Tsinghua Researchers Show Diffusion LLMs Reason Better When You Take Away Their Flexibility
In a finding that challenges conventional wisdom about diffusion language models, researchers demonstrate that the much-touted ability to generate tokens in any order is actually a liability for reasoning tasks.
Diffusion Large Language Models (dLLMs) have emerged as a compelling alternative to traditional autoregressive models, with systems like Gemini Diffusion [1], Mercury [2], and LLaDA [3] demonstrating competitive performance while offering the ability to generate tokens in any order. This flexibility has been widely assumed to unlock superior reasoning by allowing non-sequential problem-solving paths. Researchers have invested significant effort building complex reinforcement learning methods -- including d1 [4], ESPO [5], SPG [6], and GDPO [7] -- specifically designed to preserve this arbitrary-order capability during training.
A new paper from Tsinghua University and Alibaba Group reveals a counter-intuitive reality: this flexibility actually narrows rather than expands reasoning potential. The researchers propose JustGRPO, a minimalist approach that intentionally restricts dLLMs to standard left-to-right order during training, achieving 89.1% accuracy on GSM8K and 45.1% on MATH-500 -- surpassing all existing diffusion-specific RL methods while fully preserving parallel decoding at inference time.
The Flexibility Trap
The paper's central finding challenges a fundamental assumption in the dLLM field. Using the Pass@k metric [8], which measures the coverage of a model's solution space, the researchers compare arbitrary-order generation against standard autoregressive (AR) decoding across three representative dLLMs: LLaDA-Instruct [3], Dream-Instruct [9], and LLaDA-1.5 [10].
