80.3 on ScreenSpotPro: GUI-Owl-1.5 Sets New Bar for Open-Source GUI Agents
Alibaba's Tongyi Lab open-sources a GUI agent that beats Claude on tool-calling tasks and achieves 80.3 on ScreenSpotPro grounding, surpassing every model including Gemini-3-Pro.
Computer-use agents have become the next major battleground in AI, with Anthropic, OpenAI, and Google all shipping GUI automation capabilities in the past year. Yet most production-grade options remain proprietary and single-platform. Building on the Mobile-Agent series [1, 8] from Alibaba's Tongyi Lab, researchers have now released GUI-Owl-1.5 -- an open-source native GUI agent model that achieves state-of-the-art results across more than 20 benchmarks spanning desktop, mobile, and browser environments. Unlike UI-TARS-2 [2, 7] which targets platforms individually, GUI-Owl-1.5 trains a single unified policy across all device types, enabled by a novel reinforcement learning algorithm called MRPO.
The model family includes instruct and thinking variants at 2B, 4B, 8B, and 32B parameter scales, built on Qwen3-VL [5] and available on HuggingFace. Smaller instruct models can run on edge devices for real-time interaction, while larger thinking models handle complex planning in the cloud -- enabling a practical edge-cloud collaboration architecture.
Key Results Across 20+ Benchmarks
GUI-Owl-1.5 delivers strong performance across every evaluation dimension. On computer use, the 32B-Instruct model achieves 56.5 on OSWorld-Verified [4], surpassing UI-TARS-2 (53.1) and OpenCUA-72B [3] (45.0). Even the 2B variant scores 43.5, outperforming UI-TARS-72B-DPO (27.1) with over 10x fewer parameters.
