Unified Latents Hits 1.4 FID by Replacing Stable Diffusion's Ad Hoc VAE with a Diffusion Prior
The original Stable Diffusion model's VAE was tuned by hand -- Google DeepMind replaces guesswork with information theory.
Latent representations are the backbone of modern image and video generation. Since the original Latent Diffusion Model [1], the standard approach has been to train a VAE with a hand-tuned KL penalty to compress images into a latent space, then train a diffusion model on those latents. But this design has a fundamental weakness: there is no principled way to reason about how much information the latents actually carry, and the KL weight must be set by trial and error. Recent alternatives like epsilon-VAE [3] and SWYCC [4] use diffusion decoders but still rely on channel bottlenecks for regularization, while self-supervised approaches like SVG [6] replace the VAE entirely with DINO features but sacrifice high-frequency reconstruction fidelity (PSNR scores below 20).
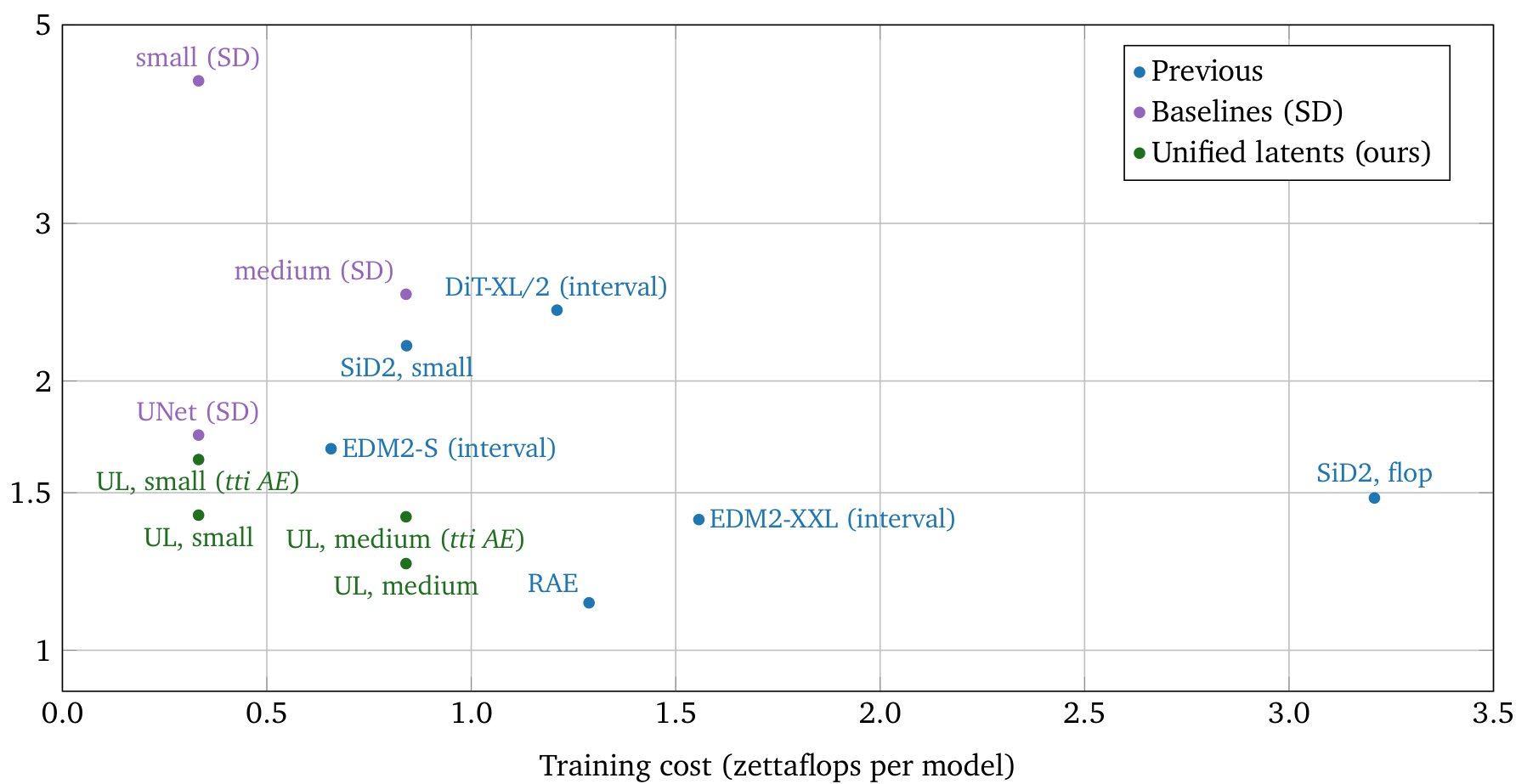
Researchers from Google DeepMind Amsterdam now introduce Unified Latents (UL), a framework that jointly trains an encoder, a diffusion prior, and a diffusion decoder -- where the prior directly regularizes the latents and provides a tight, interpretable upper bound on the latent bitrate. On ImageNet-512, UL achieves 1.4 FID with the best training efficiency among all compared methods, and on Kinetics-600, it sets a new state-of-the-art FVD of 1.3.
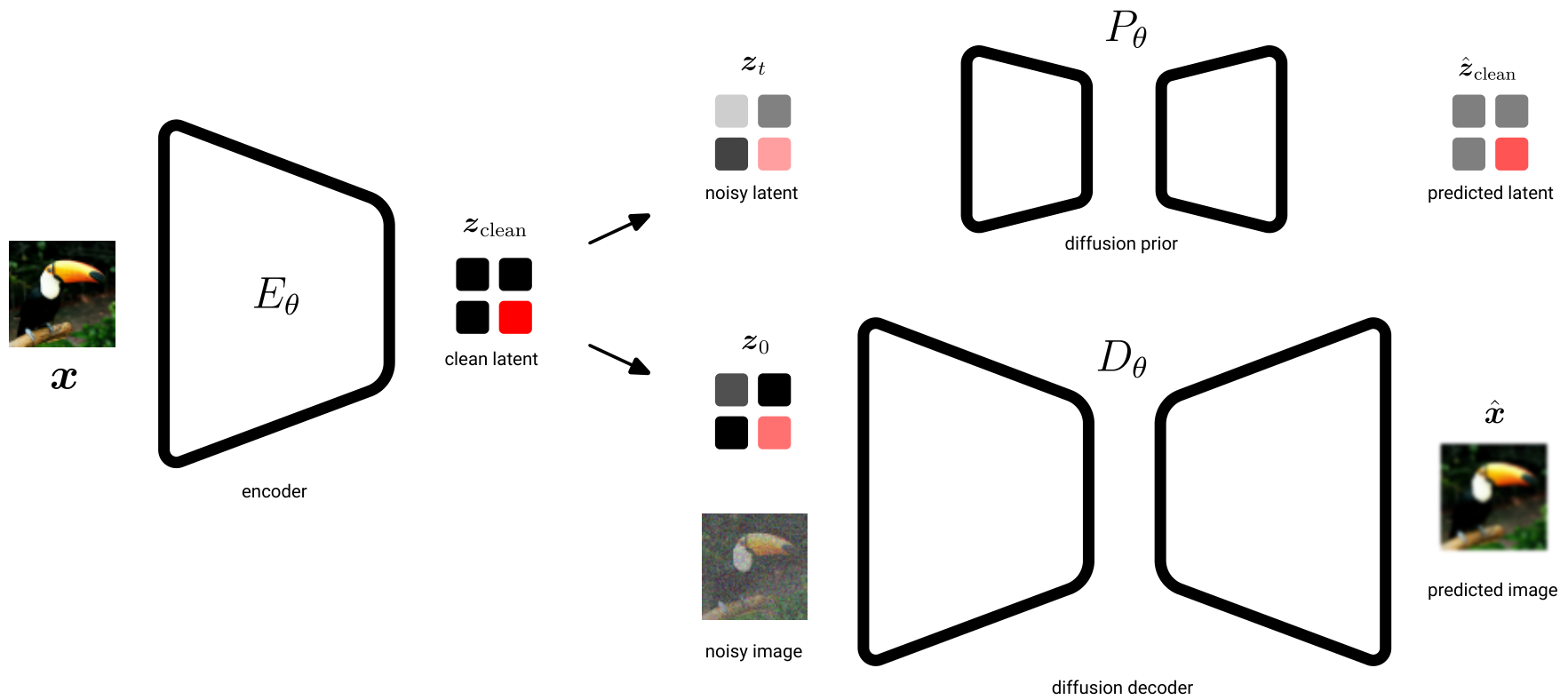 UL OverviewSchematic overview of the Unified Latents model showing the encoder, diffusion prior, and diffusion decoder pathways from image to reconstruction.
