Microsoft's Agent Lightning Decouples RL Training from Agent Logic, Enabling Fine-Tuning of Any AI Agent with Zero Code Changes
A new framework bridges the gap between diverse agent development ecosystems and reinforcement learning training infrastructure.
Reinforcement learning has driven recent breakthroughs in LLM reasoning, from DeepSeek-R1 [1] to Kimi k1.5 [2], but these advances remain confined to single-turn tasks like math and logic. Extending RL to multi-turn AI agents -- where models interact with tools, environments, and other agents across multiple steps -- has proven far more challenging. Existing approaches either require rebuilding agents inside RL training frameworks or rely on concatenating multi-turn sequences with masking, both of which couple training tightly to agent implementation details. Researchers from Microsoft Research have introduced Agent Lightning, the first framework to achieve complete decoupling between agent execution and RL training, enabling developers to fine-tune any existing agent with nearly zero code modifications.
Unlike application-specific approaches such as Search-R1 [3] for RAG or DeepSWE [4] for coding agents, Agent Lightning provides a universal training interface that works across agent frameworks including LangChain, OpenAI Agents SDK, AutoGen, and custom-built agents.
The Core Problem: Training Diverse Agents with RL
Current RL methods for LLMs are designed for static, single-call interactions -- a prompt goes in, a response comes out, and a reward is assigned. AI agents, however, exhibit both complexity and diversity. Their execution involves multiple LLM invocations with distinct prompts, interactions with external tools and APIs, and dynamic workflows that may vary across runs. Different teams build agents using different frameworks, making a one-size-fits-all training approach impractical.
Previous multi-turn RL methods concatenate all turns in a trajectory into a single sequence and use masking to control which parts are updated. This approach disrupts positional encoding continuity, creates excessively long sequences, and requires tight coupling between training and agent execution logic.
How Agent Lightning Works
Agent Lightning addresses these challenges through three key innovations.
