56.7% on OSWorld: EvoCUA's Evolutionary Training Beats Closed-Source Computer Use Agents
Meituan's 32B-parameter model beats models twice its size and closed-source competitors by teaching itself through millions of simulated computer interactions.
Computer use agents are rapidly moving from research curiosity to production deployment, with OpenAI, Anthropic, and ByteDance all shipping proprietary solutions. But open-source alternatives have consistently lagged behind, with the previous best model (OpenCUA-72B [1]) reaching only 45.0% on the OSWorld benchmark [2] -- far from the 62.9% achieved by Claude 4.5 Sonnet [3]. The fundamental bottleneck is not model architecture but training data: static datasets of human demonstrations cannot capture the causal dynamics of long-horizon computer interaction.
Researchers from Meituan, Fudan University, and Tongji University now present EvoCUA, a native computer use agent that breaks through this data ceiling by replacing static imitation with a self-sustaining evolutionary learning cycle. Their 32B-parameter model achieves 56.7% on OSWorld -- a new open-source state-of-the-art that outperforms even the closed-weights UI-TARS-2 [4] (53.1%) while using only 50 interaction steps compared to competitors' 100.
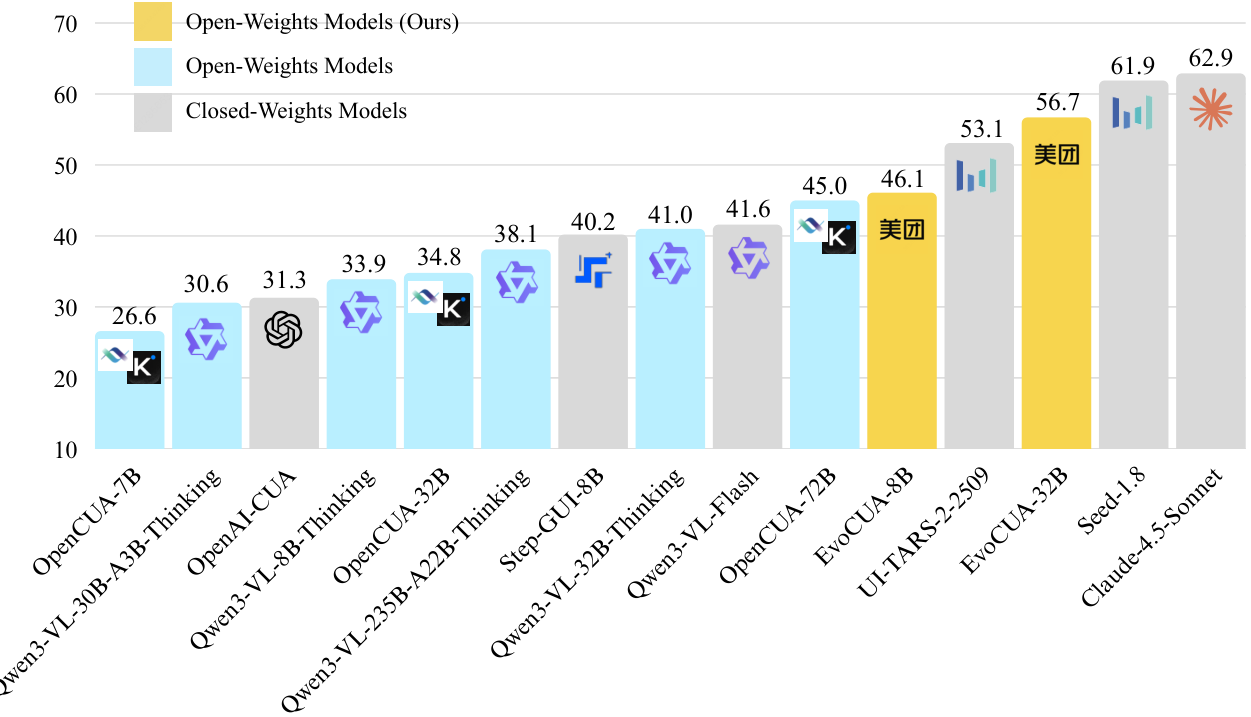 OSWorld ResultsPerformance comparison on OSWorld-Verified showing EvoCUA-32B achieving 56.7% success rate, surpassing all open-weights and several closed-weights models.
OSWorld ResultsPerformance comparison on OSWorld-Verified showing EvoCUA-32B achieving 56.7% success rate, surpassing all open-weights and several closed-weights models.
The Core Idea: Evolution Over Imitation
The key insight behind EvoCUA is a paradigm shift from data scaling to experience scaling. Rather than collecting more static demonstrations, the system generates its own training tasks, executes them at massive scale in parallel sandboxes, and learns from both successes and failures in an iterative cycle. This mirrors how humans learn computer tasks -- through trial, error, and refinement -- rather than memorizing fixed scripts.
The approach integrates three core modules into a closed loop: a Verifiable Synthesis Engine that creates tasks with ground-truth validators, a Scalable Interaction Infrastructure that orchestrates over 100,000 concurrent sandbox environments, and an Iterative Evolving Learning Strategy that converts raw interaction experience into policy improvements.
The Verifiable Synthesis Engine
To overcome data scarcity without sacrificing quality, EvoCUA employs a "Generation-as-Validation" paradigm. A foundation VLM acts as a task architect, simultaneously generating both natural language instructions and executable validator code. This dual-stream synthesis ensures every generated task has a precise, deterministic success condition -- eliminating the ambiguity of semantic reward matching that plagues other approaches.