UL OverviewSchematic overview of the Unified Latents model showing the encoder, diffusion prior, and diffusion decoder pathways from image to reconstruction.
The Key Insight: Linking Encoder Noise to Prior Precision
The central innovation is deceptively simple. Instead of having the encoder predict a mean and variance (as in standard VAEs), UL uses a deterministic encoder that outputs a clean latent z_clean, which is then forward-noised by a fixed amount of Gaussian noise at log-SNR = 5 (corresponding to sigma of roughly 0.08). This fixed noise level is deliberately set to match the minimum noise level of the diffusion prior.
This link has a powerful consequence: the KL term in the variational bound reduces to a standard diffusion loss -- a weighted MSE over noise levels -- making the prior's loss a tight upper bound on the latent bitrate in bits. Unlike LSGM [7], which required a separate encoder entropy term that caused training instability, UL's fixed-noise approach sidesteps this entirely, yielding a two-term training objective (prior loss + decoder loss) with just two interpretable hyperparameters: the loss factor and the sigmoid bias.
How Unified Latents Works
UL training proceeds in two stages. In Stage 1, the encoder, diffusion prior, and diffusion decoder are trained jointly. The encoder compresses an image to a 32x32 latent representation (16x downsampling). The diffusion prior operates in latent space, modeling the path from pure noise to the slightly noisy latent z0, using an unweighted ELBO loss to ensure the prior provides an honest bitrate estimate. The diffusion decoder reconstructs the image from z0, using a reweighted ELBO with sigmoid weighting and a loss factor that controls how much information flows through the latents versus being modeled by the decoder.
In Stage 2, the encoder is frozen and a larger base model is retrained on the latents with sigmoid weighting, enabling scaling to larger batch sizes and model capacities. During inference, the base model generates z0 from random noise via diffusion, and the decoder generates the final image.
 UL PipelineDetailed pipeline: an image is encoded to z_clean, the diffusion prior models the path from noise z1 to noisy latent z0, and the diffusion decoder reconstructs the image from z0.
UL PipelineDetailed pipeline: an image is encoded to z_clean, the diffusion prior models the path from noise z1 to noisy latent z0, and the diffusion decoder reconstructs the image from z0.
The Loss Factor: A Single Knob for Quality Trade-offs
A central practical contribution is that the reconstruction-generation trade-off is controlled by a single knob: the loss factor. At loss factor 1.3, the latents carry just 0.035 bits/pixel with rFID of 0.79, yielding the best small-model generation FID of 1.42. At loss factor 1.5, medium models reach their sweet spot with gFID of 1.31 at 0.059 bits/pixel. At loss factor 2.1, bitrate increases to 0.116 bits/pixel with excellent reconstruction (rFID 0.27, PSNR 30.1), but generation FID degrades to 1.58. The pattern is clear: smaller base models benefit most from low-bitrate latents, while larger models can leverage higher bitrate latents effectively.
