Why Chain-of-Thought Works: Researchers Find a Single 'Reasoning Switch' in LLMs
What if Chain-of-Thought prompting isn't actually teaching your model to reason - but just flipping an internal switch that was there all along?
Chain-of-Thought (CoT) prompting has become the go-to technique for improving LLM reasoning, but a fundamental question has remained unanswered: why does asking a model to "think step by step" actually improve its math and logic performance? New research from the University of Virginia provides a surprising answer - CoT prompting appears to activate a latent "reasoning mode" that already exists within the model, and this mode can be triggered directly by manipulating a single internal feature.
Building on sparse autoencoder (SAE) interpretability methods - which decompose neural network activations into interpretable "features" representing specific concepts or behaviors [2] - the researchers developed a two-stage pipeline to identify and validate reasoning-related features in LLM hidden states. Unlike previous work on implicit reasoning through knowledge distillation [4] or decoding modifications [3], this approach provides direct evidence that reasoning is a distinct internal state that can be externally controlled without any model fine-tuning.
The Discovery: Reasoning as a Latent Mode
The core insight is that multi-step reasoning in LLMs corresponds to specific latent features that activate early in the generation process. Using Sparse Autoencoders (SAEs) to decompose model activations into interpretable features, the researchers compared feature activations under direct prompting ("give me the answer") versus CoT prompting ("let's think step by step").
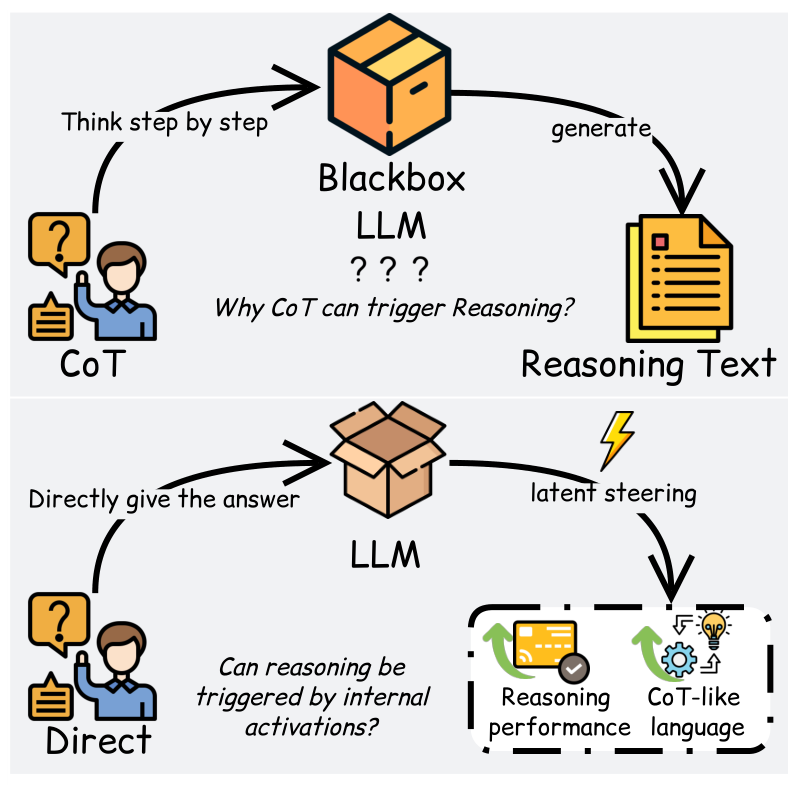 Latent Reasoning TriggersTop: Traditional CoT prompting where the internal mechanism is unclear. Bottom: The paper's view of reasoning as a latent mode triggered by different mechanisms, including direct feature steering.
Latent Reasoning TriggersTop: Traditional CoT prompting where the internal mechanism is unclear. Bottom: The paper's view of reasoning as a latent mode triggered by different mechanisms, including direct feature steering.
The analysis revealed that certain features consistently activate more strongly under CoT conditions, with statistical significance (point-biserial correlation r = 0.14, p = 0.006). More importantly, these features peak very early in generation - within the first few tokens - and then decay, suggesting they function as a "trigger" for entering a reasoning mode rather than maintaining it throughout.
How Latent Steering Works
The methodology consists of two stages: feature discovery and causal validation.
Feature Discovery: The researchers extract hidden activations from both direct and CoT prompts across the same questions, project these through a pretrained SAE encoder to get sparse latent features, then identify features with the largest activation difference between conditions.