The results are striking. While arbitrary order achieves competitive performance in single-shot settings (k=1), AR order demonstrates dramatically better scaling as k increases. At k=1024, the solution space analysis reveals that arbitrary-order solutions are largely a strict subset of those generated by AR order. On HumanEval, AR order solves 21.3% of problems that arbitrary order misses entirely, while the reverse accounts for only 0.6%.
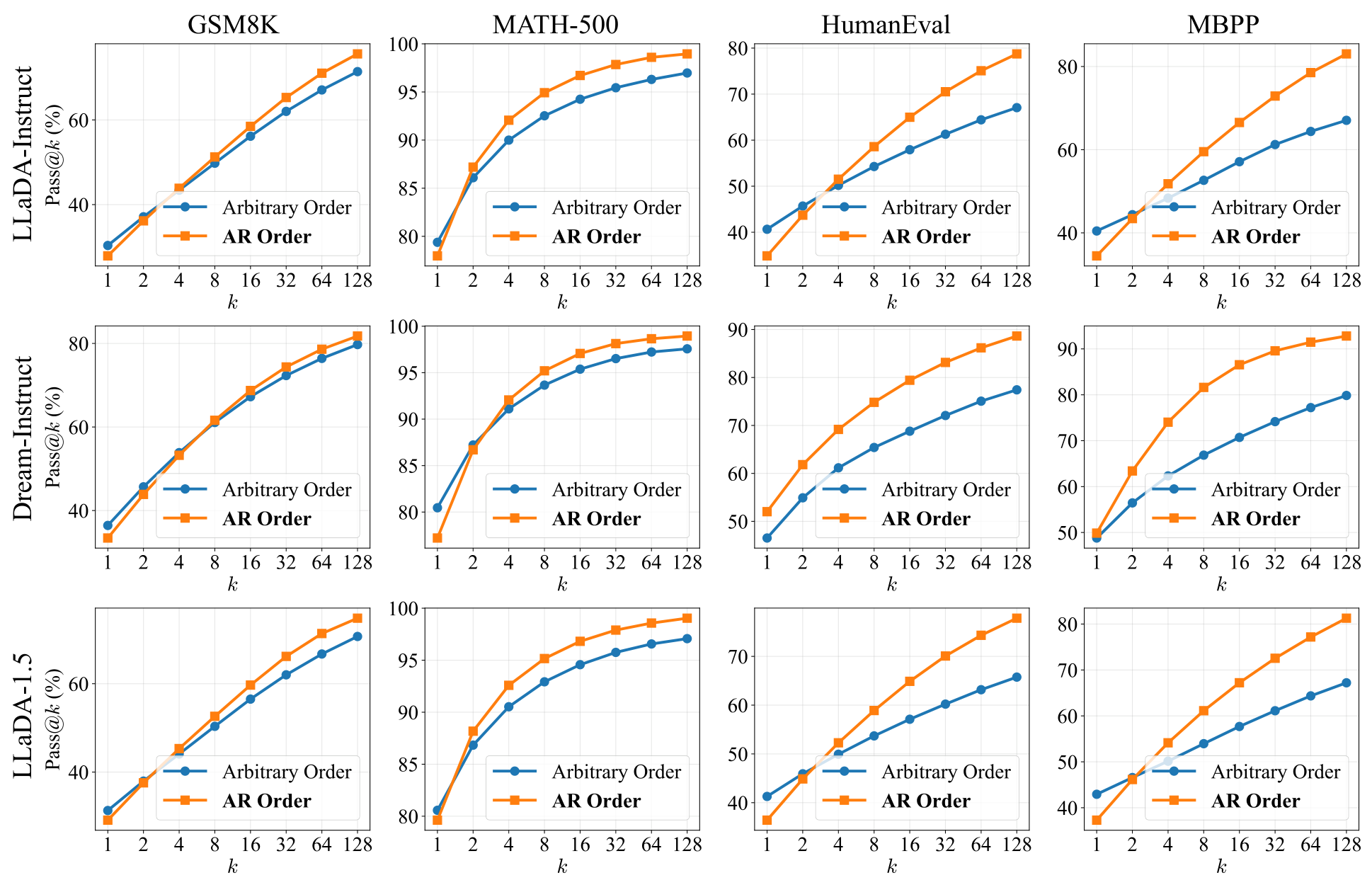 Pass@k AnalysisReasoning potential across three dLLMs and four benchmarks, showing AR order consistently outperforms arbitrary order as the sampling budget increases.
Pass@k AnalysisReasoning potential across three dLLMs and four benchmarks, showing AR order consistently outperforms arbitrary order as the sampling budget increases.
The Entropy Degradation Mechanism
The paper identifies a specific mechanism explaining why flexibility hurts reasoning: entropy degradation at logical forks. Reasoning hinges on sparse "forking tokens" -- logical connectives like "Therefore", "Since", and "Thus" that steer the reasoning trajectory into distinct branches. These tokens naturally exhibit high entropy, representing genuine decision points where multiple reasoning paths are viable.
In AR decoding, the model is forced to confront these high-entropy decisions as they arise, sampling from the full distribution and preserving diverse reasoning paths. Arbitrary-order generation, however, allows the model to bypass these difficult tokens, preferentially generating easier, low-entropy completions first. Consider a model solving a math problem: with arbitrary order, it might resolve the numerical answer before deciding the logical step that leads there. When the model eventually returns to fill in the bypassed forks, the surrounding context has already been established, collapsing the entropy and eliminating the diversity of possible reasoning chains.
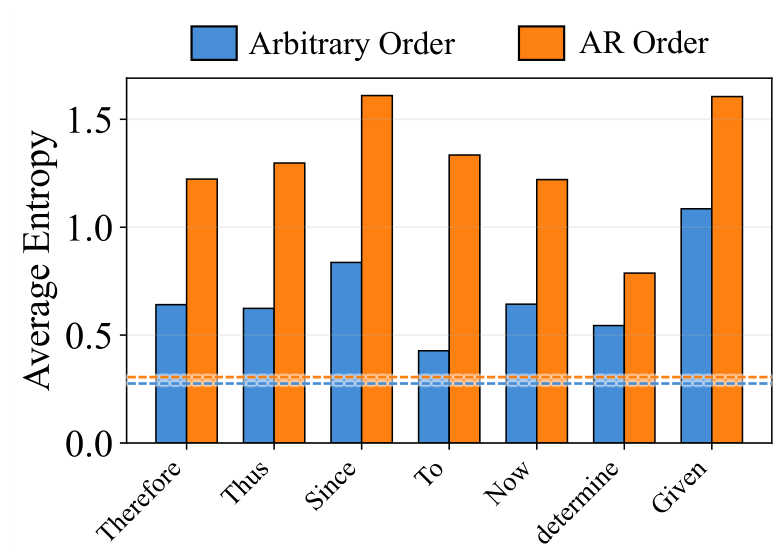 Entropy DegradationWhile global average entropy remains comparable between modes, entropy at logical fork tokens drops significantly under arbitrary order, confirming premature solution space collapse.
