Training-Free Fix Boosts Vision-Language Models 3 Points by Correcting Attention Errors
What if your vision-language model's final layer is actually looking at the wrong parts of the image?
What if your vision-language model's final layer is looking at the wrong parts of the image? New research from National University of Defense Technology reveals that multimodal large language models (MLLMs) systematically over-attend to irrelevant image regions—a phenomenon the authors call "high-attention noise." Their solution: a training-free method that compares attention patterns between early "fusion layers" and a late "review layer" to redirect the model's visual focus, yielding consistent 2-3 point improvements across six VQA benchmarks [1].
The High-Attention Noise Problem
Despite impressive results on vision-language tasks, MLLMs suffer from a poorly understood internal problem. Through systematic layer-wise analysis, the researchers discovered that irrelevant image regions often receive consistently high attention across all layers, creating noise that degrades final predictions.
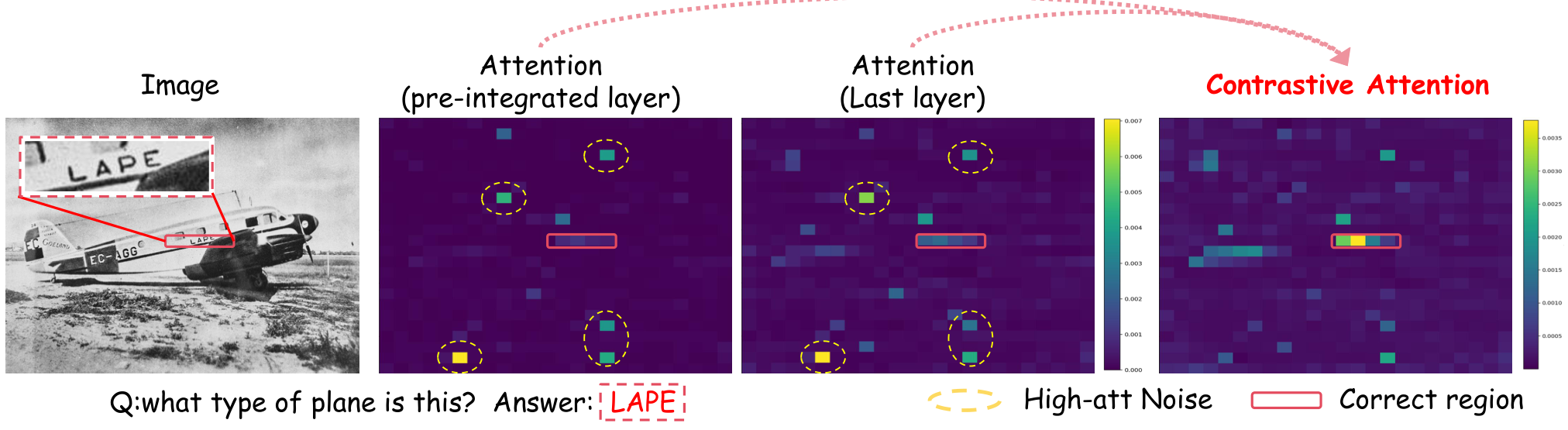 Contrastive attention visualizationContrastive attention (pre-integrated to last layer) reveals the correct region (LAPE text on plane) while suppressing persistent high-attention noise in irrelevant areas.
Contrastive attention visualizationContrastive attention (pre-integrated to last layer) reveals the correct region (LAPE text on plane) while suppressing persistent high-attention noise in irrelevant areas.
The team conducted layer-wise masking experiments on LLaVA-1.5 and LLaVA-1.6, completely blocking visual information at each transformer layer to measure its impact on performance. The results were striking: masking visual information at certain specific layers caused performance to drop dramatically, sometimes approaching zero accuracy [1].
Discovering Fusion and Review Layers
The masking experiments revealed a hierarchical structure in how MLLMs process visual information. Vision-language fusion primarily occurs at several shallow layers—specifically layers 2, 4, 8, 11, 12, and 13 in the tested architectures. These "fusion layers" show sharp performance drops when visual information is masked, indicating they are critical for integrating visual and textual understanding [1].
 Layer-wise masking effectsLayer-wise masking effects on accuracy and inference time across six VQA benchmarks using LLaVA-1.5. Performance drops sharply at fusion layers and at layer 29.
