VLM Hallucinations Exposed: VIB-Probe Pinpoints and Suppresses Faulty Attention Heads
Researchers discover that hallucinations in vision-language models leave fingerprints in specific attention heads - and they've built a tool to detect and suppress them at inference time without touching model weights.
Vision-language models are increasingly deployed in real-world applications, from medical imaging analysis to autonomous vehicle perception. Yet a persistent problem threatens their reliability: hallucinations, where generated text describes objects, attributes, or relationships that simply do not exist in the input image. Unlike previous approaches that rely on output logits or external verification tools [1, 2], a new framework from Fudan University tackles the problem at its source by examining what happens inside the model's attention mechanisms.
The researchers propose VIB-Probe, which applies Variational Information Bottleneck theory to extract hallucination signals from attention head outputs across all transformer layers. The method not only detects hallucinations with state-of-the-art accuracy but also provides an inference-time intervention strategy that suppresses problematic attention heads without requiring model retraining.
The Attention Head Hypothesis
Recent interpretability research suggests that VLM hallucinations emerge from fragile attention dynamics introduced when processing visual information [3]. Models may attend to irrelevant image regions, infer non-existent objects, or over-rely on linguistic priors rather than visual grounding. Critically, these hallucination-related signals are not confined to the final output layer but emerge progressively across internal layers.
VIB-Probe capitalizes on this insight by examining the raw outputs of individual attention heads before they are combined in the final head-mixing step. For each generated token, the framework extracts a tensor of attention head outputs spanning all L layers and H heads, creating a comprehensive snapshot of the model's internal multimodal processing.
How VIB-Probe Works
The framework operates in three stages. First, during VLM decoding, raw output vectors are extracted from all attention heads across all transformer layers. This produces a high-dimensional representation for each token being generated.
Second, these features pass through an Information Bottleneck encoder that compresses them into a compact latent representation. The key insight from information theory [6] is that this compression step filters out task-irrelevant noise while retaining the minimal sufficient statistics needed to predict hallucinations. The encoder learns a variational distribution constrained by KL divergence against a standard Gaussian prior, effectively forcing the model to discard semantic nuisances unrelated to visual grounding.
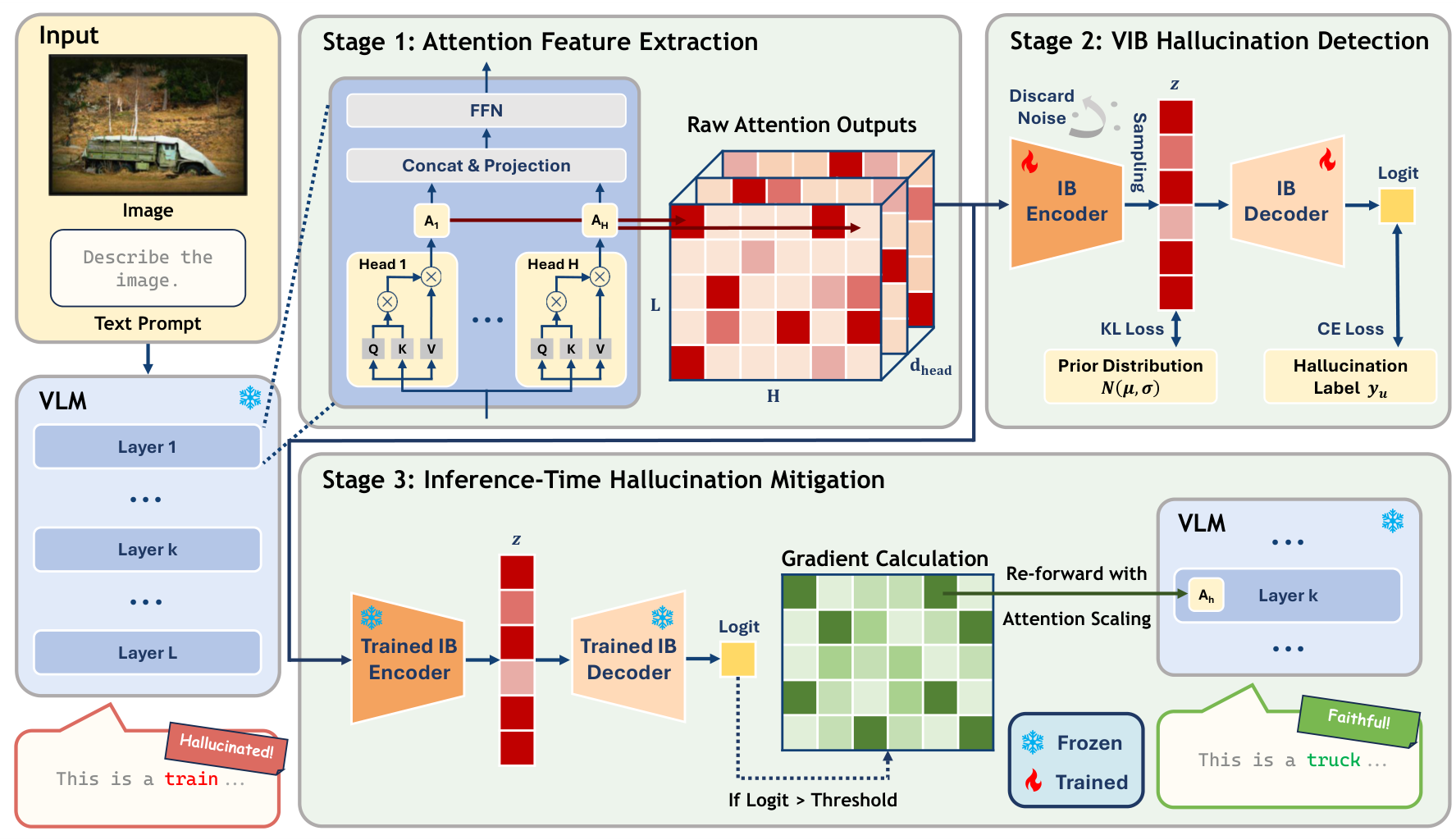 VIB-Probe FrameworkThe three-stage pipeline extracts attention outputs from all transformer layers, compresses them through an information bottleneck encoder, and uses gradient-based attribution to identify and suppress hallucination-sensitive heads at inference time.
