2.7x Better 3D Reconstruction from Messy Videos: Meta's ShapeR Tackles Real-World Capture
Your smartphone video is full of occlusions, motion blur, and bad angles - and that's exactly what current 3D reconstruction models fail on.
Recent advances in 3D shape generation have achieved impressive results, but a fundamental problem remains: most methods require clean, unoccluded, and well-segmented inputs that rarely exist in real-world scenarios. When users capture video with their phones, the footage contains occlusions, background clutter, motion blur, and suboptimal viewpoints. Existing image-to-3D models like Hunyuan3D-2.0 [4] and TripoSG [3] perform well on pristine inputs but struggle significantly when processing these casual captures.
Researchers from Meta Reality Labs have developed ShapeR, a multimodally conditioned rectified flow model that generates robust 3D shapes from casually captured video sequences. Building on the VecSet latent representation [1] and the EFM3D benchmark framework [2], ShapeR combines sparse SLAM point clouds, posed multi-view images, and machine-generated captions to produce metric-accurate 3D reconstructions without requiring explicit segmentation masks. The result is a 2.7x improvement in Chamfer distance compared to state-of-the-art methods.
The Problem with Current Approaches
Scene-centric reconstruction methods like NeRF and 3D Gaussian Splatting reconstruct entire scenes as monolithic surfaces, leaving individual objects incomplete in occluded regions. Object-centric methods theoretically solve this, but they require something that casual captures rarely provide: clean segmentation of individual objects.
Foundation image-to-3D models such as TripoSG [3], Hunyuan3D-2.0 [4], and Amodal3R [5] have made significant progress on generating 3D shapes from images. However, these methods depend on high-quality 2D instance segmentation, which degrades quickly with occlusions, background clutter, and imperfect viewpoints. Even amodal completion approaches like Amodal3R [5], designed specifically for occluded objects, struggle in real-world casual capture conditions.
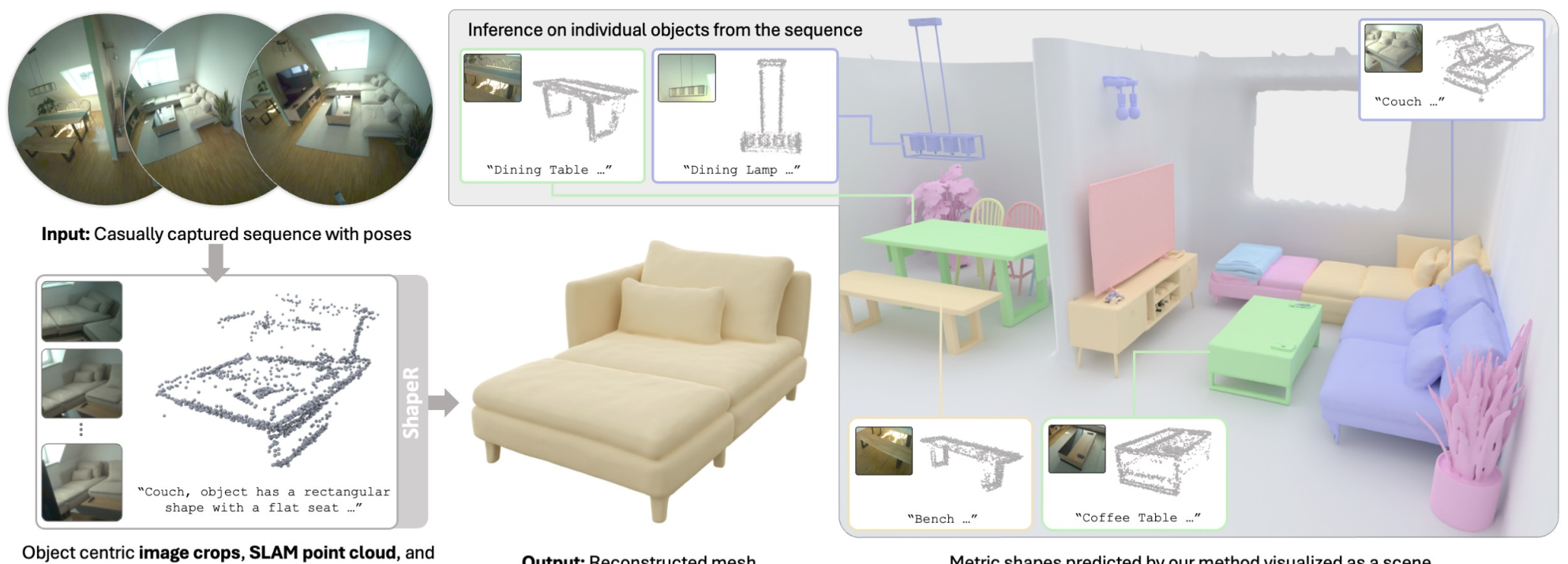 ShapeR OverviewThe pipeline extracts per-object metric sparse SLAM points, images, poses, and captions from video sequences, then uses a rectified flow transformer to generate complete 3D meshes.
