Gold Medal at IMO and IOI: DeepSeek-V3.2 Matches GPT-5 with Open Weights
An open-source model just won gold at the International Math and Informatics Olympiads while cutting inference costs nearly in half.
The gap between open-source and proprietary language models has been widening, not converging. While GPT-5 and Gemini-3.0-Pro have pushed the frontier of AI reasoning, open models have struggled to keep pace on complex tasks. DeepSeek-AI addresses this head-on with DeepSeek-V3.2, an open-weight model whose high-compute variant, DeepSeek-V3.2-Speciale, achieves gold-medal performance at both the 2025 International Mathematical Olympiad (IMO) and International Olympiad in Informatics (IOI) while the base model matches GPT-5 on key reasoning benchmarks.
Building on the architecture of DeepSeek-V3 [1] and the reinforcement learning breakthroughs of DeepSeek-R1 [2], the researchers identify three critical deficiencies holding back open models: inefficient vanilla attention for long sequences, insufficient post-training compute, and weak agentic generalization. DeepSeek-V3.2 tackles all three through a new sparse attention mechanism, massive RL training scale, and a novel synthetic task generation pipeline.
DeepSeek Sparse Attention: From O(L^2) to O(Lk)
The architectural cornerstone of DeepSeek-V3.2 is DeepSeek Sparse Attention (DSA), which reduces core attention complexity from quadratic O(L^2) to linear O(Lk), where k is the number of selected tokens (2048 by default). DSA consists of two components: a lightweight lightning indexer that computes relevance scores between query and key tokens, and a fine-grained token selection mechanism that retrieves only the top-k most relevant key-value entries for attention computation.
The lightning indexer uses multiple heads with ReLU activation and can be implemented in FP8 for computational efficiency. Critically, DSA is instantiated under Multi-Latent Attention (MLA) [3] in MQA mode, where each latent vector is shared across all query heads, enabling efficient implementation at the kernel level.
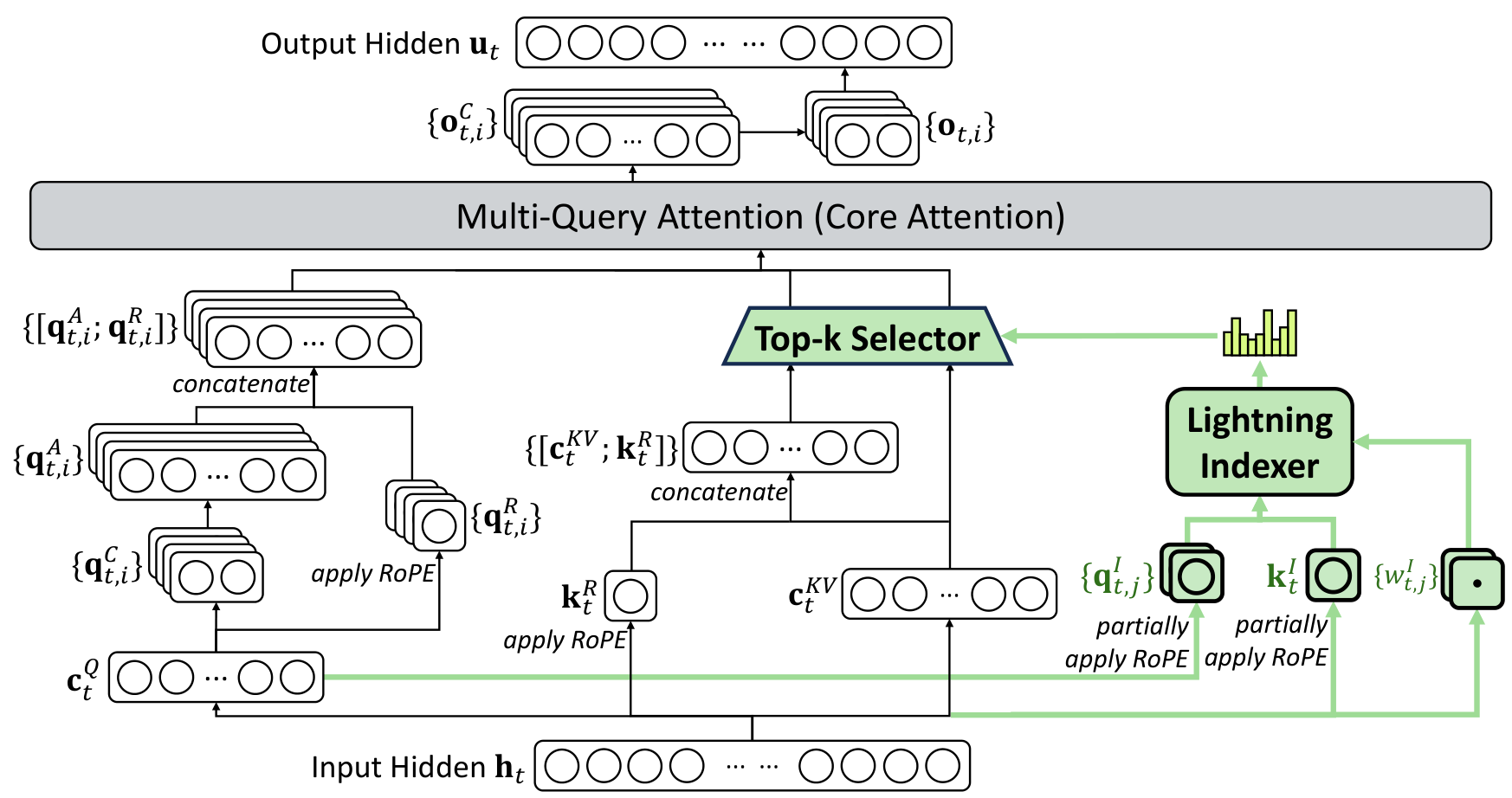 DSA ArchitectureThe DeepSeek Sparse Attention mechanism showing the lightning indexer, top-k selector, and multi-query attention core under MLA.
