UPLiFT vs Cross-Attention Upsamplers: Linear Scaling Meets SOTA Quality
Cross-attention feature upsamplers hit a wall at high resolutions - they run out of memory.
Vision Transformers have become the backbone of modern computer vision, but they face a fundamental limitation: patch tokenization forces them to produce low-resolution feature maps. For dense prediction tasks like semantic segmentation and depth estimation, these coarse features need to be upsampled to pixel density. Recent methods like JAFAR [2] and LoftUp [3] use cross-attention to achieve high-quality upsampling, but this comes at a cost - quadratic time and memory scaling that causes out-of-memory errors at higher resolutions.
Building on their prior work LiFT [1], researchers from the University of Maryland and Meta have developed UPLiFT (Universal Pixel-dense Lightweight Feature Transforms), a feature upsampler that achieves state-of-the-art quality while maintaining linear scaling. The key innovation is the Local Attender operator, which reformulates attention to operate over fixed local neighborhoods instead of the full feature map.
The Feature Resolution Problem
Pre-trained visual backbones like DINOv2 [6] provide powerful features for downstream tasks, but their spatial resolution is limited by the patch size used during tokenization. A 448x448 image processed with 14x14 patches yields only a 32x32 feature map. While it is possible to increase token density by using smaller patches, the self-attention cost scales quadratically with the number of tokens, making this approach impractical.
Feature upsampling methods offer a shortcut: train a lightweight module to transform coarse backbone features into dense, pixel-level representations while preserving semantic content. Early approaches like LiFT [1] used simple iterative 2x upsampling, but this led to "semantic drift" where features degraded after multiple iterations. Cross-attention methods solved this by enforcing that output features are linear combinations of input features, but at the cost of quadratic complexity.
Local Attender: Attention Without the Quadratic Cost
UPLiFT's key contribution is the Local Attender operator, which achieves the feature consistency benefits of cross-attention while maintaining linear complexity. The insight comes from the authors' prior work [7] showing that ViT attention heads often learn to attend to fixed directional offsets rather than computing global relationships.
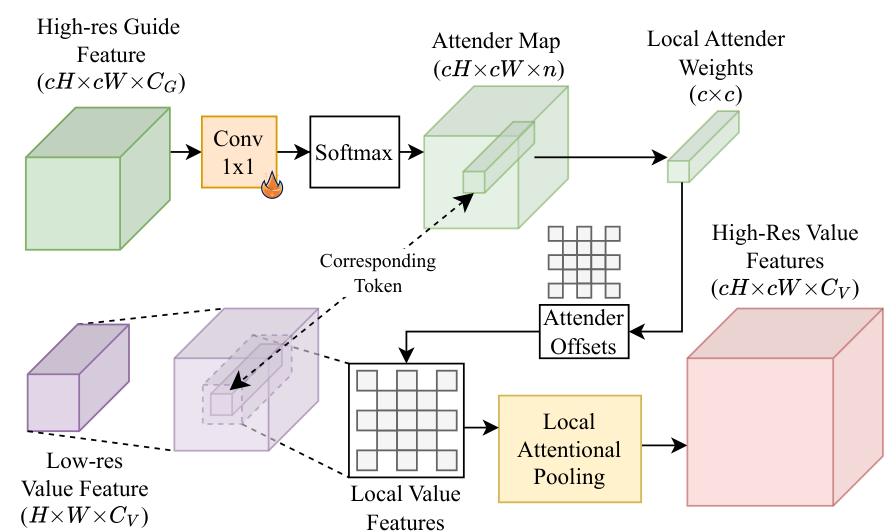 Local AttenderThe Local Attender operator computes attention over a fixed neighborhood defined by directional offsets, avoiding the quadratic cost of full cross-attention.
Local AttenderThe Local Attender operator computes attention over a fixed neighborhood defined by directional offsets, avoiding the quadratic cost of full cross-attention.
Instead of learning query-key-value projections, the Local Attender defines attention over a pre-set neighborhood of fixed 2D directional offsets. For each position, it computes attention weights to gather features only from these local neighbors. A 1x1 convolution transforms guide features into attention weights, which are applied via softmax to pool local value features. The result is an output that is always a linear combination of input features - ensuring semantic preservation - with O(nT) complexity where n is the neighborhood size and T is the token count.
Architecture Overview
UPLiFT consists of two main modules working together:
UPLiFT Encoder (EUPLiFT): A shallow convolutional encoder that processes the input image once to extract dense, pixel-resolution guide features. Unlike LiFT which required re-running its encoder at each upsampling step, UPLiFT's encoder runs once and its output is downsampled as needed.
UPLiFT Decoder (DUPLiFT): A compact convolutional module that performs 2x upsampling. It takes low-resolution backbone features and appropriately-sized guide features to predict upsampled features. The same decoder is applied iteratively to achieve pixel-dense upsampling.