Causal Validation: To confirm these features actually cause reasoning behavior (rather than just correlating with it), the researchers apply targeted steering interventions. They modify pre-activation values for selected features by adding a scaled perturbation, decode back to activation space, and inject the residual into the model.
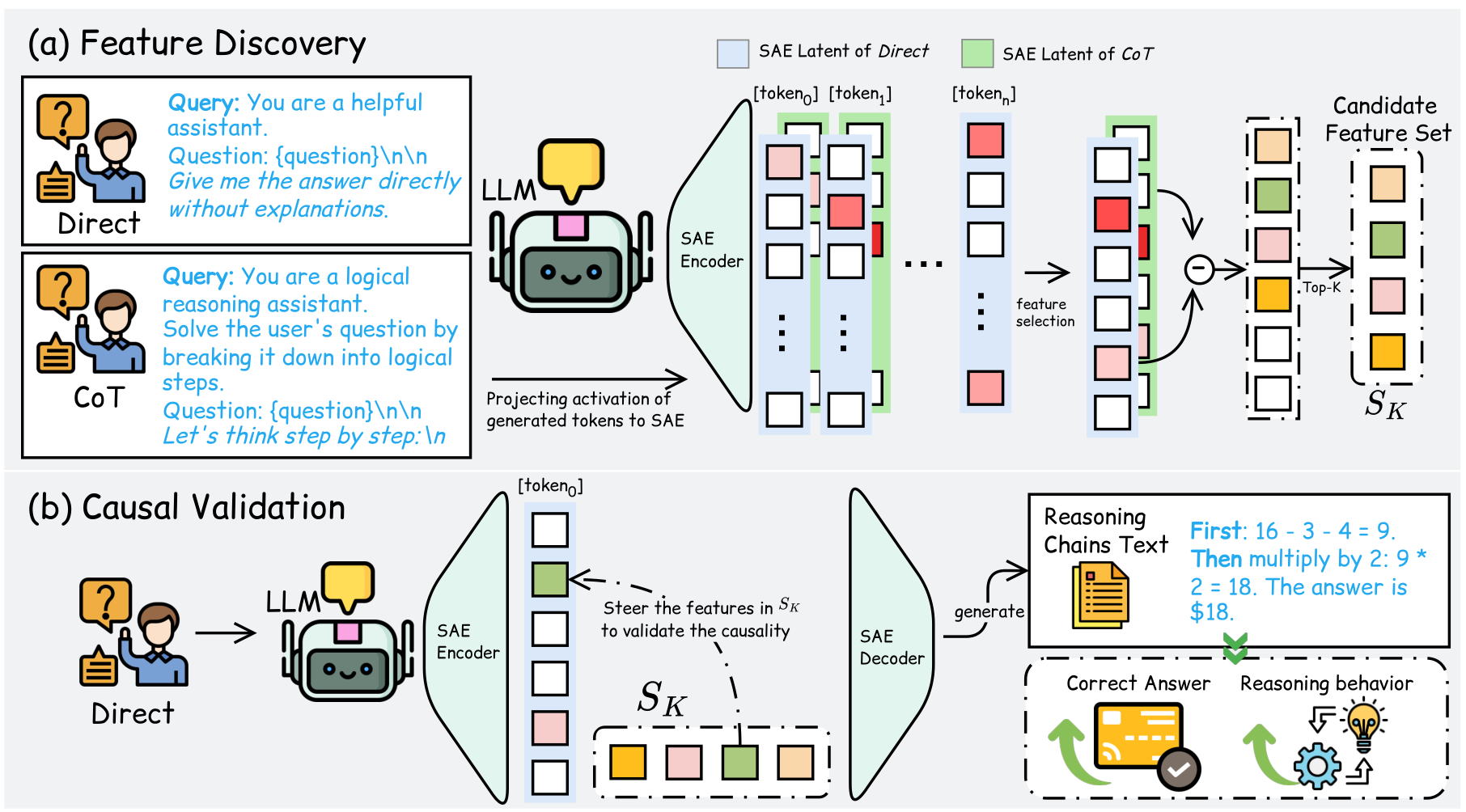 Two-Stage PipelineOverview of the feature discovery (a) and causal validation (b) process. SAE projections reveal differential features between direct and CoT prompting, which are then validated through targeted steering interventions.
Two-Stage PipelineOverview of the feature discovery (a) and causal validation (b) process. SAE projections reveal differential features between direct and CoT prompting, which are then validated through targeted steering interventions.
The key technical innovation is applying this intervention at only the first generation token - a minimal, targeted perturbation that triggers the reasoning mode without continuous manipulation.