Unified Data Interface via MDP Formulation
The framework formulates agent execution as a Partially Observable Markov Decision Process (POMDP). Each state represents a snapshot of the agent's execution containing semantic variables. Actions correspond to entire token sequences generated by single LLM invocations. The key insight is that by focusing only on states and state-changing calls, the framework can extract training data from any agent without parsing the full execution graph.
Each agent execution is decomposed into a sequence of transitions: (input, output, reward) tuples that capture what the LLM saw, what it generated, and how that action was evaluated. This abstraction is framework-agnostic -- whether the agent uses LangChain's chains, AutoGen's conversation patterns, or custom orchestration, the transitions look the same to the trainer.
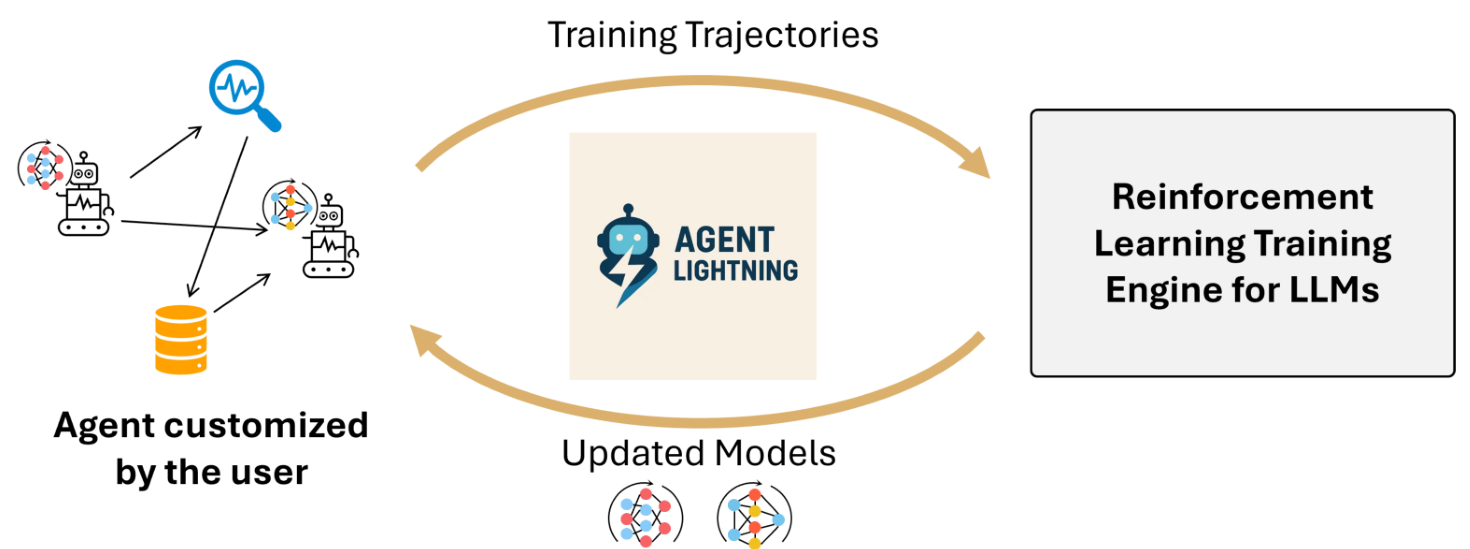 Agent Lightning OverviewOverview of Agent Lightning showing the flow from user-customized agents through the training framework to updated models.
Agent Lightning OverviewOverview of Agent Lightning showing the flow from user-customized agents through the training framework to updated models.
LightningRL: Hierarchical RL for Multi-Turn Agents
To bridge the gap between multi-turn agent interactions and single-turn RL algorithms, Agent Lightning introduces LightningRL. Rather than concatenating all turns into one sequence, LightningRL decomposes trajectories into individual transitions and groups them by task for advantage estimation. A credit assignment module distributes episode-level returns across actions -- in the current implementation using identical assignment where each action receives the same value equal to the final return.
This design allows direct use of any existing single-turn RL algorithm (GRPO [5], PPO [6], REINFORCE++ [7]) without modification. It also enables flexible context construction for each transition and avoids the sequence length explosion caused by multi-turn concatenation.
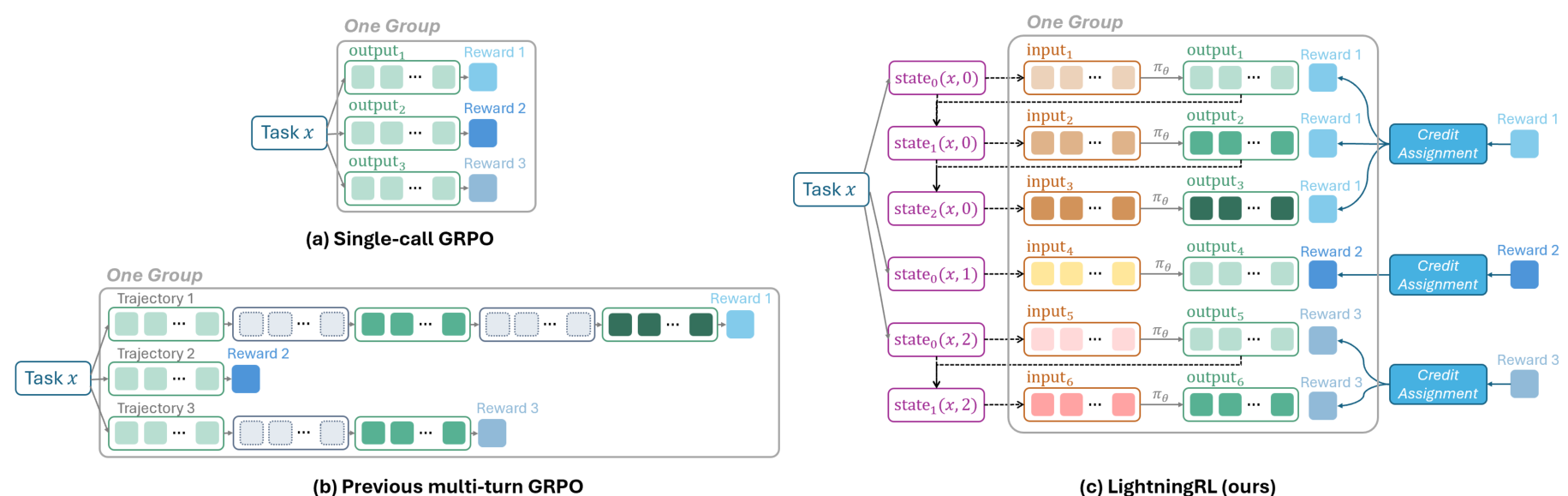 LightningRL AlgorithmComparison of single-call GRPO, previous multi-turn GRPO with masking, and LightningRL's transition-based approach where trajectories are decomposed into individual transitions for advantage estimation.