DSA ArchitectureThe DeepSeek Sparse Attention mechanism showing the lightning indexer, top-k selector, and multi-query attention core under MLA.
The model undergoes two-stage continued pre-training from DeepSeek-V3.1-Terminus: a dense warm-up stage (1000 steps, 2.1B tokens) to initialize the indexer using KL-divergence alignment with dense attention, followed by sparse training (15000 steps, 943.7B tokens) where all parameters adapt to the sparse pattern.
Post-Training at Unprecedented Scale
DeepSeek-V3.2 allocates post-training compute exceeding 10% of the pre-training cost, a scale unprecedented for open models. The training uses Group Relative Policy Optimization (GRPO) with several stability improvements: unbiased KL estimation to eliminate gradient bias, off-policy sequence masking to handle stale rollout data, and Keep Routing to ensure consistent expert assignments in the MoE architecture.
The post-training employs specialist distillation across six domains (math, programming, reasoning, general agentic, agentic coding, agentic search), where each specialist generates domain-specific training data. Mixed RL training then merges reasoning, agent, and alignment objectives in a single stage.
Large-Scale Agentic Task Synthesis
To enable reasoning in tool-use scenarios, the researchers developed a pipeline that generates 1,827 distinct environments and 85,000 complex prompts. An automatic environment-synthesis agent creates task-oriented environments by: (1) retrieving relevant data using bash and search tools, (2) synthesizing task-specific tool functions, and (3) iteratively increasing task difficulty while maintaining automatic verifiability.
