40% Faster Video from Single Images: Pixel-to-4D Predicts Dynamic 3D Gaussians in One Pass
Existing camera-controlled video generation methods either sacrifice geometric consistency for flexibility or require expensive multi-stage pipelines.
Camera-controlled video generation has become a critical capability for autonomous driving simulation, virtual reality, and robotics applications. The challenge is generating temporally consistent videos from single images while maintaining precise control over camera trajectories. Current methods face a fundamental tradeoff: diffusion-based approaches like CameraCtrl [4] offer flexibility but struggle with geometric consistency, while reconstruction-based methods like RealCam-I2V [3] achieve better 3D awareness but require expensive multi-stage pipelines that compound errors.
Researchers from the University of Glasgow have introduced Pixel-to-4D, a framework that sidesteps this tradeoff entirely. Building on the pixel-aligned Gaussian prediction approach pioneered by Splatter Image [1], Pixel-to-4D extends 3D Gaussian Splatting [2] into the temporal domain by predicting per-splat velocities and accelerations. The result is a system that generates complete 4D scene representations from single images in a single forward pass, achieving state-of-the-art video quality with 40-66% faster inference than competing methods.
The Core Innovation: Dynamic Gaussians
The key insight behind Pixel-to-4D is that object motion can be effectively modeled by endowing each Gaussian splat with physical motion parameters. While standard 3D Gaussian Splatting represents static scenes as collections of colored Gaussian blobs in 3D space, Pixel-to-4D adds:
- Linear velocities and accelerations for translation
- Angular velocities and accelerations around object centroids for rotation
- Per-object motion aggregation using instance segmentation to ensure Gaussians on the same object move coherently
This representation enables arbitrary time extrapolation without requiring iterative denoising. Given a desired future timestep and camera pose, the system simply updates Gaussian positions using the predicted motion parameters and renders the scene through differentiable Gaussian splatting.
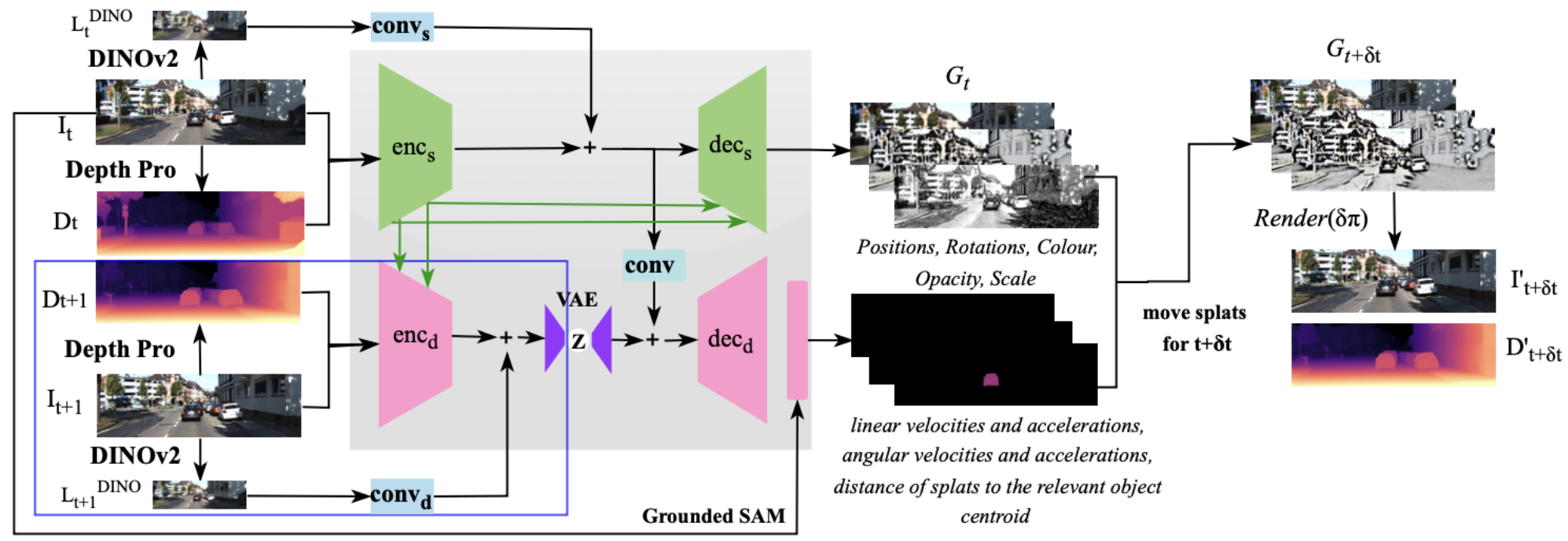 Pixel-to-4D ArchitectureThe pipeline encodes input images with DINOv2 features and depth estimation, predicts static Gaussian parameters through decs, samples motion parameters via a VAE, aggregates motion per-object using segmentation, and renders future frames through differentiable splatting.