LightningRL AlgorithmComparison of single-call GRPO, previous multi-turn GRPO with masking, and LightningRL's transition-based approach where trajectories are decomposed into individual transitions for advantage estimation.
Training-Agent Disaggregation Architecture
The system architecture cleanly separates RL training from agent execution through a server-client design. The Lightning Server manages the RL training process and exposes an OpenAI-like API for model access. The Lightning Client runs agents and collects trajectories using OpenTelemetry-based instrumentation, requiring no modifications to existing agent code.
This disaggregation makes the training framework agent-agnostic (it only optimizes the LLM and manages hardware) and the agent trainer-agnostic (it operates independently of training framework details). The client supports two-level data parallelism -- intra-node and inter-node -- for scalable training with large batch sizes.
To address the sparse reward problem common in multi-step agent tasks, the framework also includes an Automatic Intermediate Rewarding (AIR) mechanism that converts system monitoring signals, such as tool call return statuses, into intermediate rewards. This provides more frequent learning signals without requiring costly human annotation.
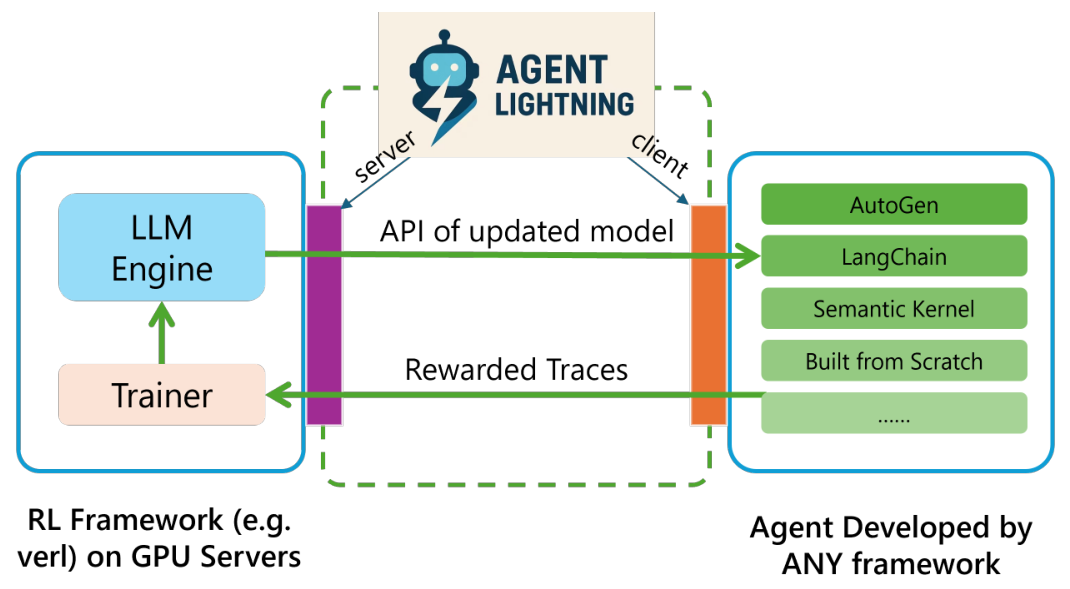 TA DisaggregationThe Training-Agent Disaggregation architecture separating the RL Framework (with LLM Engine and Trainer) from agents developed by any framework, connected via Agent Lightning Server and Client.