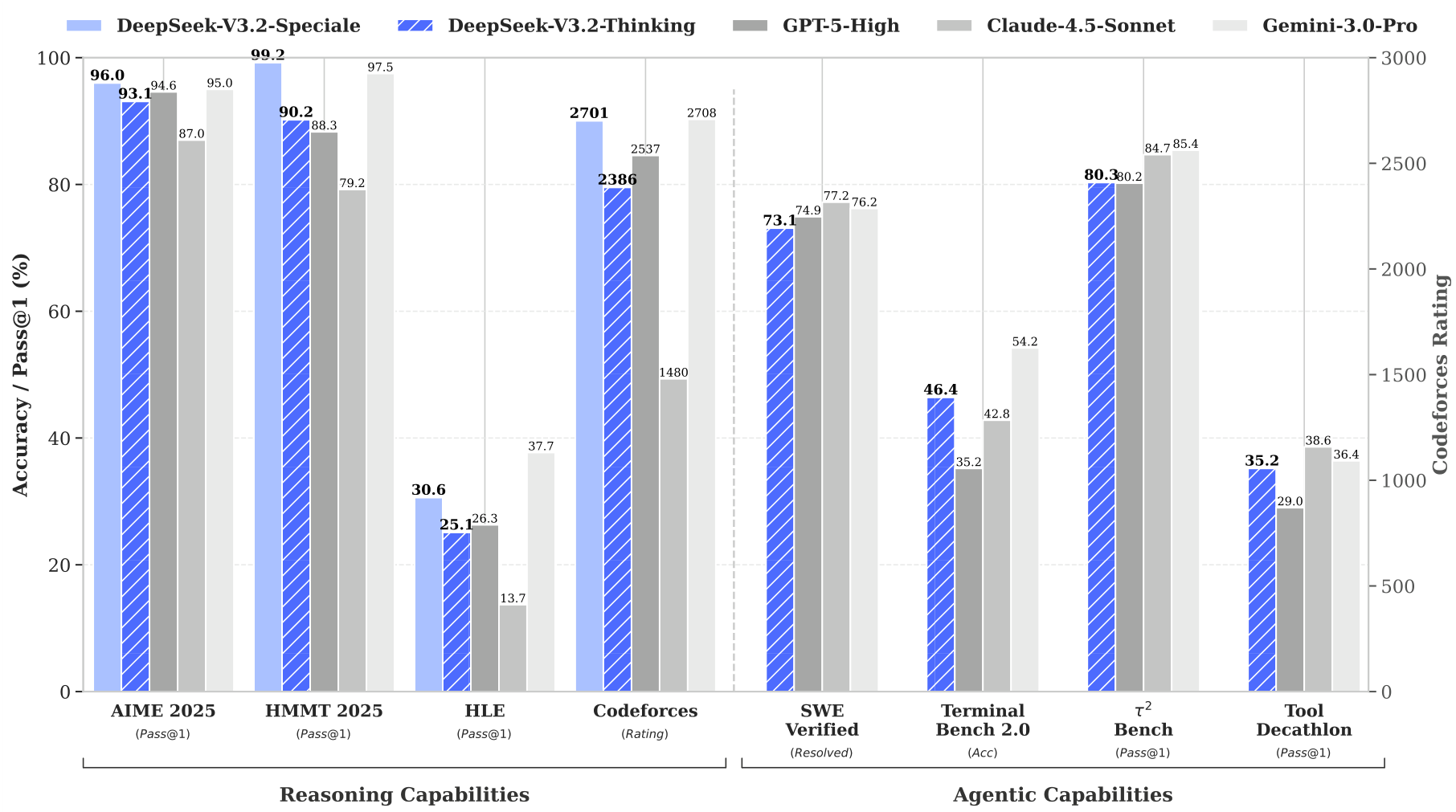 Benchmark ResultsPerformance comparison of DeepSeek-V3.2 against GPT-5, Claude-4.5-Sonnet, and Gemini-3.0-Pro across reasoning and agentic benchmarks.
Benchmark ResultsPerformance comparison of DeepSeek-V3.2 against GPT-5, Claude-4.5-Sonnet, and Gemini-3.0-Pro across reasoning and agentic benchmarks.
A key innovation is thinking context management for tool-calling: historical reasoning content is retained across tool calls until a new user message arrives, eliminating redundant re-reasoning while preserving tool call history.
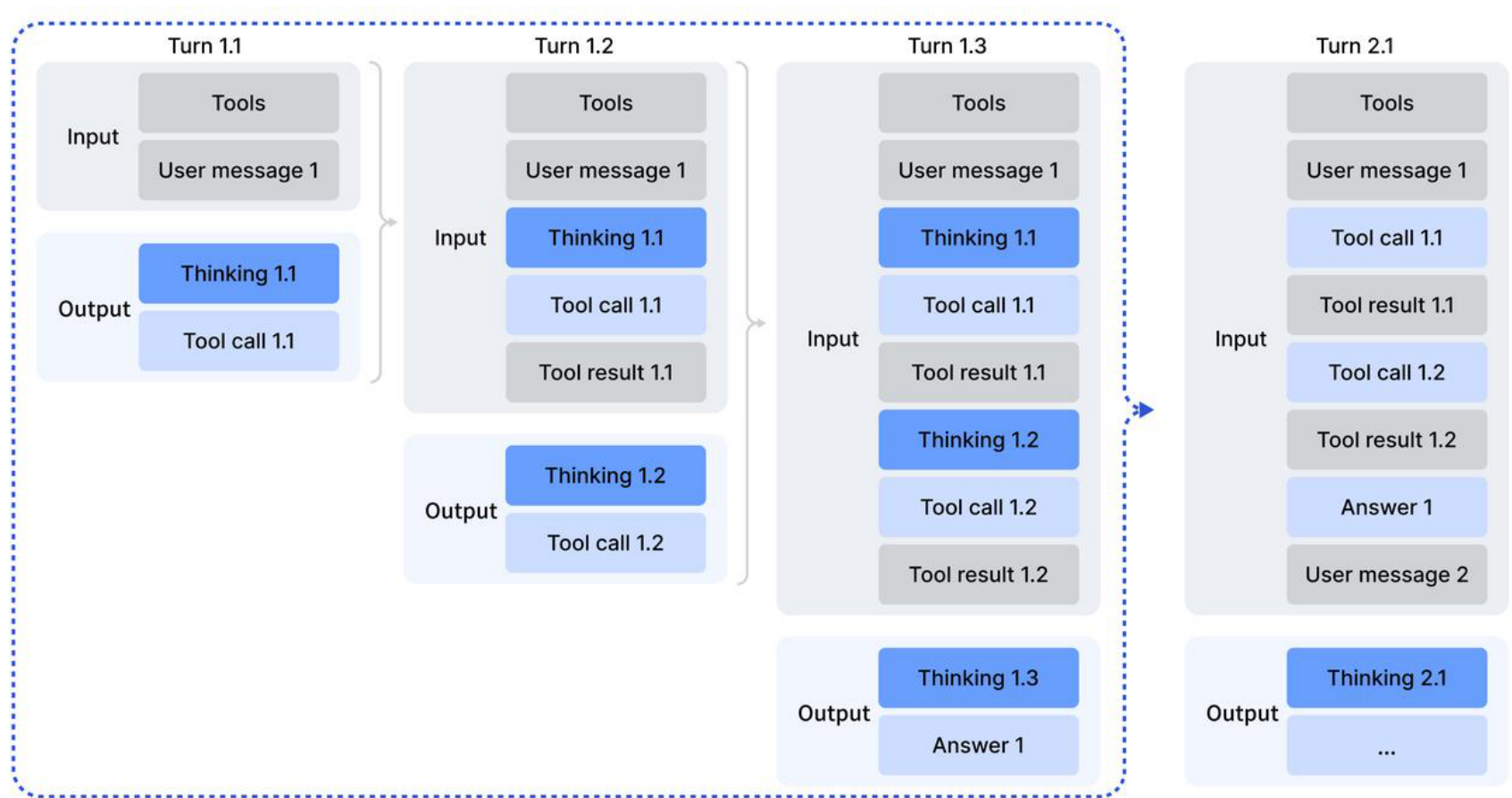 Thinking ContextThe thinking retention mechanism showing how reasoning content persists across tool calls but resets on new user messages.
Thinking ContextThe thinking retention mechanism showing how reasoning content persists across tool calls but resets on new user messages.
Results: Gold Medals and GPT-5 Parity
The base DeepSeek-V3.2 model achieves 93.1% on AIME 2025 (vs GPT-5's 94.6%) and 92.5% on HMMT February 2025 (vs GPT-5's 88.3%). On coding benchmarks, it reaches a Codeforces rating of 2386, and 73.1% on SWE-Verified. The high-compute variant DeepSeek-V3.2-Speciale pushes further:
- 96.0% on AIME 2025 (exceeding GPT-5)
- 99.2% on HMMT February 2025 (exceeding Gemini-3.0-Pro's 97.5%)
- Gold medal at IMO 2025 (35/42 points)
- Gold medal at IOI 2025 (492/600 points, ranked 10th)
On agentic benchmarks, DeepSeek-V3.2 achieves 46.4% on Terminal Bench 2.0 (exceeding GPT-5's 35.2%) and 67.6% on BrowseComp with context management (vs GPT-5's 54.9%). DSA provides significant inference cost reduction at long contexts, with Figure 3 showing substantially lower cost per million tokens compared to DeepSeek-V3.1-Terminus at 128K context length. The model is available through the official API at deepseek.com and as open weights on HuggingFace.