VIB-Probe FrameworkThe three-stage pipeline extracts attention outputs from all transformer layers, compresses them through an information bottleneck encoder, and uses gradient-based attribution to identify and suppress hallucination-sensitive heads at inference time.
Third, when the detector flags a high hallucination risk, the framework triggers an intervention. It computes the gradient of the risk logit with respect to each attention head's output. The heads with the largest gradient magnitudes are identified as most influential for the hallucination. These heads are then suppressed by scaling down their outputs, and the token is regenerated with a more faithful result.
State-of-the-Art Detection Results
VIB-Probe was evaluated across four VLM architectures (MiniGPT-4, LLaVA-v1.5-7B, LLaVA-v1.6-Mistral-7B, and Qwen2.5-VL-7B-Instruct) on both discriminative and generative benchmarks.
On discriminative tasks using the POPE benchmark [7], VIB-Probe achieves 95.56% AUPRC averaged across all models, compared to 94.25% for the previous best method DHCP [1]. On the more challenging generative benchmarks, the gains are larger: 80.41% AUPRC on M-HalDetect versus 78.52% for DHCP, and 67.29% on COCO-Caption versus 64.73%.
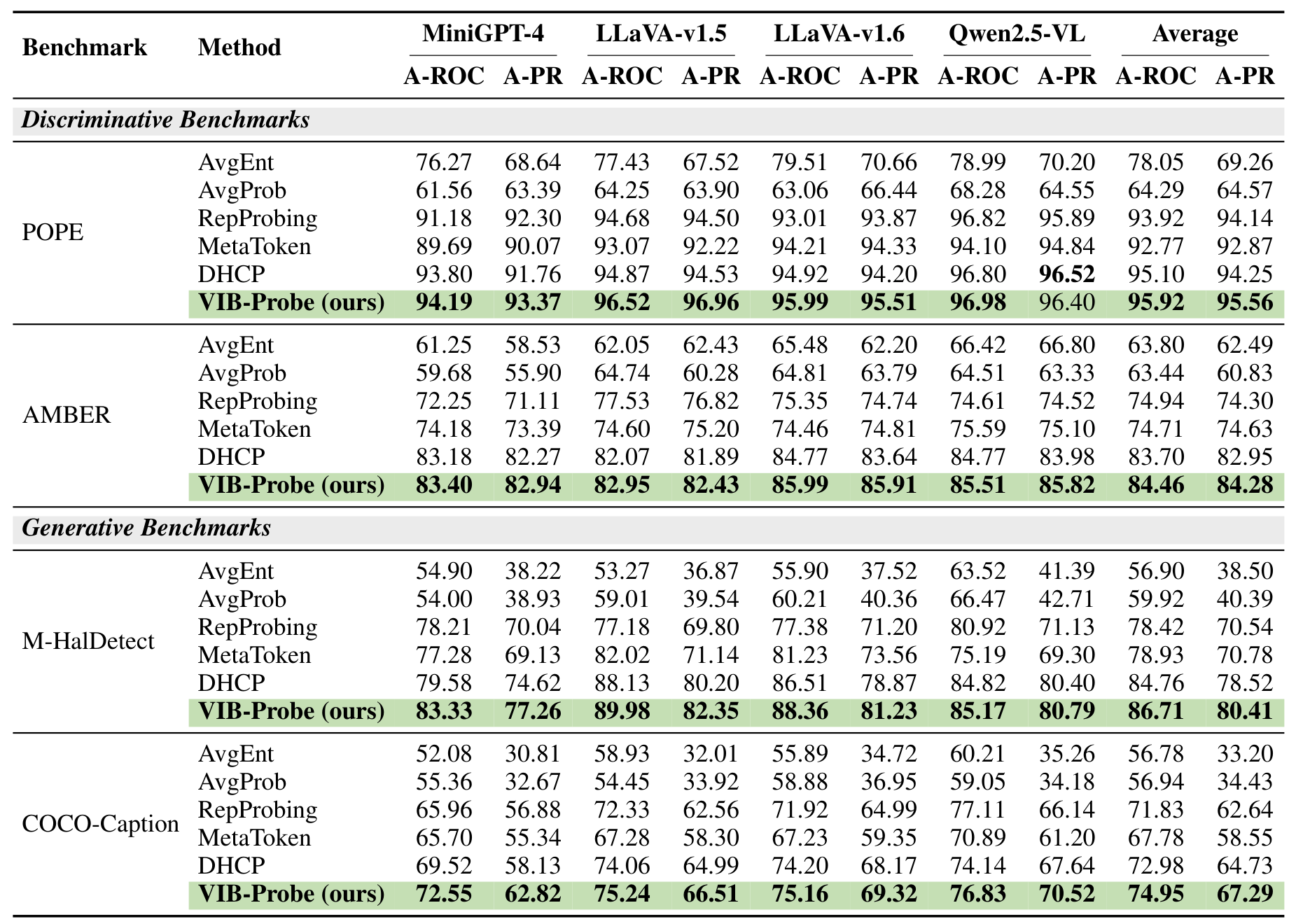 Detection ResultsPerformance comparison across discriminative (POPE, AMBER) and generative (M-HalDetect, COCO-Caption) benchmarks showing VIB-Probe consistently outperforming baselines.
