SimpleMem gives LLM agents 30x cheaper memory with 26% better recall
LLM agents forget everything after their context window fills up, and current solutions are either bloated or expensive.
LLM agents face a fundamental bottleneck: they forget everything once their context window fills up. Current approaches to this problem fall into two camps. Full-context methods like LoCoMo [1] dump entire conversation histories into the prompt, consuming approximately 16,900 tokens per query and flooding the model with redundant small talk and repeated confirmations. Reasoning-based filters like A-Mem [2] use iterative LLM calls to decide what to keep, but this introduces construction times exceeding 5,000 seconds per sample. Neither approach efficiently manages memory for the long-running agent interactions that real-world applications require.
Researchers from UNC-Chapel Hill, UC Berkeley, and UC Santa Cruz have introduced SimpleMem, a memory framework that takes a fundamentally different approach: instead of reasoning about what to remember, it compresses memories using entropy-driven semantic filtering. The result is a 26.4% F1 improvement over Mem0 [3] on the LoCoMo benchmark while consuming just 531 tokens per query, a 30x reduction compared to full-context baselines.
How SimpleMem Works
SimpleMem operates through a three-stage pipeline inspired by Complementary Learning Systems (CLS) theory [4], the neuroscience framework describing how biological brains consolidate memories from short-term episodic storage into long-term structured knowledge.
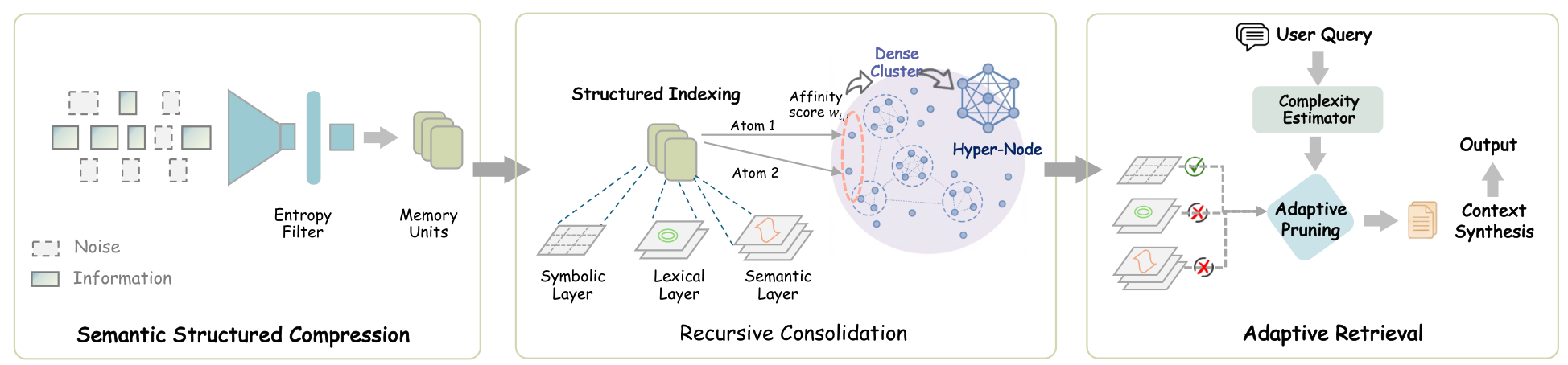 SimpleMem ArchitectureThe three-stage pipeline: Semantic Structured Compression filters noise at ingestion, Recursive Consolidation organizes memories into abstract representations, and Adaptive Retrieval dynamically adjusts scope based on query complexity.
SimpleMem ArchitectureThe three-stage pipeline: Semantic Structured Compression filters noise at ingestion, Recursive Consolidation organizes memories into abstract representations, and Adaptive Retrieval dynamically adjusts scope based on query complexity.
Stage 1: Semantic Structured Compression
Incoming dialogue is segmented into overlapping sliding windows of 10 turns. Each window receives an information score that combines entity-level novelty (how many new named entities appear) with semantic divergence from recent history. Windows scoring below a threshold of 0.35 are discarded entirely, preventing greetings, filler, and redundant confirmations from ever entering memory.
Windows that pass the filter are decomposed into self-contained memory units through coreference resolution (replacing "he" with "Bob") and temporal anchoring (converting "next Friday" to "2025-10-24"). This normalization ensures each memory unit remains interpretable without its original conversational context.
Stage 2: Recursive Memory Consolidation
Each memory unit is indexed through three complementary layers: dense semantic embeddings for fuzzy matching, sparse BM25 features for exact keyword retrieval, and symbolic metadata (timestamps, entity types) for deterministic filtering.
Over time, an asynchronous background process identifies clusters of related memories using affinity scores that combine semantic similarity with temporal proximity. When a cluster exceeds a similarity threshold of 0.85, its entries are synthesized into a higher-level abstract representation. As the authors illustrate, multiple records of "the user ordered a latte at 8:00 AM" consolidate into "the user regularly drinks coffee in the morning." The original fine-grained entries are archived, keeping active memory compact.