Results: CoT Performance Without CoT Tokens
The results across six models and three benchmarks demonstrate that steering a single reasoning feature can dramatically improve performance without explicit CoT prompting.
On GSM8K (grade school math), steering LLaMA-3.1-8B under direct prompting achieved 73.3% accuracy compared to 24.5% baseline - recovering most of the CoT performance (79.3%) without generating lengthy reasoning chains. For the larger LLaMA-3.3-70B, steered direct prompting reached 88.8% accuracy with only 53 tokens on average, compared to CoT's 96.1% accuracy requiring 268 tokens - a 5x reduction in output length with only modest accuracy loss.
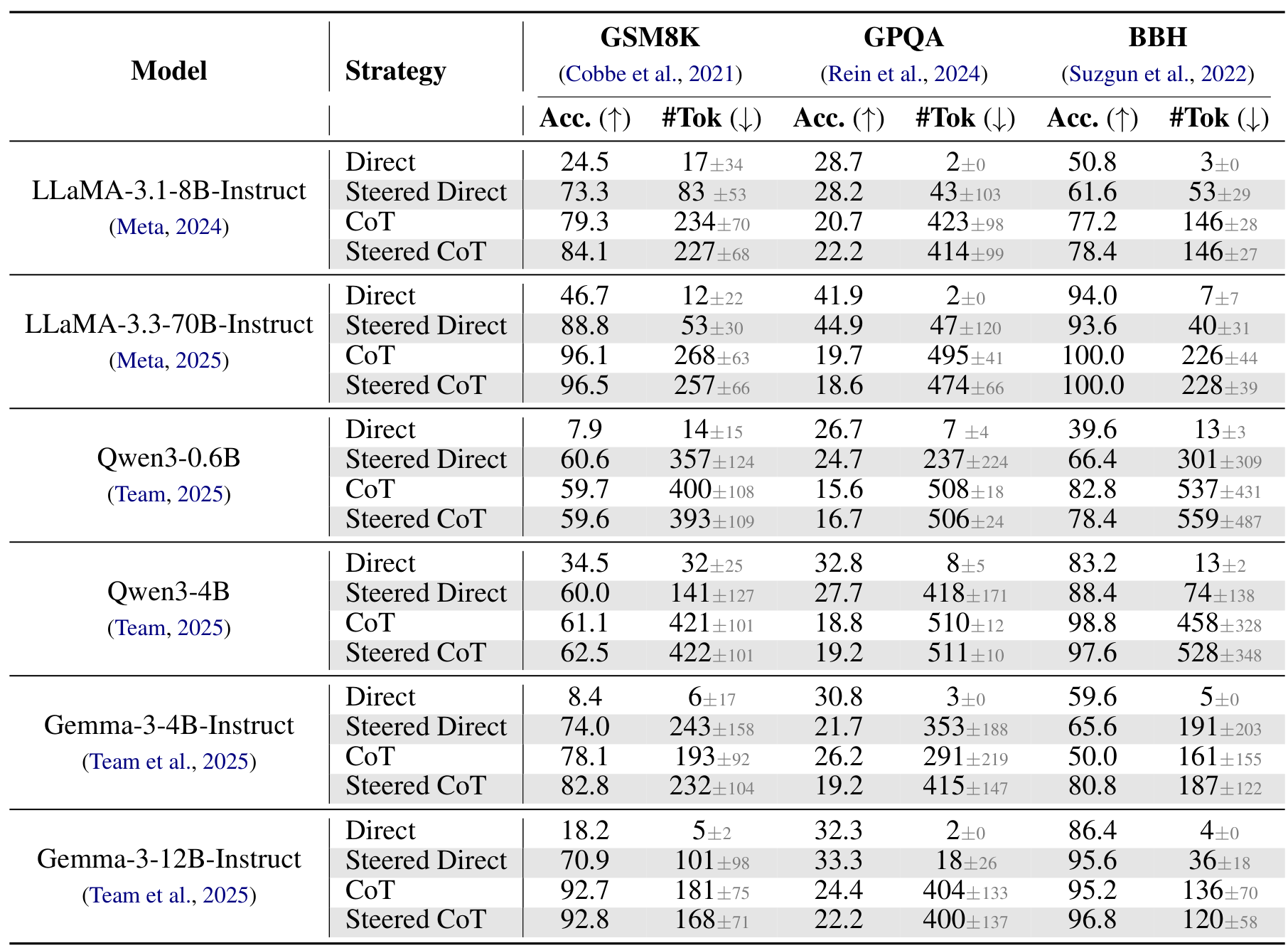 Benchmark ResultsPerformance across models and benchmarks showing that steered direct prompting achieves near-CoT accuracy with substantially fewer tokens.
