DeepResearchEval: Benchmark Shows Gemini Leads Quality, Manus Wins Factual Accuracy
Gemini-2.5-Pro produces the highest quality research reports, but Manus is the most factually accurate.
Deep research systems like OpenAI Deep Research, Gemini Deep Research, and Manus are transforming how AI handles complex investigative tasks. These systems autonomously browse the web, retrieve information from multiple sources, and synthesize comprehensive reports. But evaluating their quality has remained an open problem. Existing benchmarks suffer from three key limitations: they require expensive manual annotation, use fixed evaluation criteria that don't adapt to task requirements, and only verify cited claims while leaving uncited factual statements unchecked.
Researchers from Infinity Lab (Shanda Group) and Nanyang Technological University have introduced DeepResearchEval, an automated framework that addresses all three gaps. Unlike prior benchmarks such as DeepResearch Bench [1] and DeepResearch Arena [2] which rely on manual task construction or static evaluation dimensions, DeepResearchEval combines automated persona-driven task generation, adaptive quality evaluation, and active fact-checking of both cited and uncited claims.
The Deep Research Evaluation Challenge
Current deep research systems produce long-form reports that vary substantially across tasks and domains. Evaluating these outputs differs fundamentally from conventional QA tasks. Prior benchmarks like Mind2Web 2 [3] and GAIA [4] focus on general reasoning and tool use, while newer benchmarks like LiveResearchBench [5] employ static evaluation dimensions shared across all tasks.
The gap is clear: when a user asks about semiconductor supply chains versus nutritional analysis of plant-based meats, the quality criteria should differ significantly. A one-size-fits-all rubric misses task-specific requirements. Moreover, existing fact-checking approaches only verify statements with citations, leaving the majority of factual claims in uncited passages unexamined.
