Google Introduces Agentic Vision: Gemini 3 Flash Now Zooms, Annotates, and Investigates Images
Current vision models process images in a single glance and guess when they can't see details.
Frontier vision models typically process images in a single, static glance. When they miss fine-grained details—a serial number on a microchip, a distant street sign, or tiny text in a document—they guess. Building on the ReAct paradigm [1] that established interleaved reasoning and action for language models, Google DeepMind has introduced Agentic Vision in Gemini 3 Flash, a capability that treats image understanding as an active investigation rather than passive perception.
The approach delivers a consistent 5-10% quality boost across most vision benchmarks by combining visual reasoning with code execution. Rather than outputting an answer immediately, the model formulates a plan, executes Python code to manipulate or analyze images, and inspects the results before responding.
The Think-Act-Observe Loop
Agentic Vision introduces a three-phase loop into image understanding. First, the model analyzes the user query and formulates a multi-step plan (Think). Then it generates and executes Python code to actively manipulate images—cropping, rotating, annotating, or running calculations (Act). Finally, the transformed image is appended to the model's context window for inspection before generating a final response (Observe).
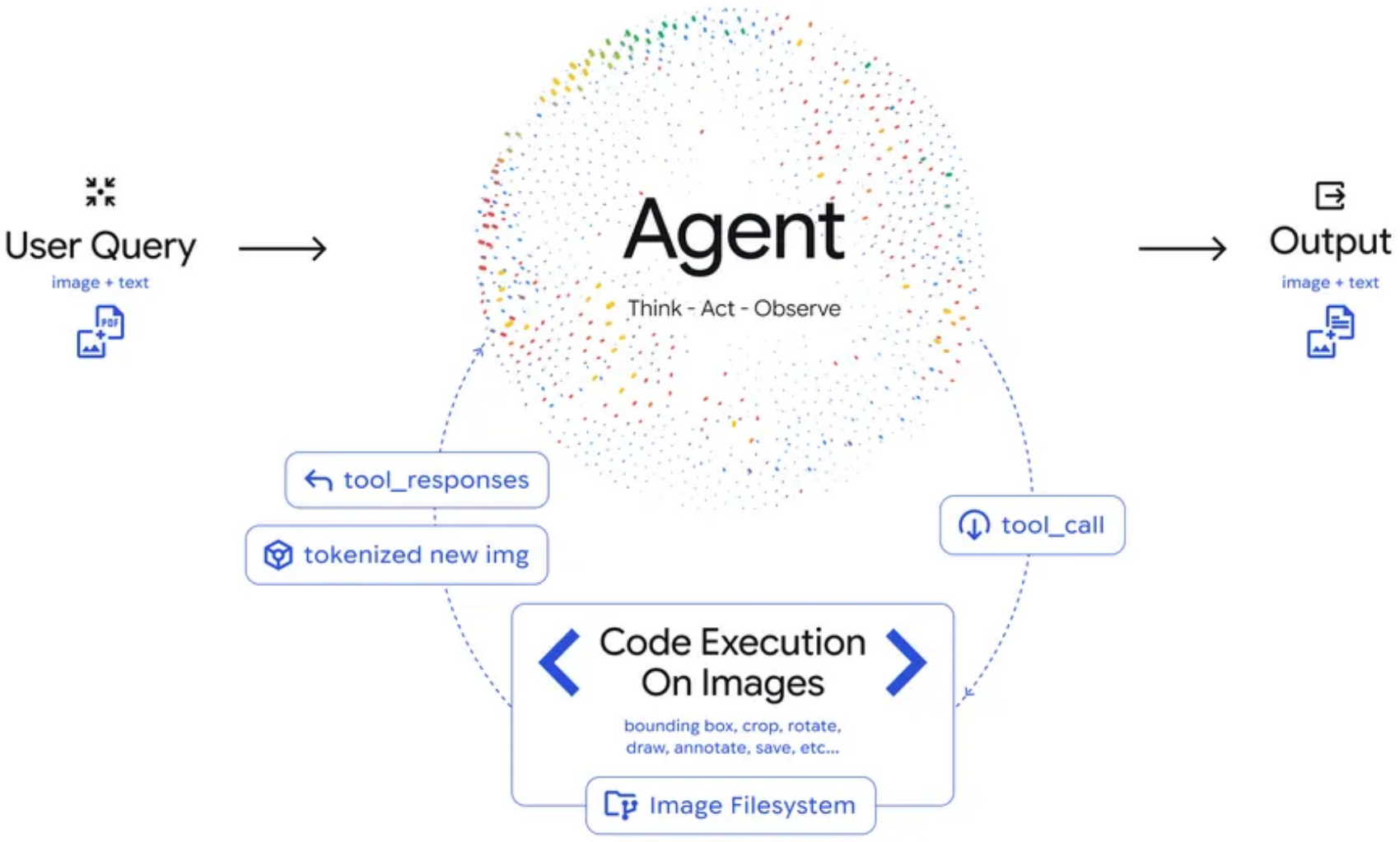 Architecture DiagramThe Agentic Vision architecture shows User Query input flowing to an Agent operating in a Think-Act-Observe loop, with Code Execution enabling image operations and an Image Filesystem for storing processed results.
