Reasoning Overthinking Solved: SAGE Cuts Tokens 44% While Improving Accuracy
Reasoning models are drowning in their own thoughts — but the fix was already inside them all along.
Large reasoning models (LRMs) like DeepSeek-R1 [1] and Qwen3 produce impressively detailed chains of thought — but they pay a steep computational price. Over half of all correct responses from these models contain significant wasted reasoning: tokens generated after the answer has already been found. Prior work has identified this overthinking problem [2], and a growing body of research has attempted to fix it [4, 5, 6], yet most solutions force models to think less at the cost of accuracy. A team of researchers now reveals a surprising finding: reasoning models already know when to stop thinking — they just need the right signal to act on it. Their method, SAGE (Self-Aware Guided Efficient Reasoning), and its reinforcement learning extension SAGE-RL, cut reasoning tokens by up to 46.5% while simultaneously improving accuracy across multiple mathematical benchmarks.
The Overthinking Problem
To quantify the inefficiency, the authors introduce the RFCS (Ratio of First Correct Step) metric, which measures at what point in a reasoning chain the model first arrives at the correct answer relative to the total chain length. The results are striking: across DeepSeek-R1 distillates (1.5B and 7B parameters) and Qwen3-8B on the MATH-500 benchmark [8], over 50% of correct responses contain substantial ineffective steps — reasoning tokens generated after the model already reached the right answer. A recent survey on efficient reasoning [7] reports a corroborating finding, noting that shorter reasoning chains can be substantially more likely to yield correct answers.
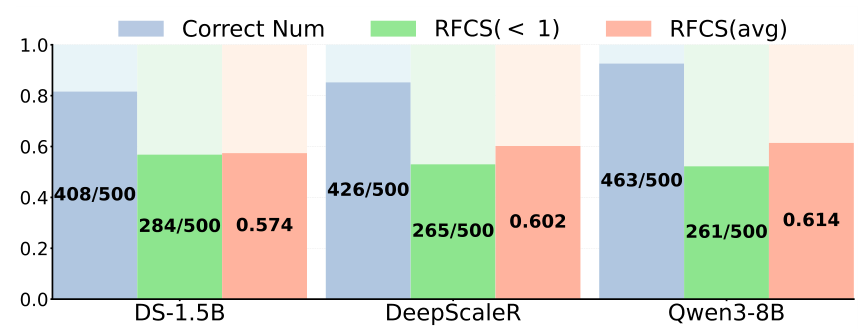 RFCS StatisticsDistribution of the Ratio of First Correct Step across four reasoning models on MATH-500, showing that over 50% of correct samples contain significant wasted reasoning steps.
RFCS StatisticsDistribution of the Ratio of First Correct Step across four reasoning models on MATH-500, showing that over 50% of correct samples contain significant wasted reasoning steps.
The RFCS distributions (shown above) confirm this pattern across all four models tested, with the majority of correct samples exhibiting significant redundant reasoning after the first correct step.
Models Already Know When to Stop
The paper's central discovery emerges from a tree search algorithm called TSearch, which uses cumulative log-probability scoring (Φ) — the average log-probability across an entire reasoning chain — as a confidence measure. Three key observations reveal that LRMs possess implicit stopping knowledge:
-
High-confidence paths are shorter and more accurate. When TSearch explores multiple reasoning trajectories scored by Φ, the top-ranked paths are consistently both shorter and more correct than alternatives.
-
The
</think>token ranks first under Φ scoring. When the model reaches a high-confidence reasoning chain, the end-of-thinking token consistently emerges as the top candidate — even when its next-token probability is low. The model "wants" to stop, but standard sampling does not surface this signal. -
More exploration reveals more efficiency. As search width increases, the model discovers increasingly precise and compact reasoning paths, suggesting that efficiency is a latent capability rather than an external constraint to impose.