Pixel-to-4D ArchitectureThe pipeline encodes input images with DINOv2 features and depth estimation, predicts static Gaussian parameters through decs, samples motion parameters via a VAE, aggregates motion per-object using segmentation, and renders future frames through differentiable splatting.
Architecture Details
The Pixel-to-4D architecture consists of two main pathways:
Static Pathway: An encoder (encs) processes the input image alongside depth estimates from Depth-Pro, fusing features from DINOv2 for semantic context. The decoder (decs) then predicts pixel-aligned Gaussian parameters including depth, XY offsets, rotation, scale, opacity, and color. Multiple Gaussians per pixel (K=5) handle disocclusions and complex depth structures.
Dynamic Pathway: A variational autoencoder samples plausible velocities conditioned on the static features. During training, an encoder observes the next frame to provide supervision for the motion distribution. At inference, velocities are sampled from the learned prior. Instance segmentation from Grounded SAM ensures that Gaussians predicted from the same object share consistent linear and angular motion.
The model is trained end-to-end on multi-view video data using standard 2D diffusion losses, without any regularization terms specific to 3D Gaussians or explicit consistency constraints across views.
Benchmark Results
Pixel-to-4D achieves state-of-the-art performance across four diverse datasets, outperforming recent camera-controlled video generation methods including CamI2V [5], CameraCtrl [4], MotionCtrl, and RealCam-I2V [3].
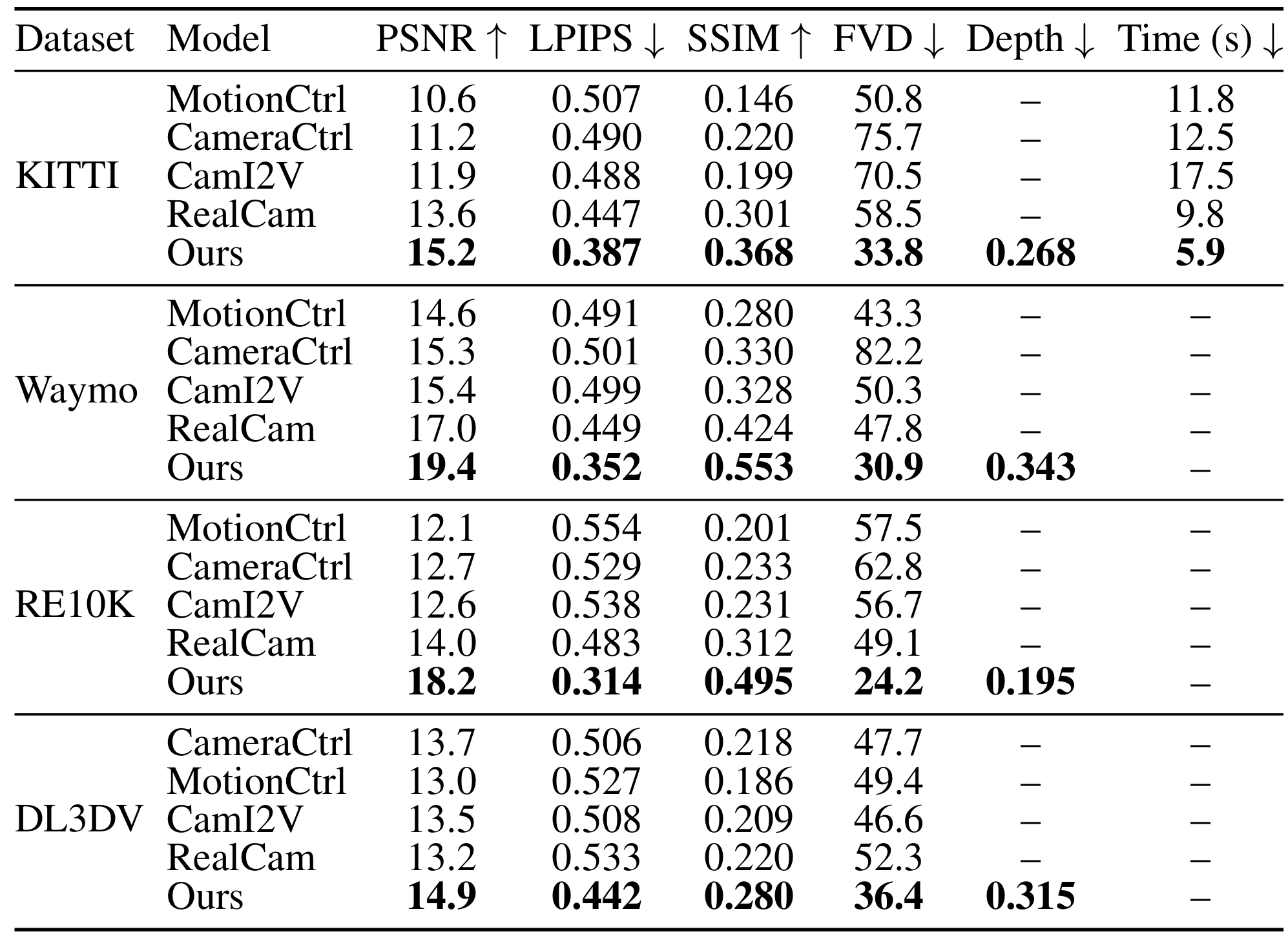 Quantitative ResultsComparison across KITTI, Waymo, RealEstate10K, and DL3DV-10K datasets showing Pixel-to-4D outperforms all baselines on PSNR, LPIPS, SSIM, and FVD metrics while achieving faster inference.