Architecture DiagramThe Agentic Vision architecture shows User Query input flowing to an Agent operating in a Think-Act-Observe loop, with Code Execution enabling image operations and an Image Filesystem for storing processed results.
This differs from static multimodal approaches where the model processes an image once and generates a response. The agentic loop enables iterative refinement—if an initial crop doesn't reveal enough detail, the model can adjust and try again.
Visual Scratchpad: Drawing to Think
A key innovation is what the team calls a "visual scratchpad." When counting objects or verifying details, the model draws bounding boxes and annotations directly on the image. For a finger-counting task, it annotates each finger with a number, ensuring pixel-perfect accuracy rather than relying on potentially faulty visual estimation.
This approach offloads multi-step visual arithmetic to a deterministic Python environment, avoiding the hallucination problems that plague standard LLMs during complex counting or measurement tasks. The model's final answer is grounded in verifiable visual evidence.
Benchmark Performance
Enabling code execution with Gemini 3 Flash shows substantial improvements across multiple vision benchmarks:
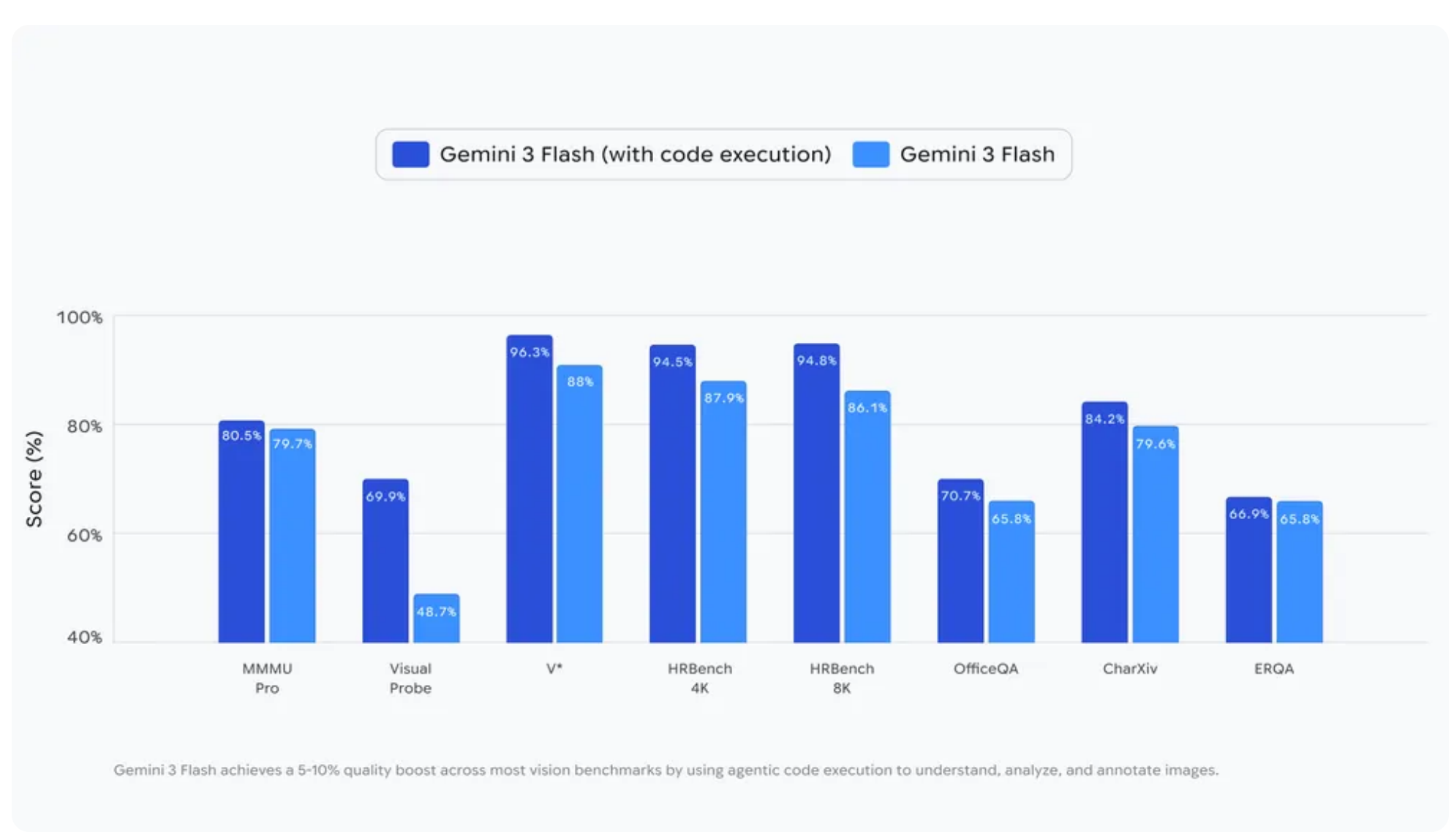 Benchmark ResultsBar chart comparing Gemini 3 Flash with and without code execution across eight vision benchmarks, showing consistent 5-10% quality improvements on most tasks.