On mobile automation, the 8B-Thinking variant reaches 71.6 on AndroidWorld [10], on par with UI-TARS-2's 73.3 despite smaller scale. For browser tasks, the 32B-Thinking model achieves 48.4 on WebArena and 46.6 on VisualWebArena, establishing the strongest open-source browser agent performance to date.
Where GUI-Owl-1.5 particularly stands out is on tool-calling and grounding. On OSWorld-MCP, which evaluates GUI operations combined with MCP tool invocation, the 32B-Instruct model scores 47.6 -- surpassing Claude-4-sonnet (43.3) and MAI-UI-235B-A22B [6] (41.7, a model 7x larger). On ScreenSpotPro grounding, it achieves 80.3, exceeding Gemini-3-Pro (72.7). On the GUI Knowledge Bench, it scores 75.5, topping all models including o3 (73.3) and Gemini-2.5-Pro (71.7).
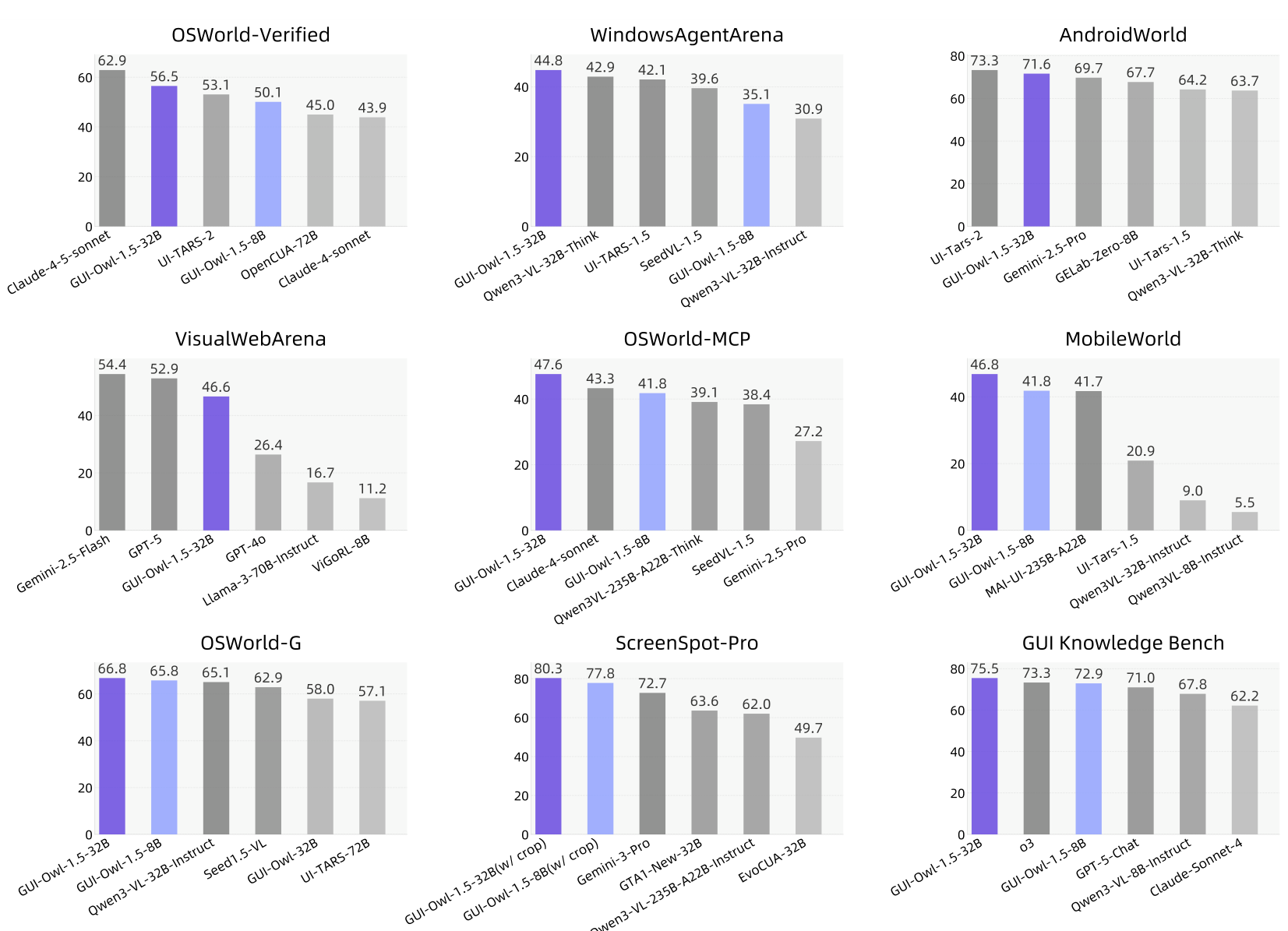 Benchmark OverviewPerformance comparison across nine major GUI benchmarks showing GUI-Owl-1.5 achieving top or near-top scores on OSWorld, AndroidWorld, ScreenSpotPro, and more.
Benchmark OverviewPerformance comparison across nine major GUI benchmarks showing GUI-Owl-1.5 achieving top or near-top scores on OSWorld, AndroidWorld, ScreenSpotPro, and more.
Architecture and Multi-Platform Design
GUI-Owl-1.5 uses a device-conditioned interaction protocol where the system message defines the available action space for each platform, the user message contains the task instruction with compressed interaction history and current screenshot, and the model generates reasoning thoughts followed by structured action calls. The action space has been expanded beyond basic GUI operations (click, type, scroll) to include external tool calls, API invocations, and MCP-based interactions.
For long-horizon tasks, a sliding window mechanism with hierarchical context compression maintains computational efficiency. Recent turns retain full multimodal information, while earlier interactions are condensed into textual summaries of action conclusions.
