FP8 Rollout Instability Solved: Jet-RL Unifies Precision for Stable RL Training
Mixed precision RL training breaks at long rollouts due to off-policy mismatch. Jet-RL unifies FP8 precision across training and rollout for 16% end-to-end speedup with stable convergence.
Reinforcement learning has become essential for training reasoning models like DeepSeek-R1 [1], but the computational cost is staggering. The rollout phase alone consumes over 70% of total training time, especially for long chain-of-thought generation. A common optimization is to use FP8 quantization during rollout to speed things up while keeping BF16 precision for training. But researchers from NVIDIA, MIT, UC Berkeley, and Stanford have discovered this approach is fundamentally broken for challenging tasks.
Building on the FP8 training techniques from COAT [2], a team led by Haocheng Xi introduces Jet-RL, a framework that enables truly on-policy FP8 reinforcement learning by unifying precision across both training and rollout phases. Implemented using vLLM for inference and VeRL for training, the framework achieves up to 41% faster training while maintaining stable convergence where the standard approach catastrophically fails. The work requires NVIDIA H100 GPUs or later for FP8 TensorCore support.
The Hidden Problem: Off-Policy Training
The standard approach of BF16-train-FP8-rollout seems reasonable: use high precision for the critical training updates and lower precision for the faster rollout generation. However, this creates a fundamental mismatch. The actor model generating rollouts in FP8 produces slightly different outputs than the BF16 model being trained. For short sequences, these differences are negligible. But as rollout length increases to 8K, 16K, or beyond, the cumulative errors compound.
The team demonstrated this failure mode across multiple models. When training Qwen3-8B-Base with 16K token rollouts, the BF16-train-FP8-rollout approach collapsed after just 20 training steps, while standard BF16 training continued learning normally. The problem is particularly severe on challenging tasks where the model lacks strong prior knowledge.
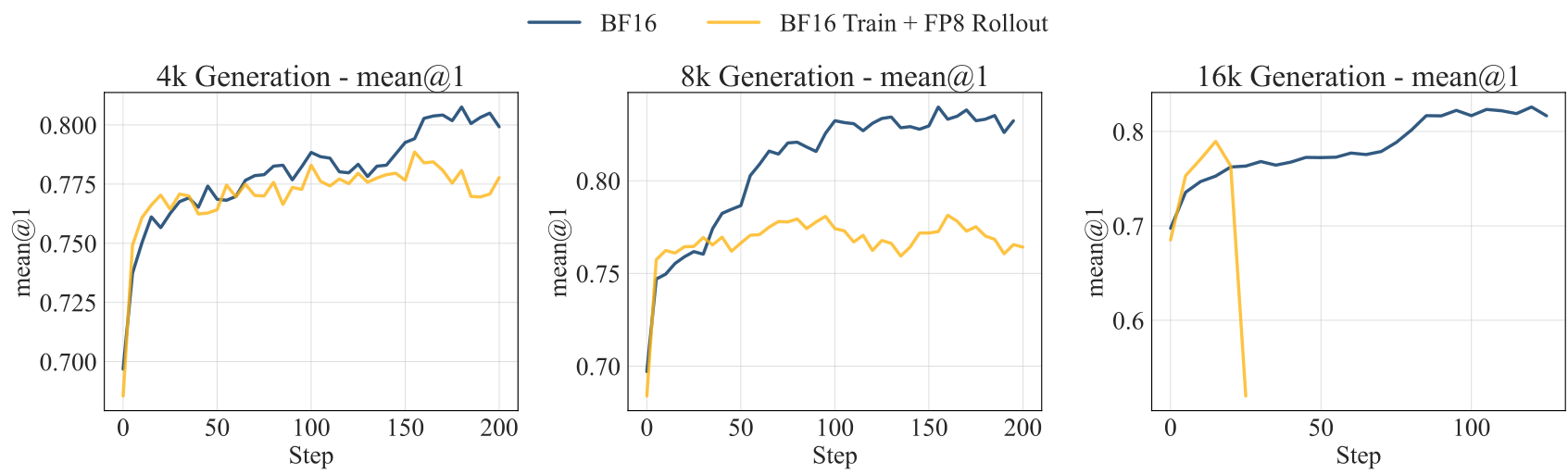 Training CurvesBF16-train-FP8-rollout fails catastrophically at 16K rollout length, while BF16 training remains stable.