Layer-wise masking effectsLayer-wise masking effects on accuracy and inference time across six VQA benchmarks using LLaVA-1.5. Performance drops sharply at fusion layers and at layer 29.
More surprisingly, the researchers discovered what they call a "review layer" at layer 29, near the end of the model. When visual information is masked at this layer, performance again drops significantly. The authors hypothesize that this layer performs a "final visual check" before generating output—analogous to a human glancing back at an image one last time before answering a question [1].
How Contrastive Attention Works
Building on these insights, the team developed a training-free method that exploits the difference between attention patterns at different processing stages. The key idea, inspired by DoLa [2] which contrasts layers in text-only LLMs, is to compute "contrastive attention"—the absolute difference between attention maps at a pre-integrated layer (before fusion is complete) and a post-integrated layer (after fusion).
This contrastive attention captures how the model's visual focus shifts during integration. Regions that receive high attention in the final layer but low attention early on likely represent the "high-attention noise" problem. By identifying these regions, the method can selectively suppress them.
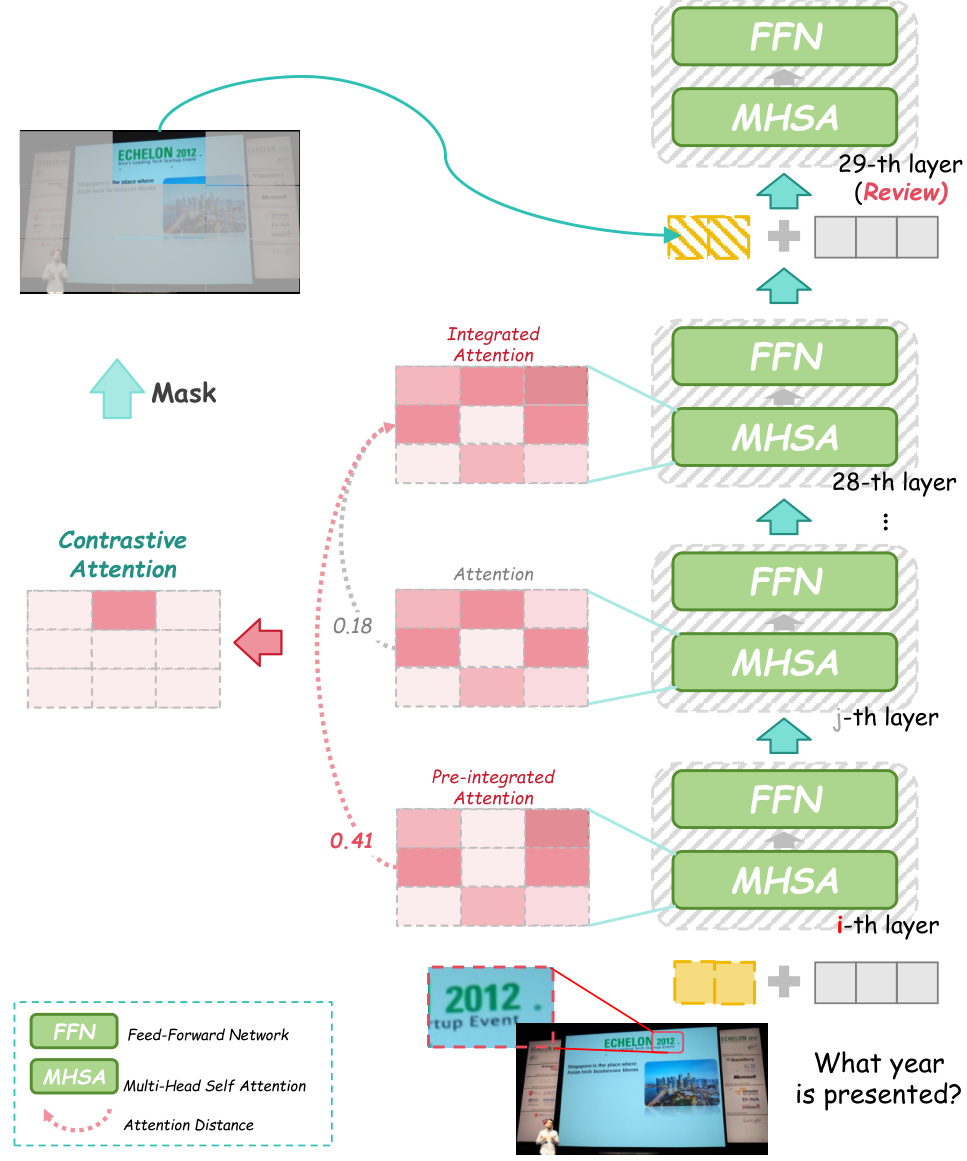 Method overviewThe method extracts attention from pre-integrated and post-integrated layers, computes the contrastive difference, and applies soft masking at the review layer.