Entropy DegradationWhile global average entropy remains comparable between modes, entropy at logical fork tokens drops significantly under arbitrary order, confirming premature solution space collapse.
The researchers term this phenomenon entropy degradation: the model trades exploration of diverse reasoning paths for greedy optimization of local consistency. Effectively, the flexibility that should enable creative problem-solving instead becomes a mechanism for shortcut exploitation.
JustGRPO: A Return to Simplicity
These findings motivate a fundamentally different approach to RL training for dLLMs. Existing methods face three core challenges from preserving arbitrary order: ambiguous token-level credit assignment, intractable sequence likelihoods requiring O(N!) marginalization over denoising trajectories, and sampler-learner mismatches between heuristic-guided exploration and the optimization objective.
JustGRPO eliminates all three by treating the dLLM as an autoregressive policy during training. The key formulation constructs an input state where past tokens are observed and future tokens are masked, then defines the AR policy as the softmax over model logits at the next position. This yields exact, tractable likelihood computation and enables direct application of standard GRPO [11] without any diffusion-specific modifications.
The approach is remarkably simple. The core implementation spans approximately 60 lines of code. Training uses LLaDA 8B Instruct as the base model with just 125 training steps on 16 NVIDIA H100 GPUs -- approximately three days for GSM8K.
Results
JustGRPO achieves state-of-the-art performance across all tested benchmarks, consistently outperforming methods specifically designed for dLLMs.
On GSM8K, JustGRPO reaches 89.1% accuracy at sequence length 256, surpassing the previous best method SPG [6] by 3.0 percentage points. On MATH-500, it achieves 45.1%, outperforming ESPO [5] by 6.1 points. For code generation, it reaches 49.4% on HumanEval and 52.4% on MBPP, exceeding all comparable baselines. Beyond accuracy, JustGRPO also demonstrates superior training efficiency: it surpasses the peak accuracy of approximation-based methods like ESPO in less wall-clock time while maintaining a continuous scaling trend, whereas ESPO saturates early in training.
Critically, despite training with AR constraints, the model fully retains parallel decoding at inference. Using the training-free Entropy Bounded sampler [12], accuracy gains over the baseline actually become more pronounced with increased parallelism -- expanding from +10.6% at 1 token per step to +25.5% at approximately 5 tokens per step on MBPP. This suggests JustGRPO learns a more robust reasoning manifold that better tolerates the approximation errors inherent in parallel sampling.