Stage 3: Adaptive Query-Aware Retrieval
Rather than retrieving a fixed number of context entries, SimpleMem estimates query complexity using a lightweight classifier. Simple fact lookups retrieve just 3 high-level entries, while complex multi-hop reasoning queries expand to 20 entries with associated fine-grained details. A hybrid scoring function aggregates semantic similarity, lexical relevance, and symbolic constraint matching to rank candidates.
Benchmark Results
SimpleMem was evaluated on the LoCoMo benchmark [1], which tests long-term conversational reasoning across 1,986 questions spanning multi-hop reasoning, temporal reasoning, open-domain, and single-hop retrieval tasks.
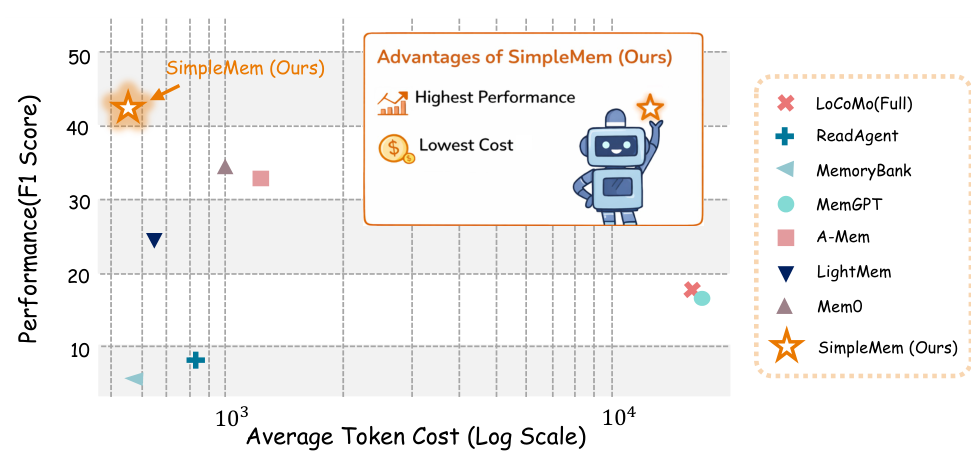 Performance vs EfficiencySimpleMem occupies the top-left position, achieving the highest F1 score with the lowest token cost among all compared methods on the LoCoMo benchmark.
Performance vs EfficiencySimpleMem occupies the top-left position, achieving the highest F1 score with the lowest token cost among all compared methods on the LoCoMo benchmark.
On GPT-4.1-mini, SimpleMem achieves 43.24 Average F1 compared to Mem0's 34.20, a 26.4% improvement. The gains are particularly striking in temporal reasoning (58.62 vs 48.91 F1), validating the effectiveness of temporal normalization during compression. Token consumption averages just 531 tokens per query, compared to 973 for Mem0 and 16,910 for full-context approaches.
The efficiency gains extend beyond inference. SimpleMem's construction time is 92.6 seconds per sample, compared to 1,350.9 seconds for Mem0 (14x faster) and 5,140.5 seconds for A-Mem (50x faster). The total time-to-insight is 480.9 seconds versus Mem0's 1,934.3 seconds, a 4x speedup.
Crucially, SimpleMem empowers smaller models on the LoCoMo benchmark. A 3B-parameter Qwen2.5 model paired with SimpleMem achieves 17.98 F1, outperforming the same model with Mem0 (13.03) by nearly 5 points. Even the 1.5B Qwen2.5 with SimpleMem (25.23 F1) beats larger models using weaker memory systems.
Ablation Analysis
Each pipeline stage contributes meaningfully. Removing semantic structured compression causes a 56.7% drop in temporal reasoning F1 (from 58.62 to 25.40). Disabling recursive consolidation reduces multi-hop performance by 31.3%. Removing adaptive retrieval degrades open-domain and single-hop tasks by 26.6% and 19.4% respectively.
Research Context
SimpleMem builds on the evolution from full-context retention (LoCoMo [1]) through virtual context paging (MemGPT [5]) to graph-based structured storage (Mem0 [3]). Its key insight is that entropy-driven compression at ingestion time eliminates the need for expensive reasoning-based filtering.
Compared to Mem0, SimpleMem achieves both higher accuracy and lower cost. The trade-off is that Mem0's graph structure may offer better interpretability for debugging specific memory operations. For scenarios where construction speed and token efficiency are paramount, SimpleMem is the clear choice.
Open questions remain around long-term scalability: does consolidation quality degrade as memory grows to thousands of entries? How does the system handle contradictory information when users change preferences across sessions? And can the fixed entropy threshold (0.35) be made adaptive for different conversation styles?
The framework is already seeing real-world adoption, with 1.8k GitHub stars, an MCP server integration, PyPI package availability, and Claude Skills support, all within weeks of release.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Maharana, A. et al. (2024). Evaluating Very Long-Term Conversational Memory of LLM Agents. arXiv preprint. arXiv
[2] Xu, W. et al. (2025). A-Mem: Agentic Memory for LLM Agents. arXiv preprint. arXiv
[3] Dev, K. and Taranjeet, S. (2024). Mem0: The Memory Layer for AI Agents. GitHub
[4] Kumaran, D. et al. (2016). What Learning Systems Do Intelligent Agents Need? Complementary Learning Systems Theory Updated. Trends in Cognitive Sciences, 20(7):512-534.
[5] Packer, C. et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv preprint. arXiv