Quantitative ResultsComparison across KITTI, Waymo, RealEstate10K, and DL3DV-10K datasets showing Pixel-to-4D outperforms all baselines on PSNR, LPIPS, SSIM, and FVD metrics while achieving faster inference.
On the challenging Waymo Open dataset featuring urban driving with multiple dynamic objects, Pixel-to-4D achieves:
- PSNR 19.4 vs RealCam-I2V's 17.0 (14% improvement)
- FVD 30.9 vs MotionCtrl's 43.3 (29% improvement)
- SSIM 0.553 vs RealCam-I2V's 0.424 (30% improvement)
On KITTI, inference time drops to 5.9 seconds compared to 9.8s for RealCam-I2V, 12.5s for CameraCtrl, and 17.5s for CamI2V - a 40-66% speedup. This efficiency stems from avoiding iterative diffusion for injecting object dynamics.
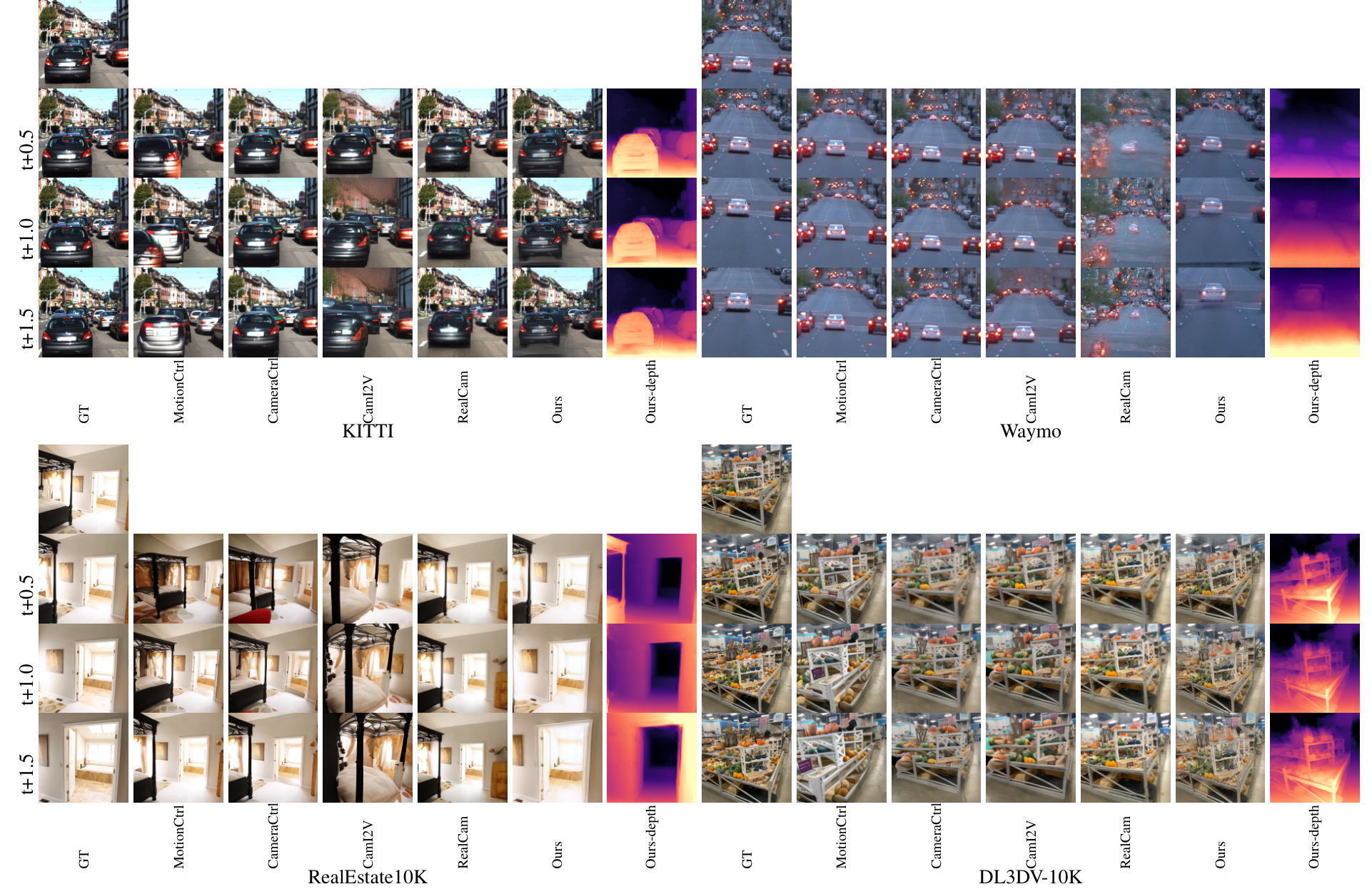 Qualitative ComparisonVisual results across four datasets at t+0.5s, t+1s, and t+1.5s showing Pixel-to-4D maintains better camera controllability and visual quality compared to baseline methods.