TA DisaggregationThe Training-Agent Disaggregation architecture separating the RL Framework (with LLM Engine and Trainer) from agents developed by any framework, connected via Agent Lightning Server and Client.
Experimental Results
Agent Lightning is validated across three tasks, each using a different agent framework and Llama-3.2-3B-Instruct as the base model. Notably, all three scenarios demonstrate continuous, stable improvement without reward collapse or training instability -- a key advantage of the transition-based approach over concatenation methods that can suffer from sequence length-related optimization difficulties.
Text-to-SQL (LangChain, Spider dataset): A multi-agent system with 3 agents (SQL writer, checker, re-writer) where only 2 are selectively optimized. Training rewards increase from approximately 0.1 to 0.8 over 400 steps, with test rewards reaching approximately 0.55. This demonstrates selective multi-agent optimization.
Retrieval-Augmented Generation (OpenAI Agents SDK, MuSiQue dataset): A single-agent system searching over 21 million Wikipedia documents using BGE embeddings. Test F1 rewards improve from approximately 0.02 to 0.22 over 200 steps on this challenging multi-hop QA benchmark.
Math QA with Tool Usage (AutoGen, Calc-X dataset): A tool-augmented agent learning to invoke a calculator at appropriate steps. Test rewards increase from approximately 0.05 to 0.65 over 450 steps, demonstrating strong learning of tool invocation patterns.
Research Context
This work builds on the foundation of single-turn RL for LLMs established by DeepSeek-R1 [1] and GRPO [5], extending these methods to multi-turn agent scenarios through hierarchical decomposition.
What is genuinely new: Agent Lightning's core novelty is architectural -- the transition-based data interface that enables framework-agnostic training without code modifications, and the Training-Agent Disaggregation design that cleanly separates concerns. The use of OpenTelemetry for RL trajectory collection is also novel.
Compared to concurrent works like RAGEN [8] and Trinity-RFT [9] which require agents to be rebuilt inside training frameworks, Agent Lightning's approach is more practical for real-world deployment where agents already exist across diverse ecosystems. However, the paper lacks direct empirical comparisons against these alternatives.
Open questions remain around the effectiveness of more sophisticated credit assignment strategies, scalability to models beyond 3B parameters, and performance on truly long-horizon tasks with hundreds of LLM calls per episode.
Limitations
The experiments exclusively use Llama-3.2-3B-Instruct, leaving scalability to larger models unverified. The credit assignment currently uses simple identical assignment, which may not optimally handle scenarios where early actions are more consequential than later ones. Notably, no baseline comparisons against concatenation-based approaches are provided -- only reward curves demonstrating improvement from the framework's own starting point.
Check out the Paper and GitHub Repo. All credit goes to the researchers.
References
[1] Guo, D. et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint. arXiv
[2] Team, K. et al. (2025). Kimi k1.5: Scaling Reinforcement Learning with LLMs. arXiv preprint. arXiv
[3] Jin, B. et al. (2025). Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv preprint. arXiv
[4] Luo, M. et al. (2025). DeepSWE: Training a State-of-the-Art Coding Agent from Scratch by Scaling RL. Notion Blog.
[5] Shao, Z. et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint. arXiv
[6] Ouyang, L. et al. (2022). Training Language Models to Follow Instructions with Human Feedback. NeurIPS 2022. arXiv
[7] Hu, J. (2025). REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models. arXiv preprint. arXiv
[8] Wang, Z. et al. (2025). RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning. arXiv preprint. arXiv
[9] Pan, X. et al. (2025). Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models. arXiv preprint. arXiv