How DeepResearchEval Works
The framework consists of two main components: automated task construction and agentic evaluation.
Persona-Driven Task Construction
DeepResearchEval generates realistic research tasks without manual annotation through a three-stage pipeline. First, it synthesizes 50 diverse personas across 10 domains including Finance, Health, Software Development, and Science & Technology. Each persona includes specific roles, backgrounds, and expertise areas.
For each persona, an LLM generates four candidate research tasks requiring multi-round web searches, multi-source evidence integration, and concrete deliverables with time constraints. Tasks then pass through two filters: a Task Qualification Filter that retains only tasks with confidence above 0.7 requiring up-to-date knowledge and multi-source investigation, and a Search Necessity Filter that discards tasks solvable by LLM parametric knowledge alone.
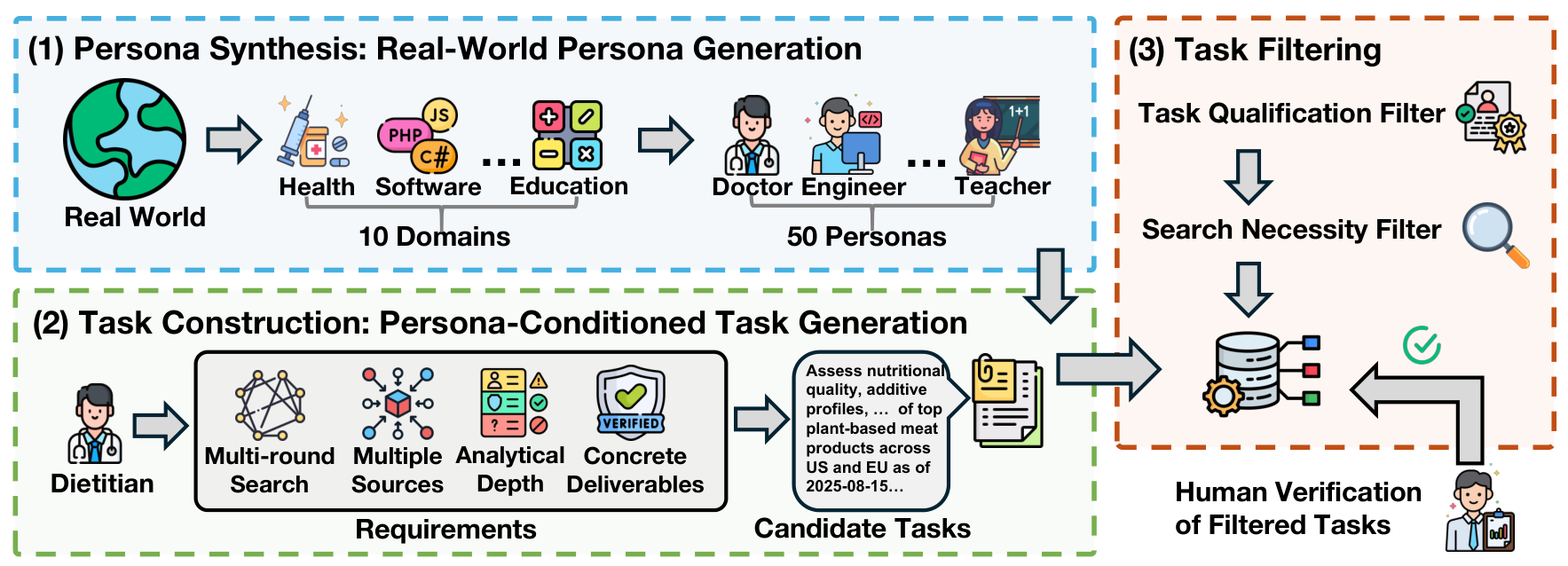 Task PipelineThe three-stage pipeline for constructing persona-driven deep research tasks, showing persona synthesis across 10 domains, task construction with requirements, and filtering stages.
Task PipelineThe three-stage pipeline for constructing persona-driven deep research tasks, showing persona synthesis across 10 domains, task construction with requirements, and filtering stages.
Human validation with seven PhD domain experts confirmed the pipeline's effectiveness: 80% of retained tasks were deemed qualified by at least four experts.
Adaptive Point-wise Quality Evaluation
Rather than applying fixed rubrics, DeepResearchEval dynamically generates task-specific evaluation dimensions. The evaluator combines four general dimensions (Coverage, Insight, Instruction-following, Clarity) with task-specific dimensions tailored to each query.
For a task comparing international semiconductor policies, the system might generate "Metric Utility" and "Comparative Synthesis" as task-specific dimensions. Each dimension is further instantiated with weighted evaluation criteria, enabling fine-grained scoring on a 1-10 scale.