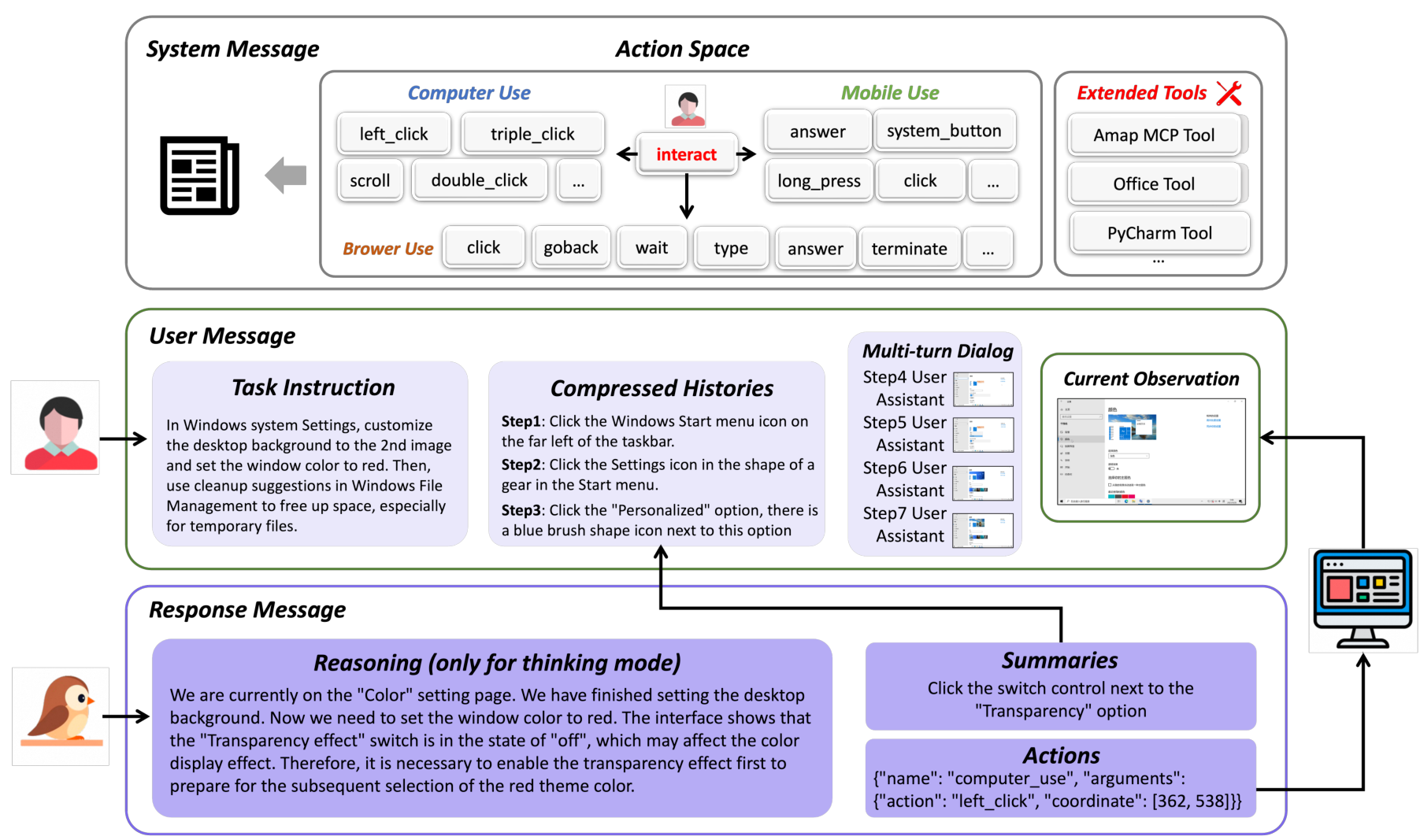 System OverviewOverview of Mobile-Agent-v3.5 showing multi-platform environment support across mobile, desktop, and browser with key capabilities including GUI automation, tool calling, and memory.
System OverviewOverview of Mobile-Agent-v3.5 showing multi-platform environment support across mobile, desktop, and browser with key capabilities including GUI automation, tool calling, and memory.