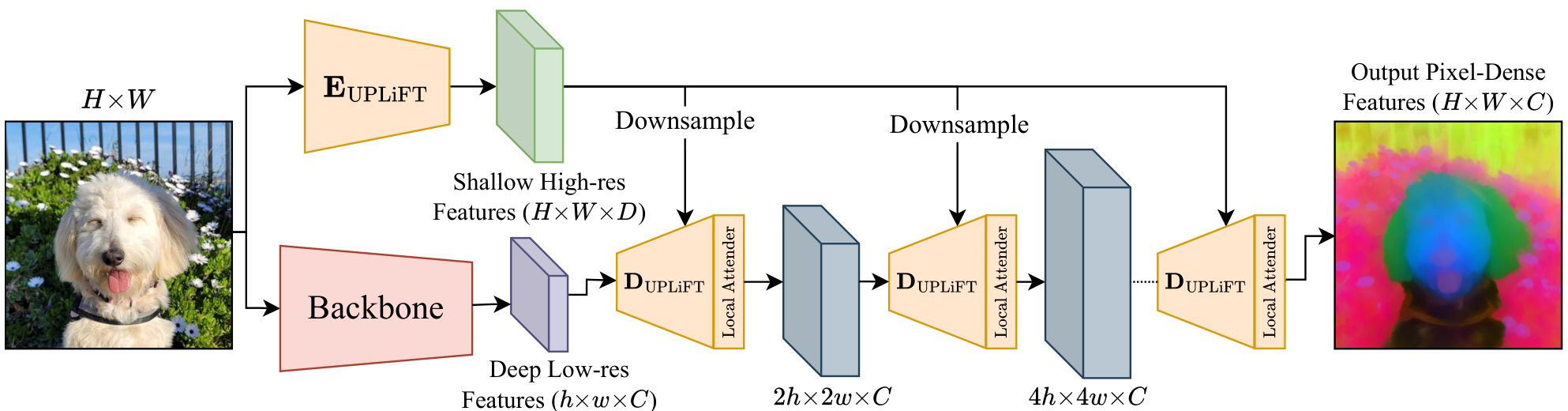 UPLiFT ArchitectureThe inference pipeline shows input image processing through the backbone and encoder, with iterative decoder application guided by Local Attender to produce pixel-dense features.
UPLiFT ArchitectureThe inference pipeline shows input image processing through the backbone and encoder, with iterative decoder application guided by Local Attender to produce pixel-dense features.
The Local Attender is integrated as the final step of each decoder application, ensuring that upsampled features remain linear combinations of the original backbone features throughout the iterative process.
Benchmark Results
UPLiFT achieves state-of-the-art results on semantic segmentation across four benchmarks while being significantly faster than cross-attention alternatives:
| Dataset | UPLiFT | Best Competitor | Improvement | |---------|--------|-----------------|-------------| | COCO-Stuff | 62.55% mIoU | AnyUp: 62.08% | +0.47% | | Pascal VOC | 85.21% mIoU | LoftUp: 84.63% | +0.58% | | Cityscapes | 65.38% mIoU | LoftUp: 62.09% | +3.29% | | ADE20K | 42.97% mIoU | AnyUp: 42.25% | +0.72% |
On inference speed at 448x448 resolution, UPLiFT runs at 79.4ms compared to JAFAR at 111.7ms, AnyUp at 146.7ms, and LoftUp at 223.5ms. More importantly, UPLiFT's linear scaling means this advantage grows at higher resolutions - it handles up to 2601 visual tokens before hitting 24GB memory limits, while cross-attention methods fail at around 1500 tokens (624x624 images).
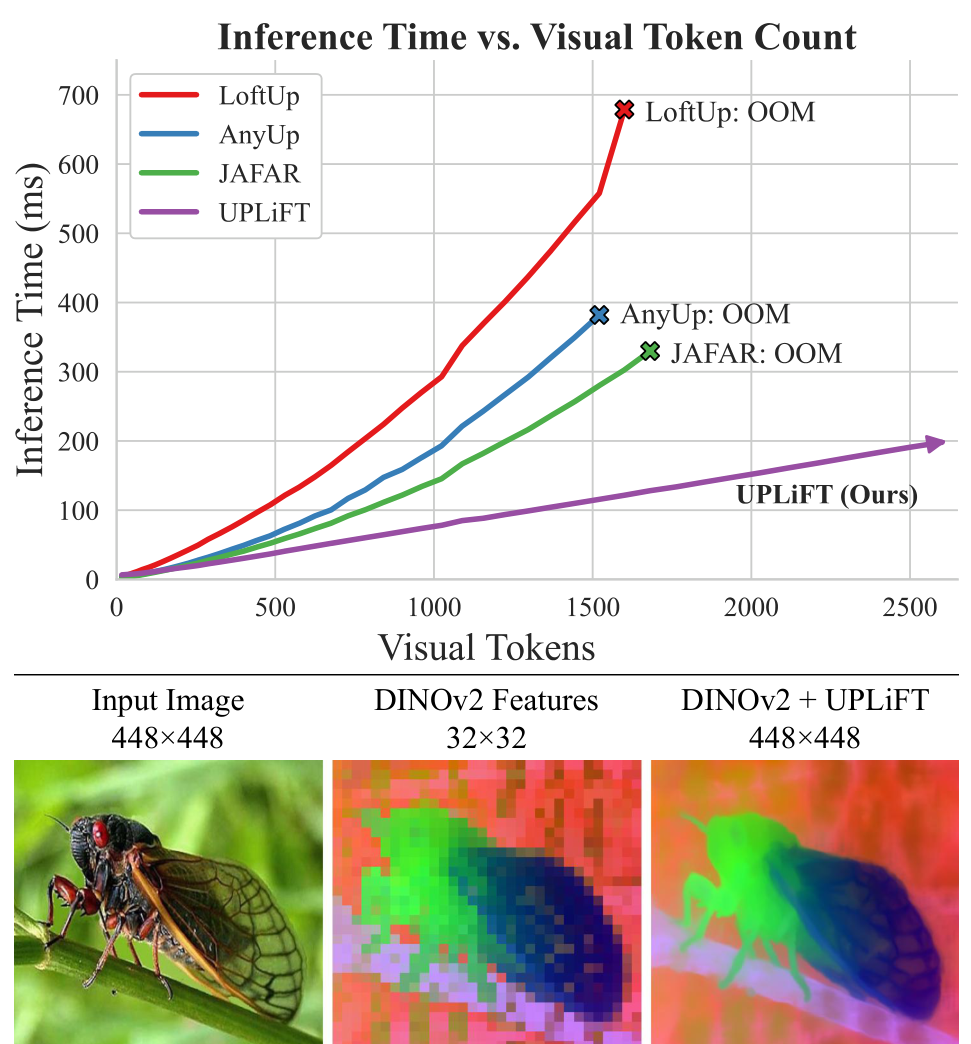 Scaling ComparisonUPLiFT maintains linear time scaling while cross-attention methods show quadratic growth and run out of memory at approximately 1500 visual tokens.
Scaling ComparisonUPLiFT maintains linear time scaling while cross-attention methods show quadratic growth and run out of memory at approximately 1500 visual tokens.
Generative Applications
Beyond predictive tasks, UPLiFT extends to VAE latent upsampling for image generation. When applied to Stable Diffusion 1.5 outputs, UPLiFT achieves a FID of 24.23 for 512-to-1024 upscaling on COCO - better than CFM's 28.81 FID with 41% faster inference. The method uses only 53M parameters compared to CFM's 306M, and trains on 25k images versus CFM's 5 million.