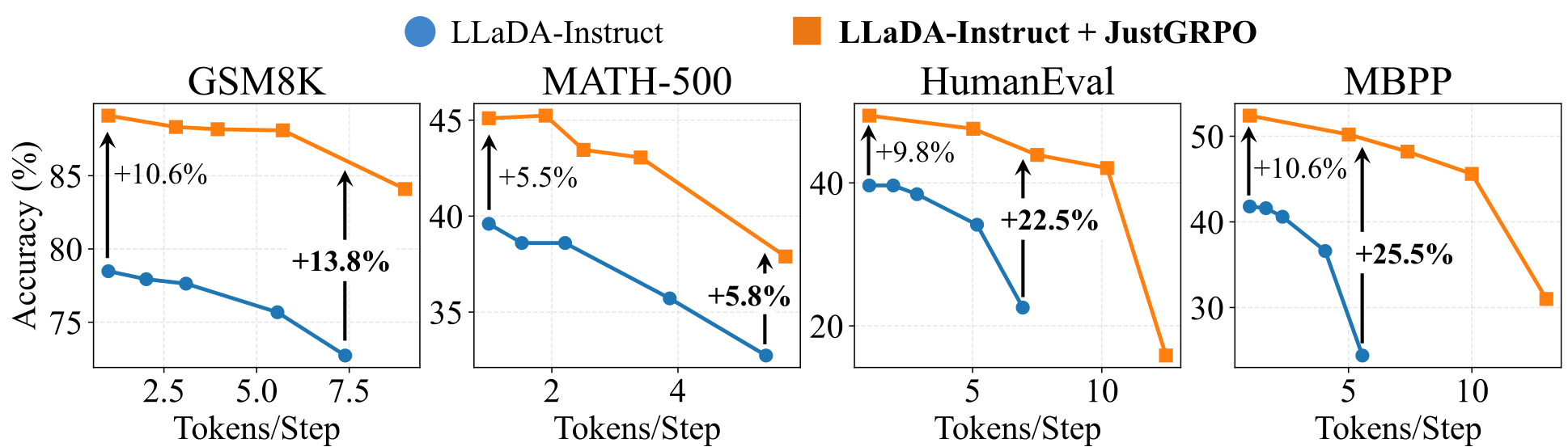 Parallel DecodingJustGRPO preserves and even enhances parallel decoding performance, with accuracy gains increasing at higher parallelism levels.
Parallel DecodingJustGRPO preserves and even enhances parallel decoding performance, with accuracy gains increasing at higher parallelism levels.
Research Context
This work builds on the GRPO algorithm introduced by DeepSeekMath [11] and challenges the approaches of d1 [4], ESPO [5], SPG [6], and GDPO [7], which all invest complexity in preserving arbitrary-order generation during RL training.
What is genuinely new: The paper provides the first systematic demonstration that arbitrary order limits reasoning potential across multiple dLLMs and benchmarks, identifies the entropy degradation mechanism as the causal explanation, and shows that the entire complexity of diffusion-specific RL is not just unnecessary but counterproductive.
Compared to ESPO [5], which uses sequence-level ELBO approximations to handle intractable likelihoods, JustGRPO achieves 6.1% higher accuracy on MATH-500 while converging faster in wall-clock time and requiring simpler implementation.
Open questions remain about whether the flexibility trap holds at larger scales (70B+ parameters), whether hybrid approaches with partial order constraints could offer benefits, and what theoretical properties of AR training cause it to actually improve parallel decoding performance.
Resources
Check out the Paper, GitHub, and Model. All credit goes to the researchers of this paper.
References
[1] DeepMind. (2025). Gemini Diffusion. Link
[2] Labs, I. et al. (2025). Mercury: Ultra-fast language models based on diffusion. arXiv preprint. arXiv
[3] Nie, S. et al. (2025). Large Language Diffusion Models. arXiv preprint. arXiv
[4] Zhao, S. et al. (2025). d1: Scaling reasoning in diffusion large language models via reinforcement learning. arXiv preprint. arXiv
[5] Ou, J. et al. (2025). Principled RL for diffusion LLMs emerges from a sequence-level perspective. arXiv preprint. arXiv
[6] Wang, C. et al. (2025). SPG: Sandwiched policy gradient for masked diffusion language models. arXiv preprint. arXiv
[7] Rojas, K. et al. (2025). Improving reasoning for diffusion language models via group diffusion policy optimization. arXiv preprint. arXiv
[8] Chen, M. (2021). Evaluating large language models trained on code. arXiv preprint. arXiv
[9] Ye, J. et al. (2025). Dream 7B: Diffusion large language models. arXiv preprint. arXiv
[10] Zhu, F. et al. (2025). LLaDA 1.5: Variance-reduced preference optimization for large language diffusion models. arXiv preprint. arXiv
[11] Shao, Z. et al. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint. arXiv
[12] Ben-Hamu, H. et al. (2025). Accelerated sampling from masked diffusion models via entropy bounded unmasking. arXiv preprint. arXiv