The engine constructs tasks across a hierarchical domain taxonomy featuring diverse user personas (from educators designing slides to engineers conducting literature surveys) and injects real-world resources (images, audio, complex documents) to bridge the simulation-to-reality gap. A rigorous quality assurance pipeline filters outputs through consistency-based verification and tri-fold decontamination to prevent benchmark leakage.
100K Sandboxes: Infrastructure at Scale
The transition to experience-based learning demands infrastructure capable of massive parallel interaction. EvoCUA's platform orchestrates 100,000+ concurrent sandboxes using a hybrid architecture: QEMU-KVM virtual machines nested within Docker containers, managed by an asynchronous gateway achieving hundreds of thousands of routing requests per minute.
Each sandbox runs a customized Ubuntu 22.04 image with deterministic calibration -- HID patching for input consistency, font injection for rendering stability, and runtime hardening for reliability. The distributed scheduler supports burst scaling, bootstrapping tens of thousands of instances within one minute to match the demands of on-policy reinforcement learning.
 InfrastructureScalable Infrastructure architecture showing the asynchronous gateway, distributed scheduler, and parallel sandbox clusters using QEMU-KVM virtualization for high-fidelity environments.
InfrastructureScalable Infrastructure architecture showing the asynchronous gateway, distributed scheduler, and parallel sandbox clusters using QEMU-KVM virtualization for high-fidelity environments.
Learning from Failure: Dual-Paradigm DPO
EvoCUA's training progresses through three stages. First, a lightweight cold-start phase (~1K trajectories) establishes the unified action space and structured reasoning patterns. Second, Rejection Sampling Fine-Tuning (RFT) consolidates successful experiences using dynamic compute budgeting that focuses resources on boundary tasks where the agent oscillates between success and failure.
The most innovative component is the third stage: Dual-Paradigm DPO for learning from failures. When the system identifies a critical error in a trajectory, it constructs structured preference pairs across two paradigms. Paradigm I (Action Correction) replaces the rejected action with an optimal alternative. Paradigm II (Reflection) trains the agent to halt after errors, observe the unexpected state, and formulate recovery plans rather than blindly continuing.
 Dual-Paradigm DPOOverview of the preference construction process showing the critical forking point and two learning paradigms: Action Correction (replacing errors) and Reflection (learning to recover from unexpected states).
Dual-Paradigm DPOOverview of the preference construction process showing the critical forking point and two learning paradigms: Action Correction (replacing errors) and Reflection (learning to recover from unexpected states).
Results: Closing the Open-Source Gap
On the OSWorld benchmark, EvoCUA-32B achieves 56.7% success rate with a strict 50-step budget -- surpassing the previous open-source SOTA (OpenCUA-72B, 45.0%) by +11.7% and outperforming the closed-weights UI-TARS-2 (53.1%) by +3.6%. Under equivalent 50-step constraints, the gap to Claude 4.5 Sonnet (58.1%) narrows to just 1.4%.
The approach demonstrates remarkable parameter efficiency: EvoCUA-8B (46.1%) surpasses OpenCUA-72B despite being 9x smaller. A controlled comparison with Step-GUI-8B [5] -- trained on the identical Qwen3-VL-8B backbone -- isolates a +5.9% gain purely from the evolutionary training paradigm.
Ablation studies confirm each component's contribution: the unified action space (+4.84%), cold start (+2.62%), RFT (+3.13%), offline DPO (+3.21%), and iterative training (+1.90%). Experience scaling experiments show consistent gains from 20K to 1M samples, with the full RFT pipeline achieving +8.12% over baseline.
Research Context
This work builds on the trajectory established by OpenCUA [1] and UI-TARS-2 [4], which pioneered native computer use agents using static imitation and multi-turn RL respectively. The RLVR paradigm introduced by DeepSeek-R1 [6] -- demonstrating that RL can verify complex reasoning without dense supervision -- provides the theoretical foundation that EvoCUA extends to multimodal agentic interaction.
What is genuinely new: The co-generation of tasks with executable validators (Generation-as-Validation), the Dual-Paradigm DPO combining action correction with reflective recovery, and the engineering achievement of 100K+ concurrent deterministic sandboxes for on-policy learning.
Compared to UI-TARS-2, which relies on demonstration-heavy training at 100 steps, EvoCUA achieves superior results with autonomous synthesis and half the step budget. For scenarios requiring the absolute highest reliability, Claude 4.5 Sonnet [3] still leads at 62.9% (100 steps), though the gap is narrowing rapidly.
Open questions: Can the evolutionary cycle continue yielding gains beyond current iterations, or will it plateau? How well does the approach transfer to other agent benchmarks (WebArena, AndroidWorld)? Can the observed regression in general VLM capabilities (MMMU drops from 78.1 to 68.1 on the Qwen3-VL backbone) be eliminated while maintaining agent performance?
Check out the Paper, GitHub, and Model Weights. All credit goes to the researchers.
References
[1] Wang, X. et al. (2025). OpenCUA: Open Foundations for Computer-Use Agents. arXiv preprint. arXiv
[2] Xie, T. et al. (2024). OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. NeurIPS 2024. Paper
[3] Anthropic. (2025). Claude 4.5 Sonnet. Anthropic Blog. Link
[4] Wang, H. et al. (2025). UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning. arXiv preprint. arXiv
[5] Yan, H. et al. (2025). Step-GUI Technical Report. arXiv preprint. arXiv
[6] Guo, D. et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint. arXiv