For image super-resolution (256 to 1024), UPLiFT achieves 0.84 SSIM on FacesHQ compared to CFM's 0.82, using just 2 iterations versus CFM's 50. Notably, UPLiFT trains for just 1 epoch on ImageNet-1K for predictive tasks, demonstrating remarkable data efficiency.
Research Context
This work builds on LiFT [1], which introduced iterative 2x feature upsampling with self-supervised training. UPLiFT addresses LiFT's limitation of semantic drift through the Local Attender mechanism, which was inspired by the authors' prior research on ViT attention patterns [7].
What's genuinely new: The Local Attender operator represents a novel reformulation of attention for feature upsampling. By operating over fixed directional offsets instead of learned QKV projections, it achieves linear complexity while maintaining the feature consistency guarantee of cross-attention. UPLiFT is also the first iterative upsampler to demonstrate competitive results on both predictive and generative tasks.
Compared to JAFAR [2], UPLiFT achieves +0.84% mIoU on COCO segmentation while being 29% faster. UPLiFT scales linearly with tokens while JAFAR scales quadratically, giving UPLiFT increasing advantage at higher resolutions. However, JAFAR offers flexible arbitrary-resolution output while UPLiFT is constrained to powers-of-2 upsampling.
Open questions:
- How does Local Attender neighborhood size affect the efficiency-quality tradeoff?
- Can UPLiFT be adapted for arbitrary resolution upsampling while maintaining linear scaling?
- Does the local attention assumption hold for visual domains requiring global context?
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Suri, S. et al. (2024). LiFT: A Surprisingly Simple Lightweight Feature Transform for Dense ViT Descriptors. ECCV 2024. arXiv
[2] Couairon, P. et al. (2025). JAFAR: Jack up Any Feature at Any Resolution. arXiv preprint. arXiv
[3] Huang, H. et al. (2025). LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. arXiv preprint. arXiv
[4] Wimmer, T. et al. (2025). AnyUp: Universal Feature Upsampling. arXiv preprint. arXiv
[5] Fu, S. et al. (2024). FeatUp: A Model-Agnostic Framework for Features at Any Resolution. ICLR 2024. arXiv
[6] Oquab, M. et al. (2023). DINOv2: Learning Robust Visual Features Without Supervision. arXiv preprint. arXiv
[7] Walmer, M. et al. (2023). Teaching Matters: Investigating the Role of Supervision in Vision Transformers. CVPR 2023. arXiv