Active Fact-Checking
The most significant innovation is active fact-checking of both cited and uncited claims. The system segments reports into parts, extracts verifiable statements involving numbers, events, dates, and entities, then uses MCP-based tools (Model Context Protocol, a standard for connecting AI models to external tools and data sources) to retrieve external evidence via web search.
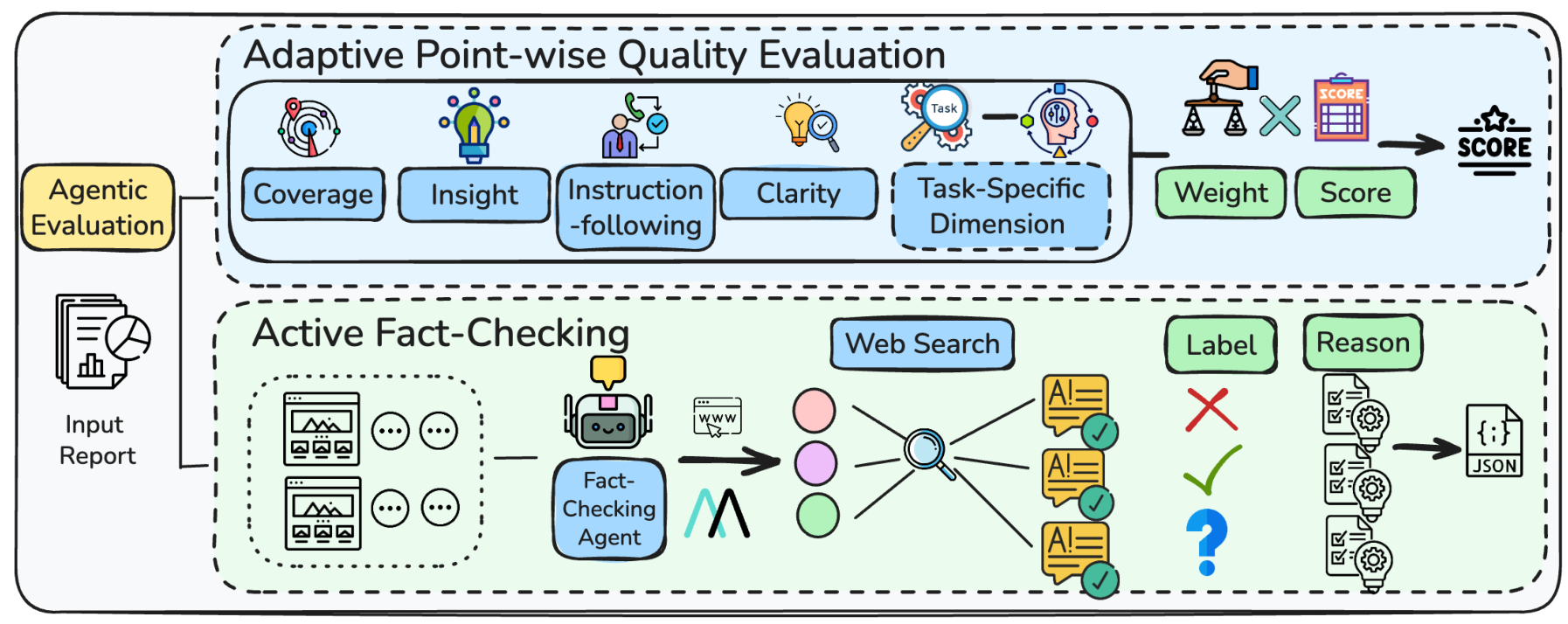 Evaluation PipelineOverview showing Adaptive Point-wise Quality Evaluation with dimension weighting (top) and Active Fact-Checking with MCP-based retrieval and label assignment (bottom).
Evaluation PipelineOverview showing Adaptive Point-wise Quality Evaluation with dimension weighting (top) and Active Fact-Checking with MCP-based retrieval and label assignment (bottom).
Each statement receives one of three labels: Right (supported by evidence), Wrong (contradicted by evidence), or Unknown (insufficient evidence to verify either way). This approach verifies the entire report, not just cited portions.
Benchmark Results: 9 Systems Evaluated
The researchers evaluated 900 deep research reports across 9 commercial systems, with 100 tasks per system. The results reveal clear stratification in capabilities.
Quality Evaluation
Gemini-2.5-Pro Deep Research achieved the highest average quality score at 8.51/10, leading across all dimensions. Claude-Sonnet-4.5 Deep Research followed at 7.53, while DeepSeek Deep Research scored lowest at 5.25.
Notably, task-specific scores were consistently lower than general scores across all systems. This gap indicates that while systems excel at general synthesis, they often fail to meet task-specific success criteria.
Factual Accuracy
Manus achieved the highest factual correctness ratio at 82.30%, with Gemini-2.5-Pro and DeepSeek also exceeding 76%. In contrast, Perplexity (58.94%) and Claude-Sonnet-4.5 (60.72%) showed lower ratios with more unverifiable or incorrect statements.