ShapeR OverviewThe pipeline extracts per-object metric sparse SLAM points, images, poses, and captions from video sequences, then uses a rectified flow transformer to generate complete 3D meshes.
How ShapeR Works
ShapeR takes a fundamentally different approach by leveraging multiple complementary modalities. Given a video sequence, the system first runs visual-inertial SLAM to extract sparse metric point clouds and camera poses. A 3D instance detection model then identifies object bounding boxes. For each detected object, ShapeR extracts:
- Sparse SLAM points within the object's bounding box
- Posed multi-view images showing the object
- 2D point projections creating binary masks that indicate the object's location
- Machine-generated captions from a vision-language model describing the object
These multimodal inputs condition a rectified flow transformer built on the FLUX.1 dual-single-stream architecture. The transformer denoises a latent VecSet code, which a decoder then converts to signed distance values. Marching cubes extracts the final mesh, rescaled to metric coordinates.
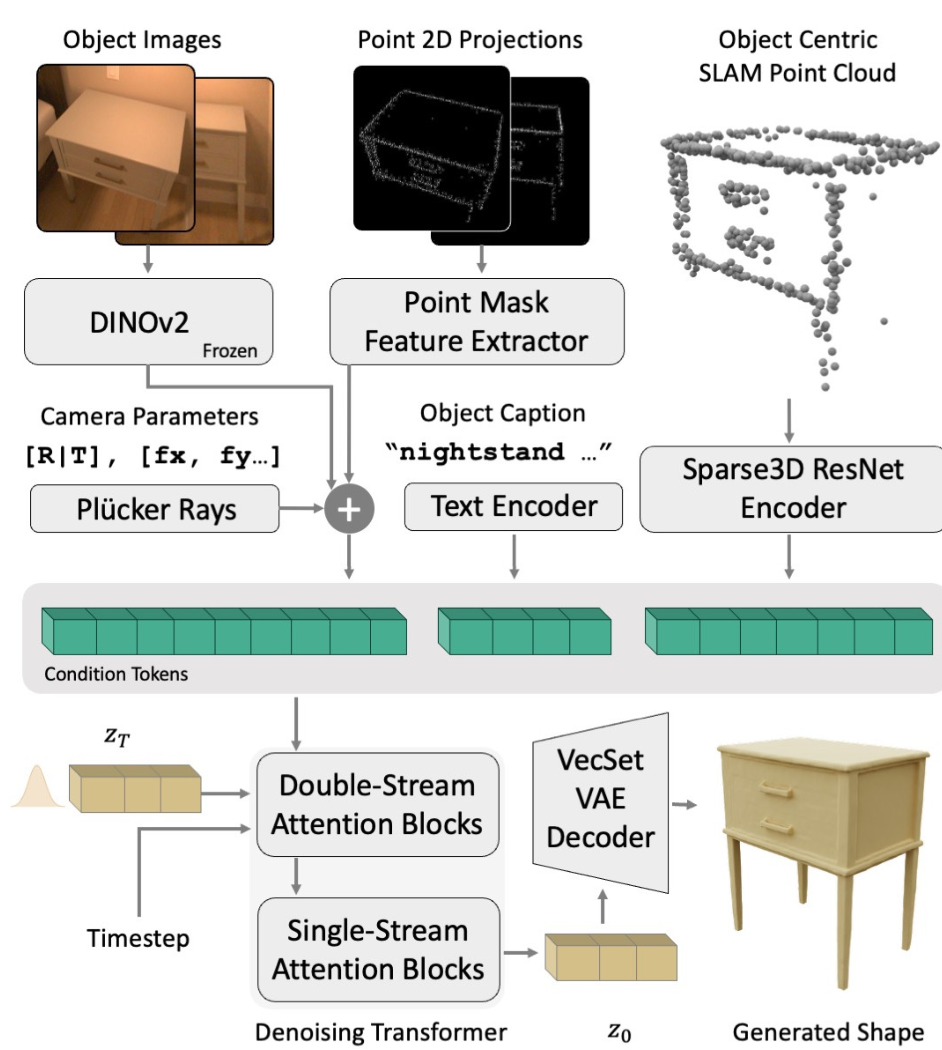 ShapeR ArchitectureThe denoising transformer conditions on posed images via DINOv2, SLAM points via Sparse3D ResNet, captions via T5/CLIP encoders, and 2D point projections via convolutional networks.