Training CurvesBF16-train-FP8-rollout fails catastrophically at 16K rollout length, while BF16 training remains stable.
How Jet-RL Works: Unified Precision Flow
Jet-RL's key insight is that RL training relies on the on-policy assumption: the model must learn from data generated by its current policy. When training and rollout use different precisions, this assumption breaks. The solution is to enforce identical FP8 precision flow for both the training forward pass and inference rollout.
The framework models precision propagation as a directed graph where nodes represent operators and edges represent tensor precision. By ensuring the inference graph is a subgraph of the training forward graph with matching precision attributes, Jet-RL eliminates the policy mismatch entirely. The implementation uses vLLM as the inference engine and VeRL as the RL training framework, with DeepGEMM kernels for the quantized GEMM operations.
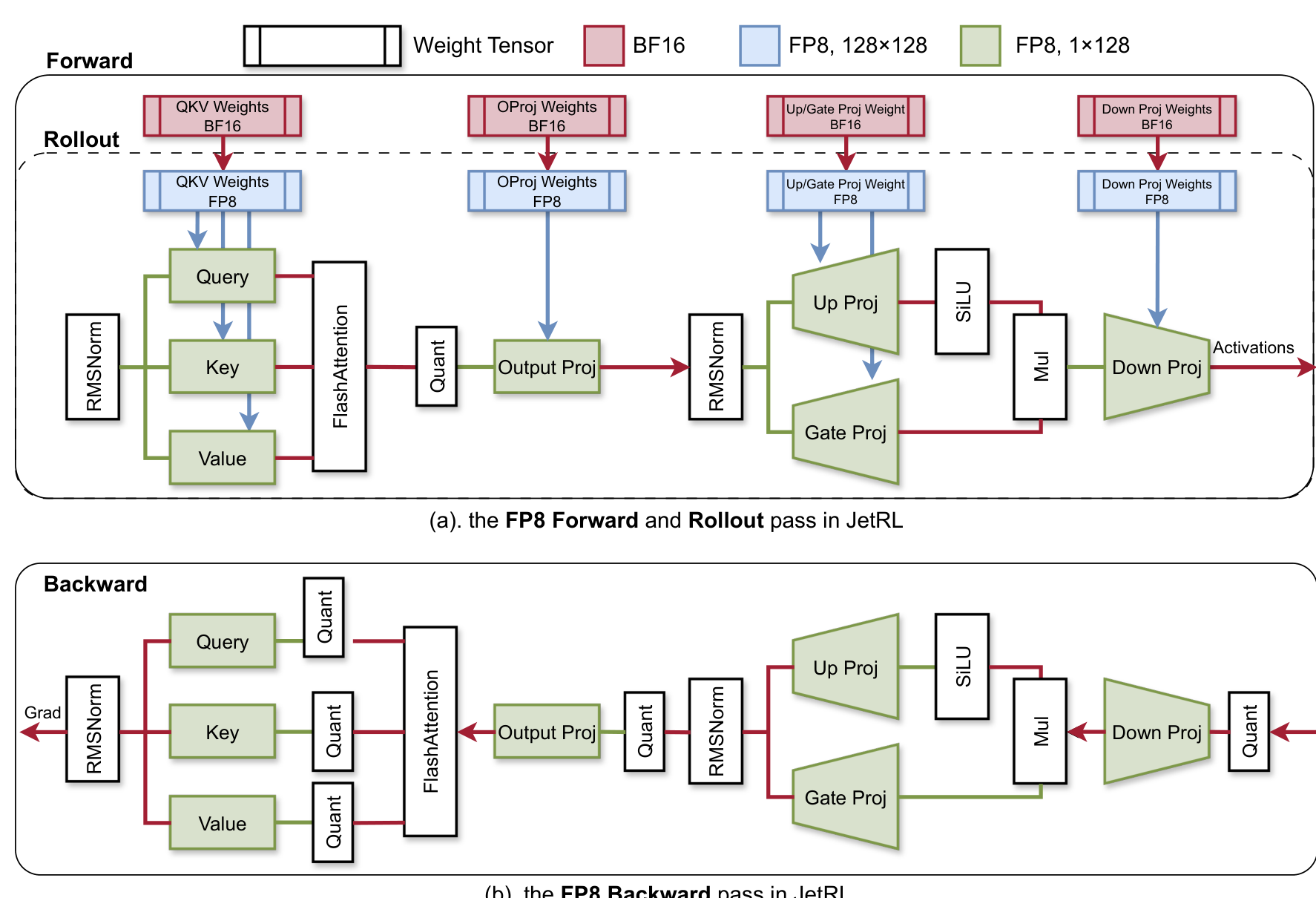 Jet-RL ArchitectureThe FP8 precision flow diagram showing unified quantization between forward/rollout and backward passes.
Jet-RL ArchitectureThe FP8 precision flow diagram showing unified quantization between forward/rollout and backward passes.
Quantization Strategy
For the GEMM operations in linear layers, Jet-RL adopts a mixed-granularity quantization scheme. Weights use 128x128 per-block quantization, while activations and gradients use 1x128 per-group quantization. This finer-grained approach, inspired by DeepSeek-V3, helps maintain training stability compared to per-tensor quantization.
The backward pass retains BF16 precision for gradients transported between operators, preserving model accuracy. However, activations saved for backward computation are stored in FP8, reducing memory overhead without compromising convergence.
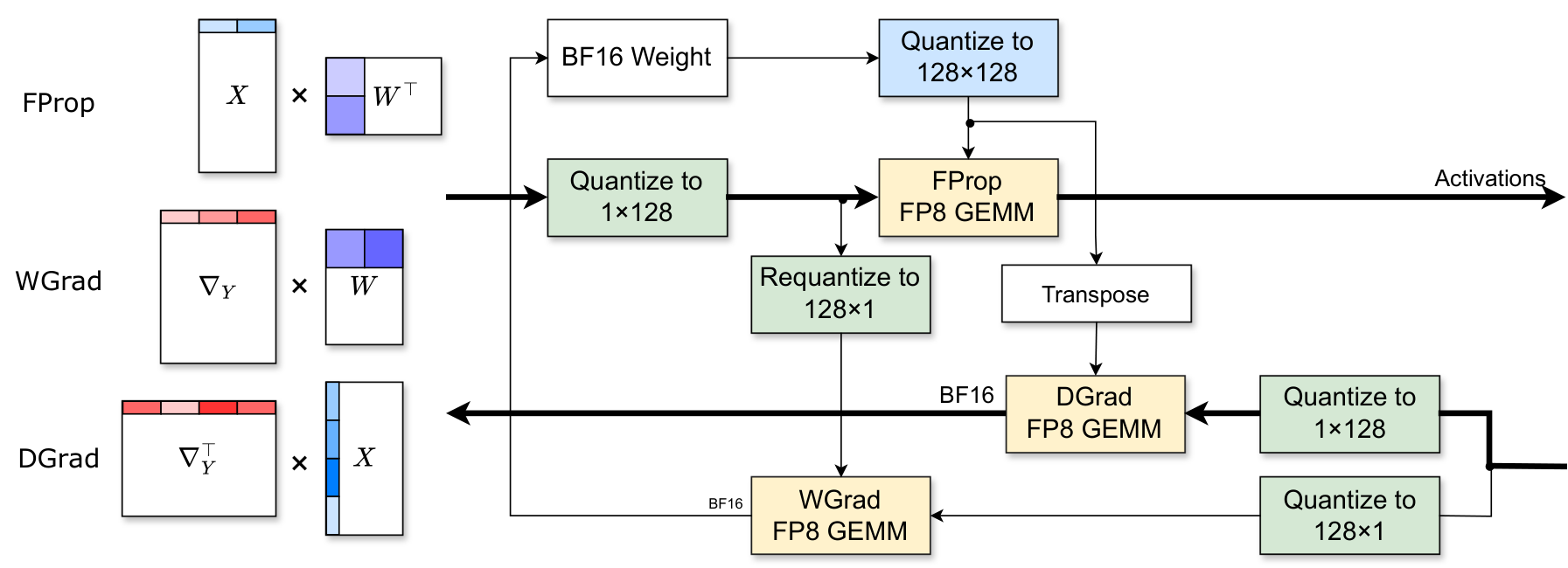 Quantization SchemeThe FProp GEMM uses (1x128) x (128x128) kernel while DGrad and WGrad use different granularities for stability.