How SAGE Works
Building on these observations, SAGE extends TSearch from token-level to step-level exploration. Rather than expanding one token at a time, SAGE operates at the granularity of complete reasoning steps (delineated by paragraph breaks). At each step, multiple candidate continuations are generated via standard sampling, then ranked by their cumulative log-probability score Φ. The highest-confidence paths are retained while lower-confidence branches are pruned.
Crucially, termination is automatic: when the </think> token appears naturally in a high-confidence branch, the model stops — no manual threshold or token budget required. Unlike AdaptThink [5], which forces a binary think/no-think decision, SAGE allows variable-length reasoning calibrated to each problem's difficulty.
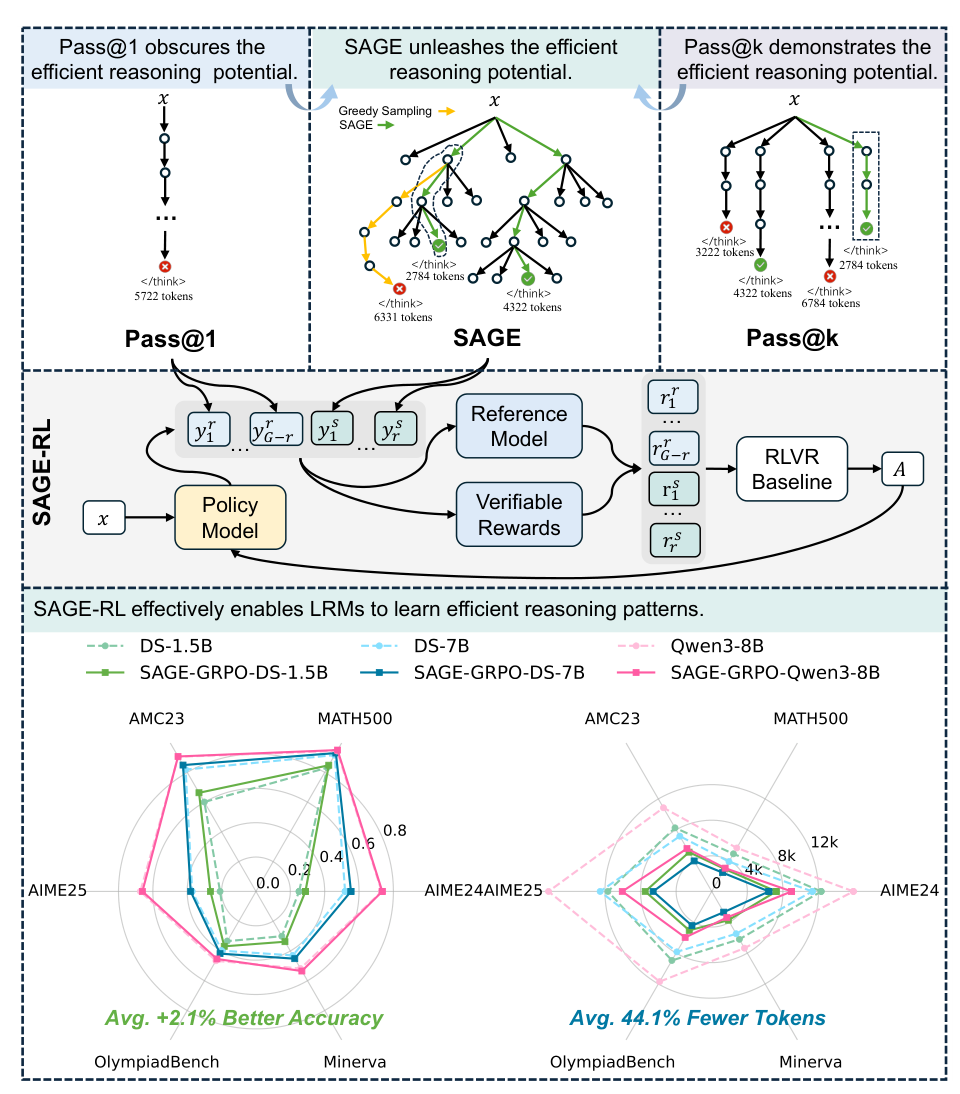 SAGE OverviewSAGE unleashes the efficient reasoning potential of LRMs that is obscured by pass@1 sampling and identifies optimal completions within the model's capability hidden in pass@k.