An important finding is that UL is largely insensitive to the number of latent channels (16 to 64 channels yield gFID between 1.60 and 1.77), contradicting the common assumption that channel bottleneck is the primary regularization mechanism. Only at very low channel counts (4-8) does the encoder fail to pass sufficient information.
Results: State-of-the-Art Efficiency and Video Generation
On ImageNet-512, UL outperforms all compared approaches on the training compute vs. generation quality trade-off. Compared directly to models trained on Stable Diffusion latents using the same architecture, UL achieves substantially better FID at lower compute. Compared to the same team's pixel-space SiD2 [2] (1.5 FID at CVPR 2025), UL achieves 1.4 FID with the added benefit of latent compression for scaling to higher resolutions.
On Kinetics-600 video generation, UL sets a new state-of-the-art FVD of 1.3 with the medium model, surpassing W.A.L.T., MAGVIT-v2, RIN, and Video Diffusion. The small model alone achieves 1.7 FVD at a fraction of the training compute of competitors.
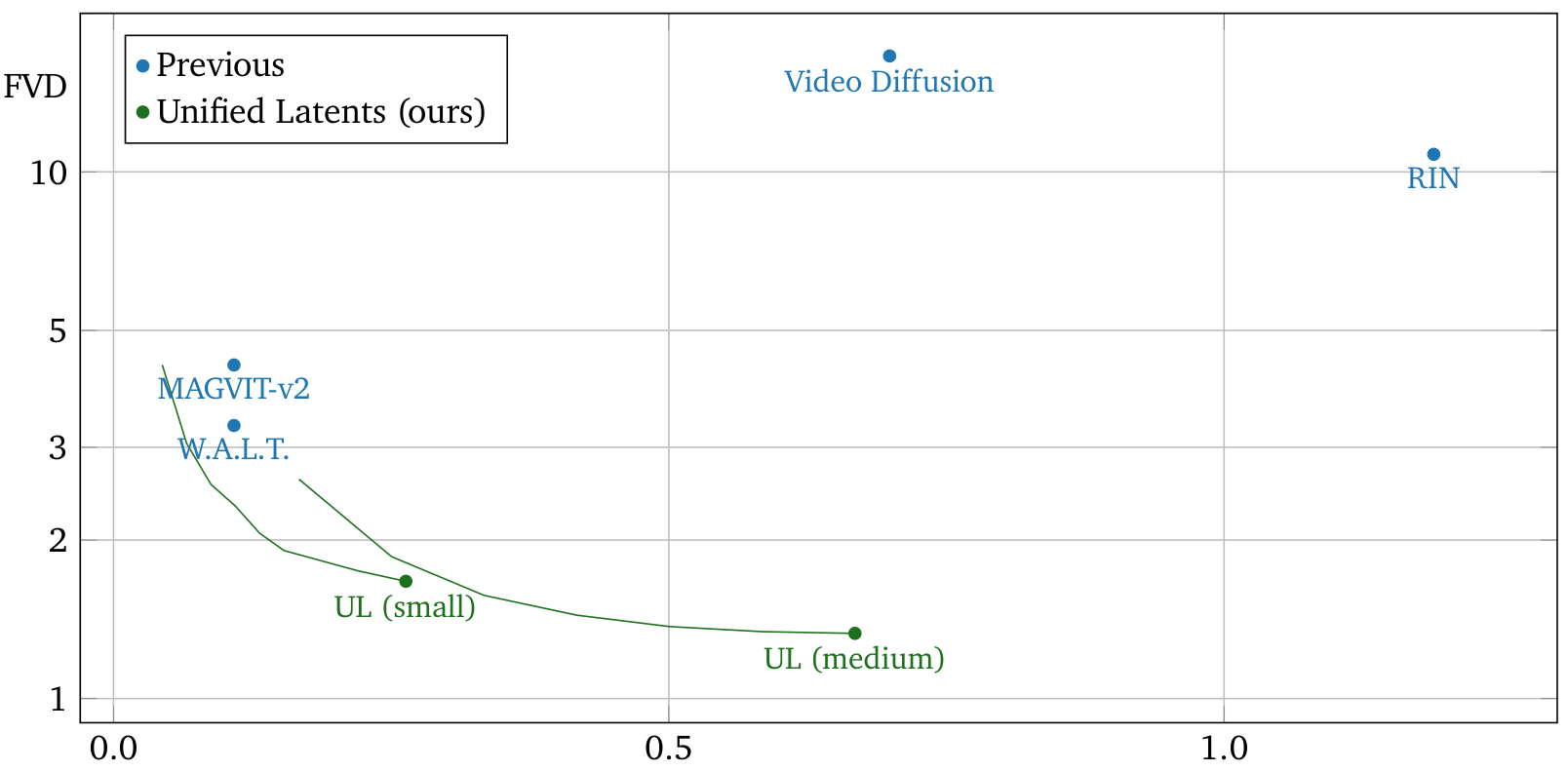 Kinetics-600 ResultsFVD vs. training cost on Kinetics-600. UL outperforms all baselines on training efficiency, with the medium model achieving state-of-the-art 1.3 FVD.