Hybrid Data Flywheel
A critical challenge for GUI agents is collecting high-quality trajectory data at scale. GUI-Owl-1.5 addresses this through a hybrid data flywheel combining multiple collection strategies.
For grounding data, the team develops hard grounding synthesis that generates challenging professional application screenshots using MLLMs, along with multi-window high-resolution scenarios. Scalable data extension comes from mining existing trajectories, extracting knowledge from software tutorials, and generating infeasible query negative samples.
For trajectory data, a DAG-based task synthesis system constructs directed acyclic graphs of subtasks for each application, then samples paths to generate realistic multi-step instructions. An automated rollout pipeline executes these on real devices with checkpoint-based validation, truncating trajectories at the last verified checkpoint and repairing remaining subtasks. The team also builds web-rendering virtual environments that bypass real-world obstacles like CAPTCHAs. Ablation studies show removing virtual environment data causes dramatic drops: PC-Eval falls from 75.4% to 42.0% and Mobile-Eval from 86.7% to 50.0%.
MRPO: Solving Multi-Platform RL Training
The most technically novel contribution is MRPO (Multi-platform Reinforcement Policy Optimization), which addresses four key challenges in training a single RL policy across heterogeneous device environments.
Unified device-conditioned policy. Rather than training separate models per platform, MRPO optimizes a single policy conditioned on device type, maintaining cross-platform generalization while respecting each platform's unique action space and UI conventions.
Online rollout buffer for GRPO collapse. When using grouped rollouts, all trajectories in a group frequently yield identical outcomes (all success or all failure), making the group uninformative. MRPO oversamples kn trajectories on-policy, then subsamples n to form training groups. If the initial subsample collapses, one element is swapped with an opposite-outcome trajectory from the pool, preserving on-policy guarantees while sharply reducing collapsed groups.
Token-ID transport. When the environment-side inference tokenizer produces different token IDs than the training-side tokenizer for the same text, log-probabilities become inconsistent. MRPO transports the original inference token IDs alongside textual payloads, ensuring exact log-probability alignment.
Alternating multi-device optimization. Instead of mixing trajectories from different platforms in each batch (which causes gradient conflicts), MRPO trains on single device families cyclically. Ablation studies confirm that interleaved training avoids the performance oscillation observed in mixed-platform training.