Benchmark ResultsPerformance across models and benchmarks showing that steered direct prompting achieves near-CoT accuracy with substantially fewer tokens.
Perhaps most strikingly, latent steering can override explicit anti-reasoning instructions. On Qwen models, which support a \no_think token designed to suppress reasoning, steering still induced coherent multi-step reasoning despite the prompt explicitly discouraging it.
When Steering Works (and When It Doesn't)
The technique shows strong benefits on tasks that genuinely require multi-step reasoning. On Big-Bench Hard's logical deduction task, Gemma-3-12B achieved 95.6% with steered direct prompting, actually exceeding the 95.2% CoT baseline while using far fewer tokens.
However, on GPQA (graduate-level science questions), neither CoT nor steering provided substantial improvements. The authors interpret this as evidence that the identified features specifically enable multi-step reasoning, not general knowledge retrieval. When a task doesn't benefit from reasoning chains, activating the reasoning mode provides little advantage.
Intervention timing matters significantly. Early interventions (first generation token) are most effective, with accuracy dropping sharply when steering is delayed even by a few tokens. This supports the interpretation that the feature functions as a "mode switch" that must be activated at the start of generation.
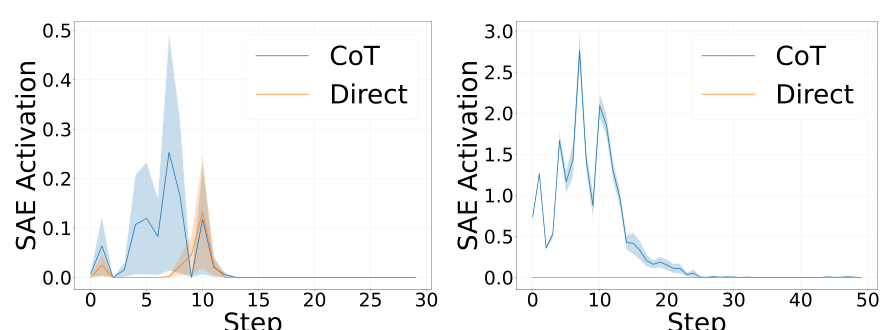 Activation DynamicsReasoning-related SAE features peak early in generation and decay rapidly, with CoT prompting inducing stronger activation than direct prompting.
Activation DynamicsReasoning-related SAE features peak early in generation and decay rapidly, with CoT prompting inducing stronger activation than direct prompting.
Research Context
This work builds directly on the sparse autoencoder methods for interpretable features [2] and prior observations that CoT-style reasoning can be elicited through decoding modifications [3]. The key advancement is demonstrating causal evidence that reasoning is a unified latent mode controllable through single-feature intervention.
What's genuinely new:
- First identification of specific SAE features causally linked to reasoning activation
- Demonstration that a single latent feature is sufficient to trigger reasoning behavior
- Evidence that latent steering can override explicit anti-reasoning prompt instructions
Compared to SoftCoT [5], which achieves similar efficiency goals through learned soft thought tokens, this approach requires no fine-tuning and works on any frozen model with available SAEs. However, SoftCoT offers more seamless integration for teams willing to invest in model-specific training.
Open questions remain about what computation these features actually trigger internally, whether different reasoning types (mathematical, logical, causal) share the same latent features, and why first-token intervention is so much more effective than later interventions.
Implications
The findings suggest a reframing of how we understand LLM reasoning. Rather than viewing CoT prompting as "teaching" a model to reason, it may be more accurate to view it as one trigger among several for activating a pre-existing reasoning capability. This opens possibilities for more efficient inference (getting reasoning quality without verbose outputs) and provides mechanistic insight into one of the most important emergent capabilities in modern LLMs.
For practitioners, the immediate implication is that significant token savings may be achievable through activation-level interventions. However, this currently requires access to pretrained SAEs for the target model - available for LLaMA via Goodfire and Gemma via GemmaScope, but requiring custom training for other model families like Qwen.
Check out the Paper. All credit goes to the researchers.
References
[1] Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv
[2] Cunningham, H. et al. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models. arXiv preprint. arXiv
[3] Wang, X. & Zhou, D. (2024). Chain-of-Thought Reasoning Without Prompting. NeurIPS 2024. arXiv
[4] Deng, Y. et al. (2023). Implicit Chain of Thought Reasoning via Knowledge Distillation. arXiv preprint. arXiv
[5] Xu, Y. et al. (2025). SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs. ACL 2025. arXiv