Method overviewThe method extracts attention from pre-integrated and post-integrated layers, computes the contrastive difference, and applies soft masking at the review layer.
The practical implementation works as follows: At inference time, the method selects a pre-integrated layer using Hellinger distance to find which fusion layer's attention is most different from the post-integrated layer (layer 28). It then computes the contrastive attention and uses it to create a mask at the review layer (layer 29). Visual tokens with contrastive attention scores below the 20th percentile are softly suppressed by scaling down their features [1].
Results Across VQA Benchmarks
The method delivers consistent improvements across six standard VQA benchmarks including VQAv2, GQA, TextVQA, OKVQA, VizWiz, and DocVQA.
 Performance comparisonEffectiveness comparison showing contrastive attention outperforms both baseline MLLMs and other training-free enhancement methods like DoLa and ViCrop.
Performance comparisonEffectiveness comparison showing contrastive attention outperforms both baseline MLLMs and other training-free enhancement methods like DoLa and ViCrop.
On LLaVA-1.5, average accuracy improved from 55.19 to 58.25—a gain of 3.06 points. Individual benchmarks showed improvements ranging from 2.3 points on VQAv2 to 3.8 points on OKVQA. On the newer LLaVA-1.6, the method achieved an average improvement of 2.66 points, reaching 69.18 average accuracy [1].
Compared to other training-free methods, contrastive attention outperforms both DoLa [2] (which contrasts logits rather than attention) at 55.04 average and ViCrop [3] (which crops input images based on attention maps) at 56.52 average [1]. The key advantage is that contrastive attention operates on internal mechanisms without modifying the input image.
Research Context
This work builds on DoLa [2], an ICLR 2024 paper that improved text LLM factuality by contrasting output logits between early and later layers. The current paper adapts this inter-layer contrast idea from logit space to attention space, specifically targeting visual token attention in MLLMs.
What's genuinely new: The systematic discovery of fusion layers and review layer behavior through layer-wise masking, the application of contrastive methods to attention space rather than logit space, and the dynamic pre-integrated layer selection using Hellinger distance.
The research arrives amid active investigation into MLLM visual attention problems. Concurrent work on "visual attention sinks" at ICLR 2025 [4] addresses similar issues through attention redistribution, while ViCrop [3] takes a training-free approach through image cropping. The discovery of specific fusion layers and review behavior adds interpretability insights beyond the practical performance gains.
Open questions: Do the identified fusion layers and review layer generalize to architecturally different MLLMs like Qwen-VL or InternVL? What is the mechanistic explanation for why layer 29 specifically exhibits review behavior? Can these insights inform better MLLM training strategies?
Limitations
The evaluation is limited to LLaVA-series models (versions 1.5 and 1.6), leaving questions about whether the identified layer patterns generalize to other architectures. The paper lacks statistical significance tests and doesn't analyze failure cases where contrastive attention might hurt performance. The 20% masking threshold was determined empirically and may need tuning for different tasks.
Code has been promised but is not yet available. For practitioners deploying LLaVA models, this represents a potentially valuable inference-time optimization once released.
Check out the Paper. All credit goes to the researchers.
References
[1] Song, S., Li, S., & Yu, J. (2026). Where Does Vision Meet Language? Understanding and Refining Visual Fusion in MLLMs via Contrastive Attention. arXiv preprint. arXiv
[2] Chuang, Y.-S. et al. (2024). DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. ICLR 2024. arXiv
[3] Zhang, J. et al. (2025). MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs. ICLR 2025. arXiv
[4] Anonymous. (2025). See What You Are Told: Visual Attention Sink in Large Multimodal Models. ICLR 2025. arXiv