 Inference CostsCost per million tokens for prefilling and decoding across different context lengths, showing DSA's efficiency advantage at long contexts.
Inference CostsCost per million tokens for prefilling and decoding across different context lengths, showing DSA's efficiency advantage at long contexts.
Research Context
This work builds on DeepSeek-V3 [1] for the base MoE architecture and MLA, and DeepSeek-R1 [2] for the pure RL approach to reasoning capability.
What's genuinely new: DSA achieving O(Lk) complexity with dense attention parity; post-training compute at 10%+ of pretraining (unprecedented for open models); automatic environment synthesis generating 1,827 verifiable task environments; thinking context management for tool-calling scenarios.
Compared to Gemini-3.0-Pro, DeepSeek-V3.2-Speciale exceeds performance on math competitions but requires 2-3x more tokens for similar quality. Use this model when open weights are required, deployment cost is critical, or competition-level reasoning is the primary need. For scenarios requiring maximum token efficiency or multimodal capabilities, Gemini remains the stronger choice.
Open questions: How does DSA scale beyond 128K to million-token contexts? Can the token efficiency gap with Gemini be closed? What's the optimal balance between serial context management and parallel test-time scaling?
Check out the Paper, GitHub, and HuggingFace Models. All credit goes to the researchers.
References
[1] DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. arXiv preprint. arXiv
[2] DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Nature. arXiv
[3] DeepSeek-AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint. arXiv