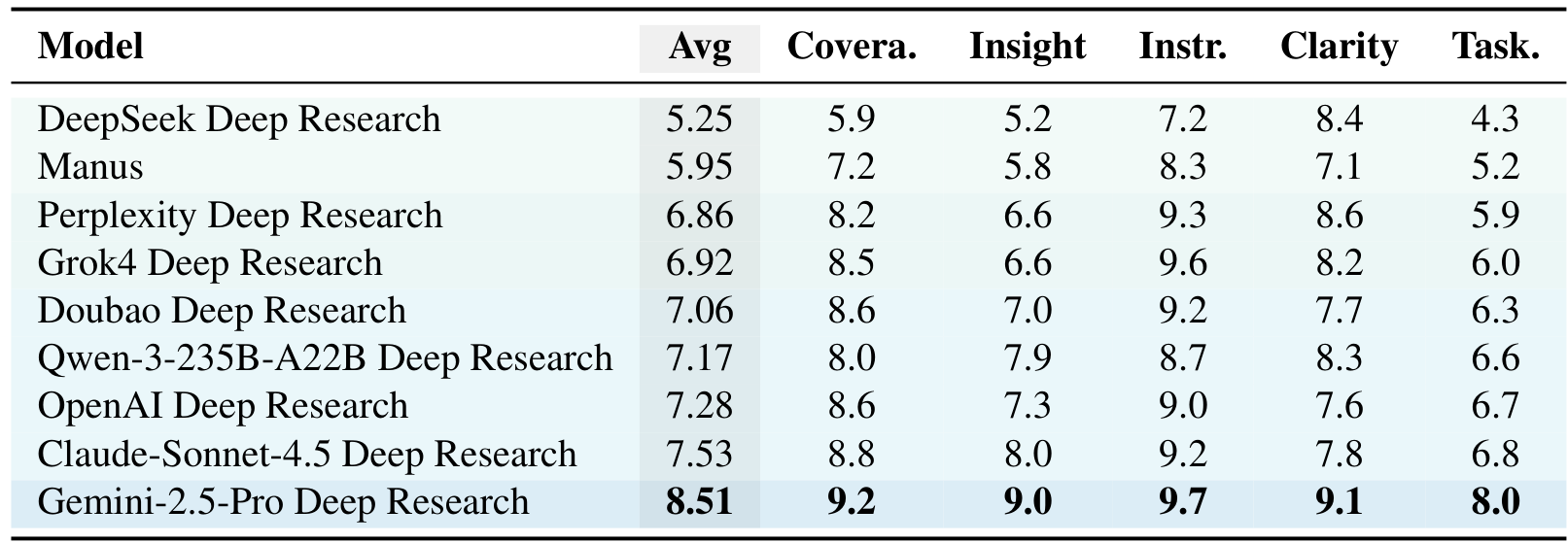 Quality ResultsQuality evaluation results across 9 deep research systems showing Average, Coverage, Insight, Instruction-following, Clarity, and Task-specific scores.
Quality ResultsQuality evaluation results across 9 deep research systems showing Average, Coverage, Insight, Instruction-following, Clarity, and Task-specific scores.
Systems with higher accuracy exhibited consistently low Wrong counts. Manus and DeepSeek averaged only 2.23 and 1.81 wrong statements per report, indicating strong avoidance of false claims. Unknown statements (claims that couldn't be verified either way due to insufficient evidence) ranged from 4-17 per report across systems, suggesting factual risks stem more from weakly grounded claims than outright errors.
Research Context
This work builds on the foundation of benchmarks like GAIA [4] for general AI assistants and long-form factuality evaluation [6]. Unlike DeepResearch Bench [1] which requires manual task construction with static dimensions, or DeepResearch Arena [2] which lacks active fact verification, DeepResearchEval is the first benchmark combining all three: automated task generation, adaptive evaluation dimensions, and active fact-checking of uncited claims.
What's genuinely new:
- Automated persona-driven task construction without expert annotation
- Adaptive evaluation dimensions generated per-task rather than fixed rubrics
- Active fact-checking that verifies both cited and uncited statements via web retrieval
Compared to the strongest competitor DeepResearch Bench, this approach offers more nuanced task-specific evaluation at the cost of higher computational requirements. For scenarios requiring real-time evaluation or non-English systems, alternatives may be preferable.
Open questions:
- How stable are rankings as web content and model capabilities evolve?
- Can smaller models achieve similar evaluation quality?
- What is the correlation between quality scores and actual user satisfaction?
Limitations
The framework is largely English-centric, with benchmark tasks and evidence sources grounded in English-speaking information ecosystems. The agentic evaluation pipeline also incurs substantial computational costs due to frequent interactions with frontier models for quality scoring and fact verification.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Du, M. et al. (2025). DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv preprint. arXiv
[2] Wan, H. et al. (2025). DeepResearch Arena: The First Exam of LLMs' Research Abilities via Seminar-Grounded Tasks. arXiv preprint. arXiv
[3] Gou, B. et al. (2025). Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge. arXiv preprint. arXiv
[4] Mialon, G. et al. (2024). GAIA: A Benchmark for General AI Assistants. ICLR 2024. arXiv
[5] Wang, J. et al. (2025). LiveResearchBench: A Live Benchmark for User-Centric Deep Research. arXiv preprint. arXiv
[6] Wei, J. et al. (2024). Long-form Factuality in Large Language Models. NeurIPS 2024. arXiv


