First Holistic OCR Model: OCRVerse Unifies Document Parsing and Code Generation
What if your OCR model could not only read documents but also write the Python code to recreate charts and the HTML to rebuild web pages?
Current OCR technology faces a fundamental fragmentation problem. Traditional approaches excel at extracting text from documents but cannot interpret visual content like charts, web pages, or scientific plots. Building on the foundation of GOT-OCR [1] and the Qwen3-VL architecture [2], researchers from Meituan have developed OCRVerse, the first end-to-end model that unifies text-centric and vision-centric OCR in a single 4B-parameter system.
Unlike specialized systems such as dots.ocr [4] which focus exclusively on document layout parsing, or pipeline-based approaches like PaddleOCR-VL [5] optimized for text extraction, OCRVerse can both parse documents into Markdown and generate Python code from charts, HTML from web pages, LaTeX from scientific plots, and even chemical notation from molecular diagrams.
The Holistic OCR Challenge
Existing OCR methods fall into two distinct camps. Text-centric approaches recognize characters from images or scanned documents, producing text or Markdown output. Vision-centric approaches interpret information-dense visuals like charts and web interfaces, but require code-level representations (Python, HTML, LaTeX) to capture semantic relationships embedded in visual structures.
The fragmentation means practitioners need separate systems for different content types. A document containing both text and an embedded chart requires multiple processing pipelines. OCRVerse addresses this by creating a unified representation space that handles both character-level recognition and code-level generation.
 Data CoverageComprehensive data coverage showing nine text-centric document types (left) and six vision-centric specialized scenarios (right) that OCRVerse handles.
Data CoverageComprehensive data coverage showing nine text-centric document types (left) and six vision-centric specialized scenarios (right) that OCRVerse handles.
Comprehensive Data Engineering
A key contribution is the systematic data engineering pipeline covering 15 distinct data types. The text-centric data includes open-source datasets (LSVT, TextOCR, PDFA, DocStruct4M), real-world PDF documents from books, magazines, and academic papers, and synthetically generated examination questions and formulas. The vision-centric data draws from chart-to-code datasets (MCD, MSRL), webpage structure data (Web2M, Web2Code), SVG graphics (UniSVG-ISVGEN), and mathematical diagrams (DaTikZ-v3, Cosyn-400k).
The pipeline employs VLM-based annotation using Qwen2.5-VL-72B and GOT for text-centric data, while vision-centric domains use self-annotation bootstrapping - training specialized models on cleaned subsets, then using those models to annotate remaining data at scale.
Two-Stage SFT-RL Training
OCRVerse employs a novel two-stage training methodology built on Qwen3-VL-4B. The approach freezes the visual encoder and vision-language projector while training only the language model parameters.
Stage 1: Supervised Fine-Tuning (SFT) directly mixes data from all 15 domains to establish foundational cross-domain knowledge. The training covers nine text-centric document types (natural scenes, books, magazines, papers, reports, slides, exam papers, notes, newspapers) and six vision-centric scenarios (charts, webpages, icons, geometry, circuits, molecules).
Stage 2: Reinforcement Learning (RL) applies domain-specific reward strategies using GRPO [7] for policy optimization. This is where OCRVerse introduces its key innovation: different reward mechanisms for different content types.
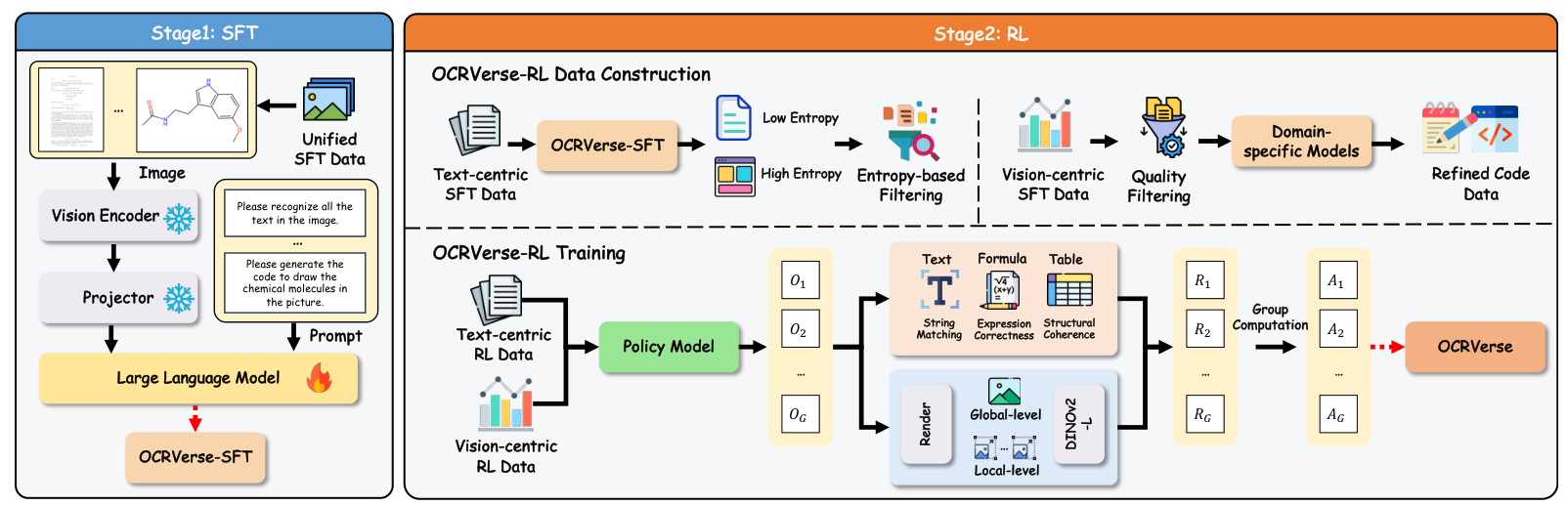 Training PipelineThe two-stage training approach with unified SFT followed by domain-specific RL with personalized rewards for text-centric and vision-centric optimization.