Kinetics-600 ResultsFVD vs. training cost on Kinetics-600. UL outperforms all baselines on training efficiency, with the medium model achieving state-of-the-art 1.3 FVD.
For text-to-image generation on internal datasets, UL achieves 4.1 gFID@30K with CLIP score 27.1, compared to 5.0/27.0 for pixel diffusion and 6.8/27.0 for Stable Diffusion latents [1] -- a 40% FID improvement over SD latents with slightly better text alignment.
Research Context
This work builds on the LSGM framework [7], which first combined a diffusion prior with a VAE but suffered from training instability due to the encoder entropy term. UL also extends the team's own SiD2 [2] from pixel-space to latent-space diffusion.
What's genuinely new: The linking of encoder noise to prior precision eliminates the need for learned encoder variance and provides a tight bitrate bound -- a theoretical contribution absent from competing approaches like epsilon-VAE [3] and SWYCC [4]. The demonstration that latent channels are largely irrelevant when a diffusion prior provides regularization challenges a core assumption of existing latent diffusion design.
Compared to DC-AE [5], which achieves extreme compression ratios (up to 128x), UL focuses on the interplay between autoencoder design and downstream generation quality rather than compression alone. For scenarios requiring maximum compression or fast inference with GAN decoders, alternatives remain preferable -- UL's diffusion decoder is an order of magnitude slower to sample from than GAN-based decoders without additional distillation.
Open questions: How does total system cost (including autoencoder training) compare to pixel-space SiD2? Can decoder distillation close the inference speed gap with GAN decoders? What scaling laws govern optimal bitrate as a function of training budget?
Limitations
The authors acknowledge that diffusion decoders are significantly more expensive at inference time than GAN-based alternatives, and that comparisons are complicated by differences in autoencoder training data across methods. The end-to-end single-stage training variant achieved only FID of roughly 4, suggesting the two-stage procedure remains necessary for competitive results. Autoencoder training cost is also excluded from the FLOP comparisons in the main efficiency plots, which somewhat moderates the training efficiency claims.
Check out the Paper. All credit goes to the researchers.
References
[1] Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. arXiv
[2] Hoogeboom, E. et al. (2024). Simpler Diffusion (SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion. CVPR 2025. arXiv
[3] Zhao, L. et al. (2025). Epsilon-VAE: Denoising as Visual Decoding. ICML 2025. arXiv
[4] Birodkar, V. et al. (2024). Sample What You Can't Compress (SWYCC). arXiv. arXiv
[5] Chen, J. et al. (2024). Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models. ICLR 2025. arXiv
[6] Shi, M. et al. (2025). Latent Diffusion Model without Variational Autoencoder. arXiv. arXiv
[7] Vahdat, A. et al. (2021). Score-based Generative Modeling in Latent Space (LSGM). NeurIPS 2021. arXiv