SAGE OverviewSAGE unleashes the efficient reasoning potential of LRMs that is obscured by pass@1 sampling and identifies optimal completions within the model's capability hidden in pass@k.
The SAGE overview (above) illustrates how confidence-guided exploration surfaces efficient reasoning paths that standard pass@1 sampling obscures.
SAGE-RL: Internalizing Efficient Reasoning via Training
While SAGE improves inference efficiency, it requires tree search at test time. SAGE-RL eliminates this overhead by integrating SAGE into reinforcement learning training based on GRPO [3] (and is also compatible with the GSPO framework). The modification to existing training pipelines is minimal: in a group of 8 rollout samples, 2 are generated using SAGE's confidence-guided sampling while the remaining 6 use standard random sampling. This hybrid rollout is the only change.
The SAGE-guided samples provide the RL optimizer with examples of efficient reasoning paths — compact, high-confidence chains that still produce correct answers. Over training, the model internalizes these patterns, learning to produce efficient reasoning at standard pass@1 inference without any tree search overhead at deployment.
Results: Accuracy Up, Tokens Down
SAGE-RL was evaluated across four models (DeepSeek-R1-Distill-1.5B, DeepScaleR, DeepSeek-R1-Distill-7B, and Qwen3-8B) on six mathematical benchmarks. The results demonstrate a rare dual improvement:
On MATH-500 [8], SAGE-RL achieves:
- DS-7B: 93.0% accuracy (+1.4%) with 44.7% token reduction (3,871 → 2,141 tokens)
- Qwen3-8B: 95.0% accuracy (+0.6%) with 46.5% token reduction (5,640 → 3,015 tokens)
- DS-1.5B: 84.8% accuracy (+1.6%) with 40.3% token reduction (4,882 → 2,915 tokens)
- DeepScaleR: 88.8% accuracy (+2.8%) with 18.1% token reduction (3,805 → 3,117 tokens)
On harder benchmarks, the gains are more pronounced. On AIME 2025, SAGE-RL improves DS-1.5B accuracy by 5.6 percentage points (20.9% → 26.5%) while achieving a 97.8% token efficiency gain. On OlympiadBench, DS-7B gains 2.0% accuracy with tokens reduced from 7,839 to 4,435. Token efficiency — accuracy divided by response length — improves by up to 88.6% (Qwen3-8B on MATH-500), and SAGE-RL models run 28.7% faster in average inference latency. While competing methods like ThinkPrune [4] and Token-Budget-Aware reasoning [9] achieve compression at the cost of accuracy, SAGE-RL consistently improves both.