Training PipelineThe two-stage training approach with unified SFT followed by domain-specific RL with personalized rewards for text-centric and vision-centric optimization.
Domain-Specific Reward Design
The RL stage's reward design is what enables OCRVerse to handle diverse output formats without domain interference.
For text-centric domains, rule-based rewards measure accuracy directly:
- Plain text: Normalized edit distance (1 - edit_distance)
- Formulas: BLEU score after LaTeX normalization
- Tables: TEDS (Tree Edit Distance-based Similarity) for structural coherence
For vision-centric domains, visual fidelity rewards leverage DINOv2 [8] embeddings to compare rendered outputs against ground truth images. The model uses a multi-scale approach combining global-level similarity from downsampled thumbnails with local-level similarity from image patches. This is crucial because text-based metrics like BLEU poorly correlate with rendered visual quality for code outputs.
Benchmark Results
On OmniDocBench v1.5, the comprehensive document parsing benchmark, OCRVerse achieves 89.23 overall, outperforming general-purpose models like Qwen2.5-VL-72B (87.02) and Gemini-2.5 Pro (88.03) despite having significantly fewer parameters. While this trails the current SOTA HunyuanOCR (94.10), that system cannot perform vision-centric code generation.
The vision-centric results demonstrate OCRVerse's unique capabilities. On Image2LaTeX-plot, it achieves 88.7% rendering success rate and 63.1 EMS, significantly outperforming GPT-5 (78.7%, 57.4) and all other models evaluated. For ChartMimic chart-to-code generation, it scores 72.2 low-level and 75.4 high-level, competitive with Qwen2.5-VL-72B (72.7 low-level) while using 18x fewer parameters.
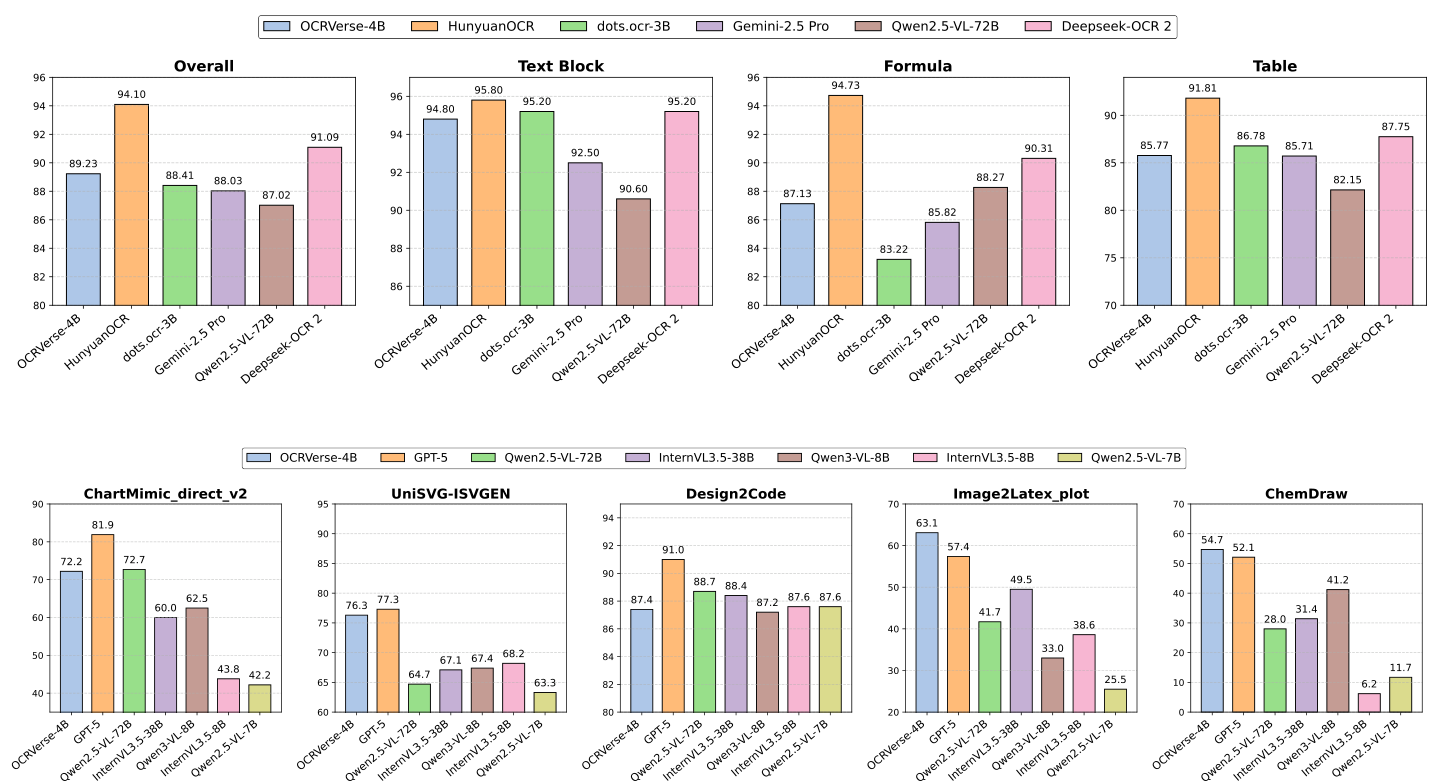 Performance ComparisonResults on text-centric OCR tasks (top row) and vision-centric code generation tasks (bottom row) showing competitive performance across both domains.
Performance ComparisonResults on text-centric OCR tasks (top row) and vision-centric code generation tasks (bottom row) showing competitive performance across both domains.
On UniSVG-ISVGEN for SVG generation, OCRVerse achieves 76.3, second only to GPT-5 (77.3) among all evaluated models. For ChemDraw molecular structure recognition, it reaches 54.7 Tanimoto similarity, exceeding GPT-5's 52.1.
Research Context
This work builds on GOT-OCR [1], which pioneered unified end-to-end document understanding, and extends the Qwen3-VL [2] architecture with specialized training for holistic OCR. The domain-specific reward approach draws from DeepSeekMath's GRPO [7] policy optimization.