Benchmark ResultsBar chart comparing Gemini 3 Flash with and without code execution across eight vision benchmarks, showing consistent 5-10% quality improvements on most tasks.
The strongest gains appear on tasks requiring fine-grained detail extraction. Visual Probe improved by 21.2 percentage points (48.7% to 69.9%), OfficeQA by 18.4 points (65.8% to 84.2%), and HRBench 8K by 15.4 points (70.7% to 86.1%).
On CharXiv, a benchmark testing chart understanding from scientific papers where GPT-4o achieved 47.1% and human experts reach 80.5% [5], Gemini 3 Flash with Agentic Vision scores 79.6%, approaching expert-level performance.
Not all benchmarks improved. HRBench 4K dropped from 94.8% to 87.0%, and ERQA fell from 96.3% to 65.8%. The regressions suggest code execution may overcomplicate tasks where direct reasoning suffices, or where medium-resolution images don't require active investigation.
Real-World Deployment
The capability is already deployed in production. PlanCheckSolver.com, a building plan validation service, reports a 5% accuracy improvement using Agentic Vision to verify construction documents. The feature is also starting to roll out in the Gemini app, and developers can enable it in Google AI Studio and Vertex AI by toggling the "Code Execution" option.
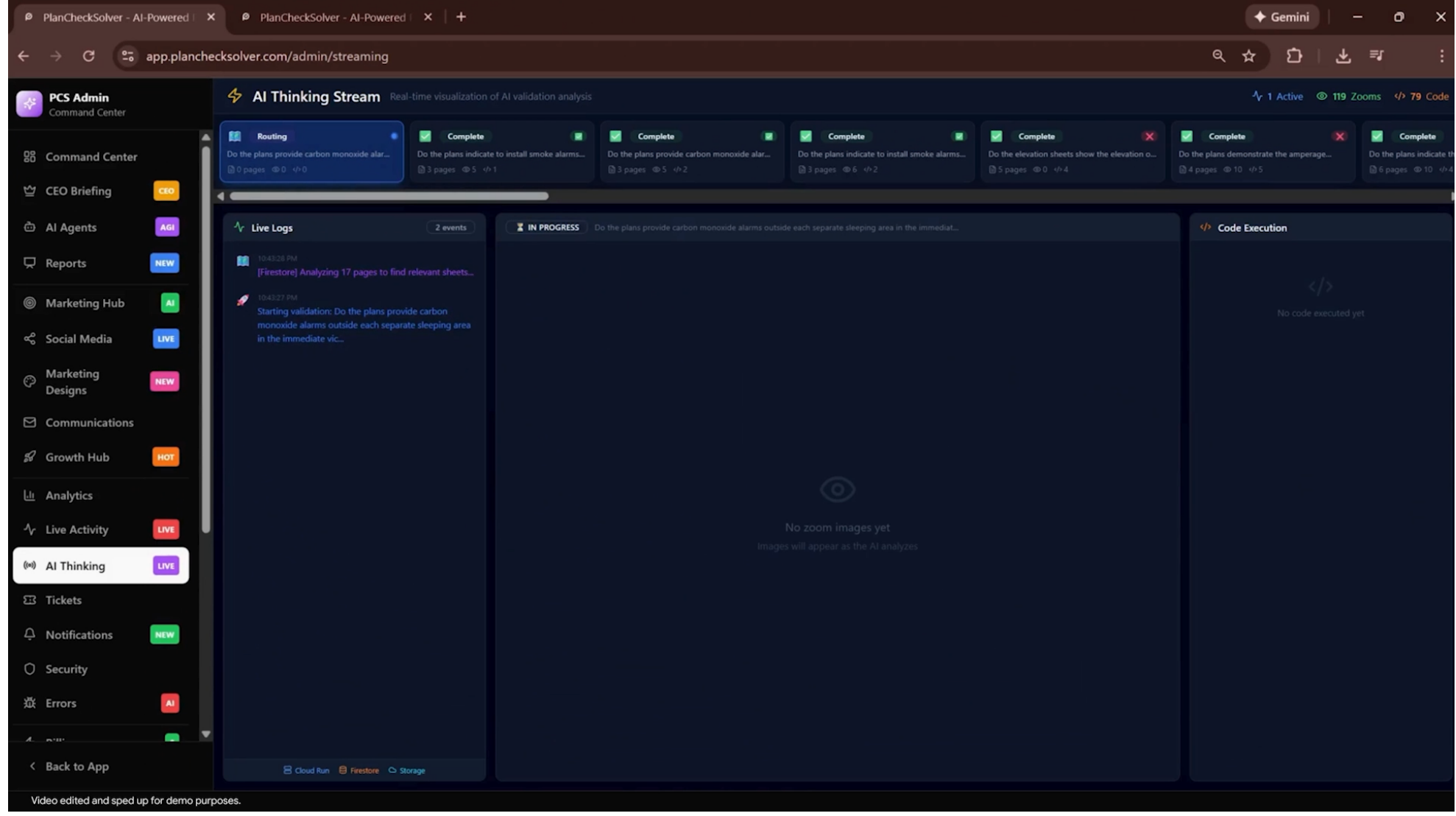 PlanCheckSolver DemoScreenshot of PlanCheckSolver.com's AI Thinking Stream showing the agentic code execution process with Live Logs and Code Execution panels during building plan validation.
PlanCheckSolver DemoScreenshot of PlanCheckSolver.com's AI Thinking Stream showing the agentic code execution process with Live Logs and Code Execution panels during building plan validation.
Research Context
This work extends the ReAct framework [1] to vision tasks and shares goals with V* [2], which introduced LLM-guided visual search for finding fine-grained details. Unlike training-free approaches like DC² [3] that achieve similar cropping and analysis through post-hoc processing, Agentic Vision trains implicit zooming behavior directly into the model.