Quantization SchemeThe FProp GEMM uses (1x128) x (128x128) kernel while DGrad and WGrad use different granularities for stability.
Performance Results
Jet-RL achieves significant speedups while maintaining stability across all tested configurations on NVIDIA H100 GPUs:
Training Efficiency:
- Up to 1.33x rollout phase speedup for 32B models
- Up to 1.41x training phase speedup for 8B models
- 1.16x end-to-end speedup for 8B model training
- 1.54x actor update speedup
- 1.80x reference model inference speedup
Accuracy Preservation: On the 8K rollout setting with GSM8K + MATH training, Jet-RL closes the gap to BF16 training to approximately 1%:
- Llama3.1-8B: 25.2% average (vs 23.2% BF16) - actually outperforms baseline
- Qwen2.5-7B: 55.9% average (vs 56.9% BF16) - BF16-train-FP8-rollout failed to converge
- Qwen3-8B-Base: 62.7% average (vs 63.8% BF16) - only 1.1% degradation
At 16K rollout length on the challenging DeepMATH dataset, Jet-RL achieved 53.7% average score compared to 54.6% for BF16, while BF16-train-FP8-rollout suffered a severe 10.3% degradation.
Research Context
This work builds on COAT [2], which established FP8 training techniques for pretraining and supervised fine-tuning, and VeRL/HybridFlow [3], which provides the RLHF infrastructure that Jet-RL optimizes. The quantization scheme draws from DeepSeek-V3's per-block approach.
What's genuinely new:
- First comprehensive study exposing failure modes of BF16-train-FP8-rollout
- Identification that precision mismatch causes off-policy training issues in RL
- Unified FP8 precision flow between training and rollout that maintains on-policy consistency
Compared to the standard BF16-train-FP8-rollout approach, Jet-RL trades approximately 1% accuracy for guaranteed convergence on long-horizon tasks where the baseline fails catastrophically. For teams training reasoning models with rollouts exceeding 8K tokens, Jet-RL is strictly better.
Open questions:
- How does Jet-RL compare to algorithmic solutions like Truncated Importance Sampling?
- Does the unified precision approach scale to 70B+ models?
- What is the optimal quantization granularity for different model architectures?
When to Use Jet-RL
Use Jet-RL when: training with long rollouts exceeding 8K tokens, target tasks are challenging relative to model capability, training stability is critical, or hardware supports FP8 (NVIDIA H100 or later).
Use standard BF16-train-FP8-rollout when: rollouts are short (under 4K tokens), the model already performs well on the target task, or simplicity is prioritized over stability.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Nature 645. arXiv
[2] Xi, H. et al. (2024). COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training. ICLR 2025. arXiv
[3] Sheng, G. et al. (2024). HybridFlow: A Flexible and Efficient RLHF Framework. arXiv preprint. arXiv


