, the model is trained entirely on synthetic speech-to-speech data generated through an LLM+TTS pipeline, which may limit generalization to in-the-wild speech patterns. There are also no ablation studies validating the choice of 1:2 text-audio interleaving ratio over alternatives.
Check out the Paper, GitHub, and Hugging Face Models. All credit goes to the researchers.
References
[1] Xu, J. et al. (2025). Qwen2.5-Omni Technical Report. arXiv preprint. arXiv
[2] Défossez, A. et al. (2024). Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint. arXiv
[3] Wang, C. et al. (2023). Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E). arXiv preprint. arXiv
[4] Zeng, A. et al. (2024). GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot. arXiv preprint. arXiv
[5] Anastassiou, P. et al. (2024). Seed-TTS: A Family of High-Quality Versatile Speech Generation Models. arXiv preprint. arXiv
[6] Du, Z. et al. (2025). CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training. arXiv preprint. arXiv
[7] Huang, A. et al. (2025). Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction. arXiv preprint. arXiv
[8] Yan, R. et al. (2025). URO-Bench: A Comprehensive Benchmark for End-to-End Spoken Dialogue Models. EMNLP 2025 Findings. arXiv