What's genuinely new: The implicit zoom behavior is trained into the model rather than requiring explicit prompting. The visual scratchpad concept enables verifiable, grounded reasoning. And transformed images are appended back to the context window as tokenized data for iterative refinement.
Compared to Claude's Computer Use [4], Agentic Vision is more specialized for visual understanding tasks, while Claude offers broader general-purpose desktop automation. For pure visual analysis requiring fine-grained detail extraction, Agentic Vision appears superior; for multi-application workflows spanning beyond image analysis, Claude may offer more versatility.
Open questions:
- Why does code execution hurt performance on HRBench 4K and ERQA? What task characteristics cause regressions?
- What is the latency and computational overhead of agentic inference loops?
- Can the implicit zoom behavior be distilled to work without code execution at inference time?
Limitations
Some capabilities still require explicit prompt nudges. Rotating images or performing visual math isn't fully automatic yet. The approach is currently limited to Gemini 3 Flash—it's unclear how it scales to larger models. And the benchmark regressions on HRBench 4K and ERQA suggest the agentic approach can actively harm performance on certain task types.
The team notes future work will focus on making implicit behaviors fully automatic, equipping Gemini with additional tools like web search and reverse image search, and expanding the capability to other model sizes.
Check out the Announcement, Documentation, and Demo. All credit goes to the researchers.
References
[1] Yao, S. et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arXiv
[2] Wu, P. & Xie, S. (2023). V: Guided Visual Search as a Core Mechanism in Multimodal LLMs*. arXiv preprint. arXiv
[3] Wang, W. et al. (2024). Divide, Conquer and Combine: A Training-Free Framework for High-Resolution Image Perception in Multimodal Large Language Models. AAAI 2025. arXiv
[4] Anthropic. (2024). Introducing Computer Use, a new Claude 3.5 Sonnet. Anthropic Blog. Link
[5] Wang, Z. et al. (2024). CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs. NeurIPS 2024 Datasets & Benchmarks. arXiv