Detection ResultsPerformance comparison across discriminative (POPE, AMBER) and generative (M-HalDetect, COCO-Caption) benchmarks showing VIB-Probe consistently outperforming baselines.
A particularly striking finding is VIB-Probe's generalization ability. When a detector trained on POPE-Popular is applied to other test sets, baseline methods like RepProbing show a 32.4% performance decline on M-HalDetect. VIB-Probe maintains much stronger performance, suggesting the information bottleneck successfully distills domain-invariant hallucination signals rather than dataset-specific biases. Notably, the ablation studies show that deeper layers are more informative for hallucination detection, likely because cross-modal information is not yet fully fused in shallow layers.
Inference-Time Mitigation
Beyond detection, VIB-Probe's intervention strategy reduces actual hallucinations in generated outputs. On the POPE benchmark with LLaVA-v1.6, the method achieves 88.2% accuracy and 89.5% F1 score, outperforming both Visual Contrastive Decoding (VCD) [4] and Paying Attention to Image (PAI) [5].
For open-ended captioning measured by CHAIR metrics, VIB-Probe reduces CHAIRi to 8.7% (versus 9.0% for VCD and 9.2% for PAI) and CHAIRs to 32.1% (versus 36.4% for VCD and 35.3% for PAI). This represents a meaningful reduction in object-level hallucinations without requiring any model retraining.
Ablation studies confirm that the information bottleneck constraint is essential to these gains. Removing the KL loss from training degrades detection performance to levels comparable with simple linear probing baselines.
Research Context
This work builds on a lineage of attention-based hallucination analysis. Lookback Lens [2] showed that attention patterns during decoding can discriminate grounded from hallucinatory outputs. DHCP [1] extended this by training probes on cross-modal attention patterns. VIB-Probe's contribution is applying information bottleneck theory to filter noise from these high-dimensional attention representations.
What's genuinely new: First application of Variational Information Bottleneck to VLM hallucination detection; unified detection-and-mitigation framework without model retraining; demonstrated domain-invariant signal extraction with strong cross-task generalization.
Compared to DHCP, VIB-Probe offers 1-3% AUPRC improvements across benchmarks and significantly better cross-task transfer. For scenarios requiring zero training overhead and simpler implementation, VCD or PAI remain viable alternatives despite lower peak performance.
Open questions:
- Can VIB-Probe be adapted for black-box VLMs without internal access?
- Do the identified hallucination-sensitive heads transfer across VLM architectures?
- What is the computational overhead in practical deployment scenarios?
Limitations
The method requires white-box access to the model's internal attention outputs, limiting applicability to API-only services like GPT-4V or Claude. It also requires training a lightweight probe for each VLM architecture, adding a setup cost that fully training-free methods like VCD avoid. The paper does not report computational overhead from the gradient computation and re-forwarding required during intervention.
Check out the Paper. All credit goes to the researchers. Code will be released by the authors.
References
[1] Zhang, Y. et al. (2025). DHCP: Detecting Hallucinations by Cross-modal Attention Pattern in Large Vision-Language Models. Proceedings of the 33rd ACM International Conference on Multimedia.
[2] Chuang, Y. et al. (2024). Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps. arXiv preprint. arXiv
[3] Huang, Q. et al. (2024). OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation. CVPR 2024. arXiv
[4] Leng, S. et al. (2024). Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding. CVPR 2024. arXiv
[5] Liu, S. et al. (2024). Paying More Attention to Image: A Training-Free Method for Alleviating Hallucination in LVLMs. ECCV 2024. arXiv
[6] Alemi, A. et al. (2017). Deep Variational Information Bottleneck. ICLR 2017. arXiv
[7] Li, Y. et al. (2023). Evaluating Object Hallucination in Large Vision-Language Models. EMNLP 2023. arXiv