What's genuinely new: OCRVerse is the first model to unify text-centric and vision-centric OCR capabilities. The visual fidelity rewards using DINOv2 for code generation quality represent a novel approach to evaluating generated code by its rendered output rather than text matching. The systematic data engineering covering 15 distinct data types enables a single model to handle document parsing, chart-to-Python, web-to-HTML, and scientific plot-to-LaTeX.
Compared to HunyuanOCR [3], which achieves SOTA on text-centric benchmarks (94.10 vs 89.23), OCRVerse trades approximately 5 points on document parsing to gain capabilities that no other model offers. For scenarios requiring pure text extraction with maximum accuracy, specialized systems remain superior. For unified workflows processing diverse visual content, OCRVerse is currently the only option.
Open questions raised by this work include: How do the 15 data types interact during training - is there positive transfer or interference between domains? Can the visual fidelity reward approach extend to other code generation tasks beyond OCR? Would explicit layout tokens help close the gap on reading order tasks where OCRVerse (0.068) trails layout-aware models like dots.ocr (0.053)?
Limitations
The authors acknowledge several limitations. OCRVerse does not incorporate explicit layout-aware mechanisms, limiting its ability to capture fine-grained spatial relationships in complex multi-column documents. Table recognition (TEDS: 85.77) lags behind top models like HunyuanOCR (91.81). The current implementation processes single pages only, without multi-page document understanding.
Check out the Paper and GitHub. Model weights are available on HuggingFace. All credit goes to the researchers.
References
[1] Wei, H. et al. (2024). General OCR Theory: Towards OCR-2.0 via a Unified End-to-End Model. arXiv preprint. arXiv
[2] Bai, S. et al. (2025). Qwen3-VL Technical Report. arXiv preprint. arXiv
[3] Wei, H. et al. (2026). DeepSeek-OCR 2: Visual Causal Flow. arXiv preprint. arXiv
[4] Li, Y. et al. (2025). dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model. arXiv preprint. arXiv
[5] Cui, C. et al. (2025). PaddleOCR-VL: Boosting Multilingual Document Parsing. arXiv preprint. arXiv
[6] Yang, C. et al. (2024). ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation. ICLR 2025. arXiv
[7] Shao, Z. et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint. arXiv
[8] Oquab, M. et al. (2023). DINOv2: Learning Robust Visual Features Without Supervision. arXiv preprint. arXiv