ShapeR ArchitectureThe denoising transformer conditions on posed images via DINOv2, SLAM points via Sparse3D ResNet, captions via T5/CLIP encoders, and 2D point projections via convolutional networks.
Key Innovation: Implicit Segmentation via Point Prompting
A critical innovation is how ShapeR avoids the segmentation dependency that plagues other methods. Instead of requiring explicit 2D masks, the system projects 3D SLAM points onto each image to create binary point masks. These masks guide the DINOv2 image features to focus on the correct object, even in cluttered scenes with multiple nearby objects.
This 2D point mask prompting clarifies which object to reconstruct without manual intervention. In ablation studies, removing this component causes the model to sometimes reconstruct adjacent objects instead of the target, demonstrating its importance for disambiguation.
Training Strategy: Curriculum Learning with Heavy Augmentation
ShapeR employs a two-stage curriculum learning approach. The first stage trains on over 600,000 object meshes from large-scale artist-created datasets. To simulate real-world degradation, the system applies extensive on-the-fly augmentations:
- Image augmentations: background compositing, foreground occlusions, resolution degradation, sensor noise
- Point cloud augmentations: partial trajectories, dropout patterns, Gaussian noise, point occlusion
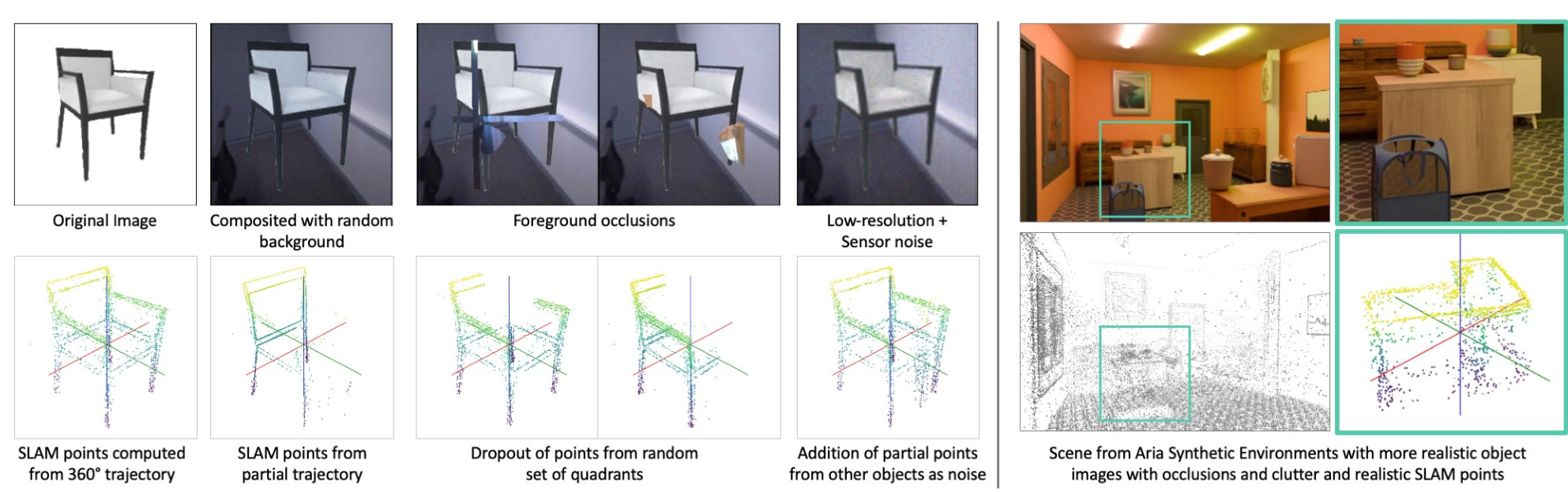 Training AugmentationsCompositional augmentations simulate realistic backgrounds, occlusions, and noise in both images and SLAM points during pretraining.