Qualitative ComparisonVisual results across four datasets at t+0.5s, t+1s, and t+1.5s showing Pixel-to-4D maintains better camera controllability and visual quality compared to baseline methods.
Ablation Studies
The authors validate key design choices through careful ablations:
Velocity modeling matters: Removing motion parameters entirely (reducing 4D to 3D) degrades results across all metrics. On Waymo, LPIPS worsens from 0.288 to 0.319, and FVD increases slightly from 14.1 to 14.2 (lower FVD is better, indicating the static version produces less realistic video distributions). More strikingly, without velocities, the model simply cannot capture moving vehicles, as shown in Figure 3 of the paper.
 Ablation VisualizationPredicted frames and depth maps at t+0.9s on Waymo, demonstrating that the model with velocities successfully captures vehicle motion while the static version fails.
Ablation VisualizationPredicted frames and depth maps at t+0.9s on Waymo, demonstrating that the model with velocities successfully captures vehicle motion while the static version fails.
Generative vs deterministic velocities: Using a VAE to sample plausible velocities outperforms direct regression across all metrics. The stochastic approach better handles the inherent uncertainty in predicting future motion from a single image.
Multiple Gaussians per pixel: Using 5 Gaussians per pixel instead of 1 reduces artifacts around depth discontinuities, particularly visible near foreground objects like trees.
DINOv2 features: Incorporating DINOv2 features improves moving object appearance, with particularly sharper vehicle predictions in driving scenes.
Research Context
This work builds on two key foundations: Splatter Image [1], which pioneered pixel-aligned 3D Gaussian prediction for single-image reconstruction at 38 FPS, and 3D Gaussian Splatting [2], the now-standard representation for real-time radiance field rendering.
What's genuinely new:
- Extension of pixel-aligned Gaussians to 4D with linear/angular motion parameters
- Per-object motion aggregation using instance segmentation for coherent dynamics
- Single forward pass for 4D scene generation without test-time optimization
Compared to RealCam-I2V [3], the strongest baseline, Pixel-to-4D avoids the two-stage pipeline where depth estimation errors compound with video diffusion artifacts. The explicit 4D representation guarantees geometric consistency by construction. For scenarios requiring longer video generation or complex non-rigid motion like human activities, diffusion-based methods may still be preferable.
Open questions:
- How does performance degrade beyond the 1.6-second prediction horizon?
- Can the rigid-body motion model extend to deformable objects?
- What is the sensitivity to instance segmentation failures?
Limitations
The authors acknowledge that approximating motion with linear and angular parameters works well for short intervals but may not capture complex non-linear dynamics. The method relies on three external pretrained models: Depth-Pro for monocular depth estimation, Grounded SAM for instance segmentation, and DINOv2 for semantic features. Instance segmentation failures would propagate to motion predictions. Evaluation is limited to 1.6 seconds of video, and the benchmarks focus on driving and static-scene datasets without complex human motion.
Check out the Paper and Project Page. All credit goes to the researchers.
References
[1] Szymanowicz, S. et al. (2024). Splatter Image: Ultra-Fast Single-View 3D Reconstruction. CVPR 2024. arXiv
[2] Kerbl, B. et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM TOG (SIGGRAPH 2023). arXiv
[3] Li, T. et al. (2025). RealCam-I2V: Real-world Image-to-Video Generation with Interactive Complex Camera Control. arXiv preprint. arXiv
[4] He, H. et al. (2024). CameraCtrl: Enabling Camera Control for Text-to-Video Generation. arXiv preprint. arXiv
[5] Zheng, G. et al. (2024). CamI2V: Camera-Controlled Image-to-Video Diffusion Model. arXiv preprint. arXiv