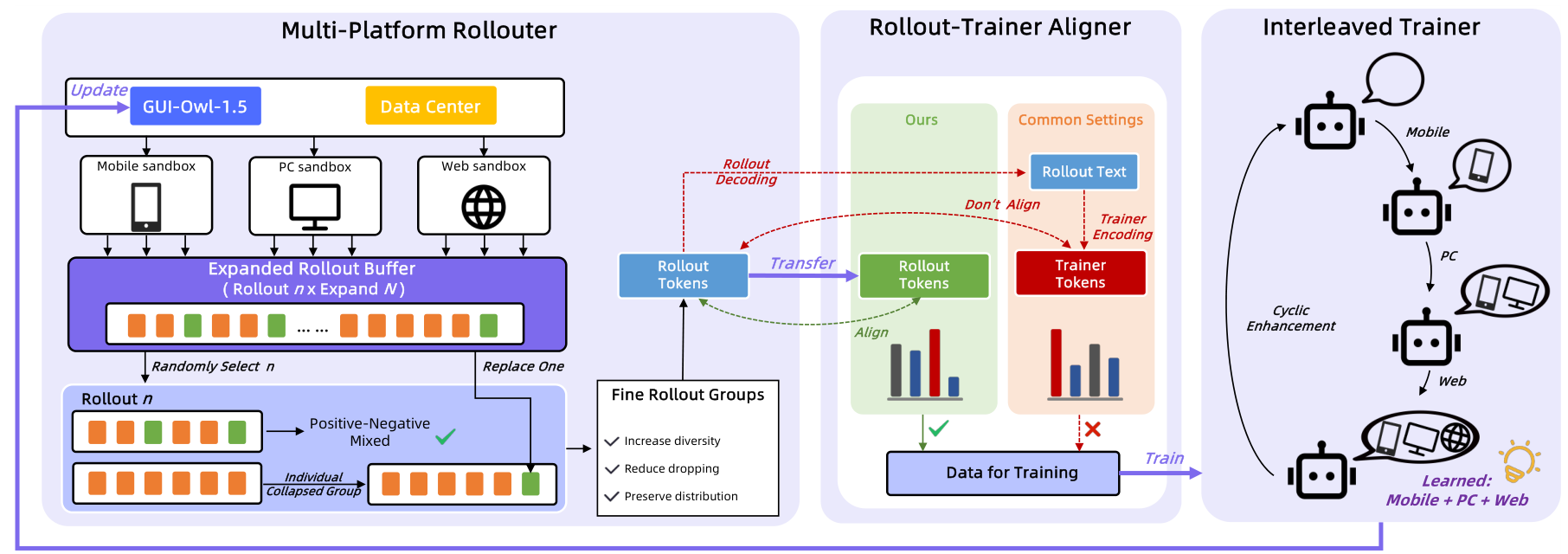 MRPO PipelineThe reinforcement learning pipeline showing multi-platform rollouter, expanded rollout buffer for handling GRPO collapse, token-ID transport for training-inference alignment, and interleaved multi-platform training.
MRPO PipelineThe reinforcement learning pipeline showing multi-platform rollouter, expanded rollout buffer for handling GRPO collapse, token-ID transport for training-inference alignment, and interleaved multi-platform training.
Research Context
This work extends Mobile-Agent-v3 [1] and the original GUI-Owl model from the same Tongyi Lab team. The multi-agent collaboration framework (Manager, Worker, Reflector, Notetaker roles) is carried forward from prior versions [8], while the core model training pipeline and RL approach are substantially new.
What is genuinely novel: MRPO's four-component RL framework is the standout contribution, particularly the online rollout buffer with formal on-policy guarantees and the token-ID transport mechanism for log-probability consistency. The comprehensive evaluation across 20+ benchmarks is itself a contribution no other open-source GUI agent has matched.
Compared to UI-TARS-2 [2, 7] -- the strongest multi-platform competitor -- GUI-Owl-1.5 offers comparable benchmark performance with the added advantages of explicit tool/MCP calling capability and a wider range of model sizes for edge-to-cloud deployment. For pure mobile automation, MAI-UI [6] may offer higher single-platform performance at larger scale (76.7 on AndroidWorld at 235B). Proprietary models like Claude-4-5-sonnet still lead on individual benchmarks (62.9 on OSWorld-Verified).
Open questions remain around how much of the performance gain comes from MRPO versus expanded training data, whether the edge-cloud collaboration approach works reliably under real-world latency constraints, and why Thinking variants sometimes underperform Instruct variants on grounding tasks.
Check out the Paper and GitHub Repo. All credit goes to the researchers for their work on this project.
References
[1] Ye, J. et al. (2025). Mobile-Agent-v3: Fundamental Agents for GUI Automation. arXiv. arXiv
[2] Qin, Y. et al. (2025). UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv. arXiv
[3] Wang, X. et al. (2025). OpenCUA: Open Foundations for Computer-Use Agents. arXiv. arXiv
[4] Xie, T. et al. (2024). OSWorld: Benchmarking Multimodal Agents for Open-ended Tasks in Real Computer Environments. NeurIPS 2024.
[5] Bai, S. et al. (2025). Qwen3-VL Technical Report. arXiv.
[6] Zhou, H. et al. (2025). MAI-UI: Real-world Centric Foundation GUI Agents. arXiv.
[7] ByteDance Seed. (2025). UI-TARS-2. Technical Report. Link
[8] Wang, J. et al. (2024). Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration. NeurIPS 2024.
[9] Xue, T. et al. (2026). EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience. arXiv.
[10] Rawles, C. et al. (2024). AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. arXiv.