Training AugmentationsCompositional augmentations simulate realistic backgrounds, occlusions, and noise in both images and SLAM points during pretraining.
The second stage fine-tunes on Aria Synthetic Environments, which feature realistic inter-object interactions and SLAM noise patterns that single-object datasets cannot capture.
Results: 2.7x Improvement on Casual Captures
The researchers introduce a new evaluation benchmark with 178 objects across 7 real-world scenes captured using Project Aria glasses. Unlike existing datasets that are either synthetic (ShapeNet, Objaverse) or lack complete object geometry (ScanNet++), this benchmark provides complete mesh annotations for casual captures.
On this benchmark, ShapeR achieves a Chamfer distance of 2.375 x 10^-2, compared to 6.483 x 10^-2 for the next best baseline (FoundationStereo with TSDF fusion). This represents a 2.7x improvement. Methods relying on segmentation masks (LIRM, DP-Recon) perform even worse at 8.047 x 10^-2 and 8.364 x 10^-2 respectively.
In user studies with 660 responses, participants preferred ShapeR over foundation image-to-3D models 81-88% of the time. Against Hunyuan3D-2.0 [4], the win rate was 81.11%; against Direct3D-S2, 88.33%.
On controlled datasets like DTC Active, ShapeR performs comparably to LIRM. However, as capture conditions become more casual (DTC Passive, ShapeR Evaluation), the gap widens dramatically, demonstrating ShapeR's robustness advantage.
 Qualitative ComparisonShapeR produces complete, accurate reconstructions while segmentation-dependent methods fail on casual captures with occlusions and clutter.
Qualitative ComparisonShapeR produces complete, accurate reconstructions while segmentation-dependent methods fail on casual captures with occlusions and clutter.
Research Context
This work builds on the VecSet representation for 3D shape encoding [1] and the EFM3D framework for egocentric 3D perception [2]. The rectified flow formulation follows recent advances in flow matching for generative modeling [6].
What's genuinely new:
- Multimodal conditioning combining SLAM points, posed images, and VLM captions without requiring segmentation masks
- 2D point mask prompting to guide image features for implicit segmentation
- Two-stage curriculum with compositional augmentations specifically designed for casual capture robustness
Compared to LIRM (the strongest posed multiview baseline), ShapeR achieves 3.4x better Chamfer distance on casual captures while not requiring segmentation. For scenarios requiring materials and relighting, LIRM may still be preferred. For single-image inputs without video, methods like Hunyuan3D-2.0 [4] or TripoSG [3] remain options, though without metric accuracy.
Open questions:
- How does performance scale with number of input views?
- Can the approach extend to deformable or articulated objects?
- What are the computational costs compared to single-image methods?
Limitations
The authors acknowledge several limitations. Objects with stacked items may have reconstructed meshes that include remnants of adjacent structures. Very few views or low image quality leads to incomplete reconstructions. The system also depends on upstream 3D instance detection, meaning missed detections cannot be recovered downstream. The paper does not provide detailed inference time comparisons, though this is an important practical consideration for deployment.
Check out the Paper, GitHub, and HuggingFace Model. All credit goes to the researchers.
References
[1] Zhang, B. et al. (2023). 3DShape2VecSet: A 3D shape representation for neural fields and generative diffusion models. ACM TOG (SIGGRAPH). arXiv
[2] Straub, J. et al. (2024). EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models. arXiv preprint. arXiv
[3] Li, Y. et al. (2025). TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models. arXiv preprint. arXiv
[4] Zhao, Z. et al. (2025). Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation. arXiv preprint. arXiv
[5] Wu, T. et al. (2025). Amodal3R: Amodal 3D Reconstruction from Occluded 2D Images. arXiv preprint. arXiv
[6] Lipman, Y. et al. (2022). Flow Matching for Generative Modeling. ICLR 2023. arXiv