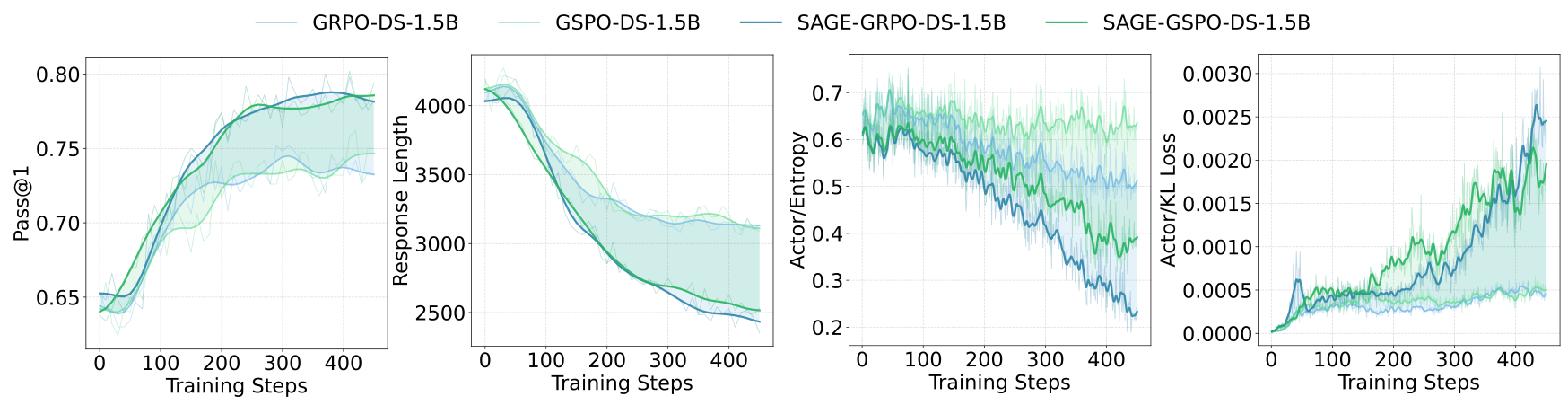 Training DynamicsComparison of standard RLVR and SAGE-RL training dynamics, showing more pronounced accuracy improvements, greater response length reduction, stronger entropy reduction, and increased KL divergence as the model acquires efficient reasoning patterns.
Training DynamicsComparison of standard RLVR and SAGE-RL training dynamics, showing more pronounced accuracy improvements, greater response length reduction, stronger entropy reduction, and increased KL divergence as the model acquires efficient reasoning patterns.
The training dynamics comparison (above) shows how SAGE-RL achieves faster convergence toward shorter, more accurate reasoning chains compared to standard RLVR training.
Research Context
This work builds on the overthinking diagnosis by Chen et al. [2] and the GRPO reinforcement learning framework from DeepSeekMath [3], combining diagnostic insights with a constructive training solution.
The core novelty lies in the discovery that LRMs implicitly know when to stop thinking, revealed through cumulative log-probability scoring showing the </think> token ranks first in high-confidence chains. From this insight, the authors derive a step-wise exploration algorithm (SAGE) that surfaces this hidden signal for efficient reasoning, and a hybrid rollout strategy (SAGE-RL) that permanently internalizes efficient reasoning patterns with a minimal two-of-eight sample modification to standard GRPO training.
Compared to AdaptThink [5], which uses binary mode-switching between thinking and no-thinking, SAGE-RL offers continuous confidence-based path selection that adapts reasoning length to problem difficulty. For scenarios requiring explicit length control, methods like L1 [6] may be more appropriate.
Several open questions remain. It is unclear whether the implicit stopping knowledge exists in non-distilled LRMs, or whether it is an artifact of knowledge distillation from larger teacher models. The method has only been evaluated on mathematical reasoning tasks, leaving its effectiveness on domains where answer verification is harder an open question. Finally, the paper uses a 2-of-8 SAGE-to-random sample ratio without ablating this choice, so the optimal hybrid rollout ratio remains unexplored.
Check out the Paper and Project Page. All credit goes to the researchers.
References
[1] Guo, D. et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv. arXiv
[2] Chen, X. et al. (2025). Do NOT Think That Much for 2+3=? On the Overthinking of Long Reasoning Models. OpenReview. Paper
[3] Shao, Z. et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv. arXiv
[4] Hou, B. et al. (2025). ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning. arXiv. arXiv
[5] Zhang, J. et al. (2025). AdaptThink: Reasoning Models Can Learn When to Think. arXiv. arXiv
[6] Aggarwal, P. & Welleck, S. (2025). L1: Controlling How Long a Reasoning Model Thinks with Reinforcement Learning. arXiv. arXiv
[7] Various (2025). Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models. arXiv. arXiv
[8] Hendrycks, D. et al. (2021). Measuring Mathematical Problem Solving with the MATH Dataset. NeurIPS 2021. arXiv
[9] Han, T. et al. (2025). Token-Budget-Aware LLM Reasoning. arXiv. arXiv