Zero Training Data, Full Performance: Dr. Zero Matches Supervised Search Agents
Meta researchers demonstrate that search agents can teach themselves without any human-labeled data, matching models trained on curated datasets.
High-quality training data is becoming the scarcest resource in AI development. While curated datasets have powered the current generation of capable AI systems, the cost and effort of annotation creates bottlenecks that limit progress. What if AI agents could teach themselves instead?
Researchers from Meta Superintelligence Labs and the University of Illinois Urbana-Champaign have introduced Dr. Zero, a framework that enables search agents to self-evolve without any training data. Using Qwen2.5 (3B and 7B variants) as the base model, the system builds on the proposer-solver co-evolution concept from R-Zero [2], which focused on mathematical reasoning. Dr. Zero extends zero-data training to open-domain question answering with multi-turn search tool use. The results across seven QA benchmarks are striking: Dr. Zero matches or exceeds the performance of Search-R1 [1], a fully supervised search agent, on single-hop tasks while using zero human-curated examples.
The Self-Evolution Feedback Loop
At the core of Dr. Zero lies a symbiotic training loop between two agents initialized from the same base model. The proposer generates diverse questions with verifiable answers, while the solver attempts to answer them using reasoning and external search.
The key insight is in how the proposer is rewarded. Rather than simply generating any question, the proposer receives maximum reward when only some of the solver's attempts succeed. If all attempts succeed, the question was too easy; if none succeed, it was impossible. This difficulty-guided reward creates an automated curriculum that naturally increases in complexity as the solver improves.
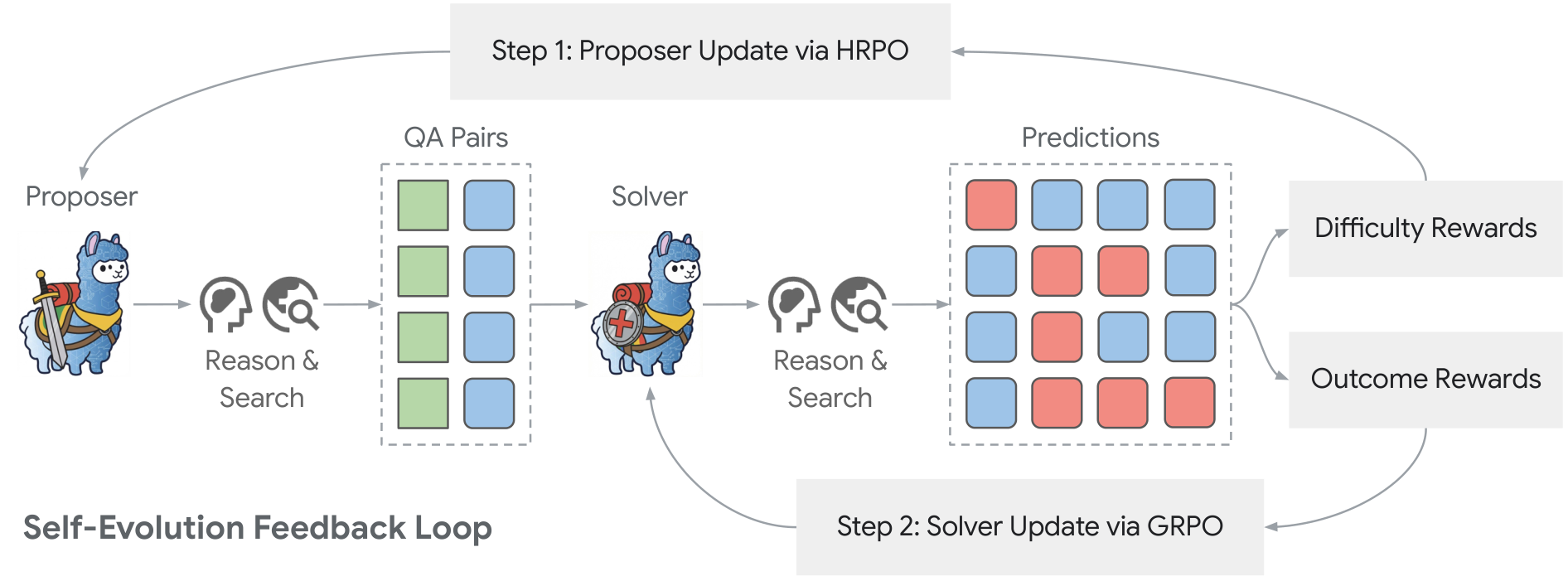 Dr. Zero ArchitectureThe self-evolution feedback loop showing how the proposer generates questions that feed into the solver, with solver predictions generating both difficulty rewards for proposer training via HRPO and outcome rewards for solver training via GRPO.
Dr. Zero ArchitectureThe self-evolution feedback loop showing how the proposer generates questions that feed into the solver, with solver predictions generating both difficulty rewards for proposer training via HRPO and outcome rewards for solver training via GRPO.
The proposer is trained using a novel method called Hop-Grouped Relative Policy Optimization (HRPO). Instead of the expensive nested sampling required by standard group-based RL methods like GRPO [3]--which would generate multiple questions, each requiring multiple solver predictions--HRPO clusters questions by their structural complexity (measured in "hops" or reasoning steps). This grouping allows computing group-level baselines without nested sampling, reducing computational overhead by approximately 4x while maintaining training stability.
Multi-Hop Question Generation
A significant challenge in prior zero-data approaches was generating diverse, complex questions. Existing methods tended to produce simple one-hop queries, limiting the solver's development on multi-step reasoning tasks.
Dr. Zero addresses this through a multi-turn tool-use rollout pipeline that enables the proposer to generate questions requiring 1-4 reasoning hops. The proposer can use search to ground questions in factual information, then chain multiple facts together to create complex multi-hop queries. The default training uses a 4:3:2:1 ratio for 1/2/3/4-hop questions, balancing fundamental capability building with complex reasoning development.
Results: Matching Supervised Performance
The evaluation spans seven QA benchmarks, including three single-hop datasets (Natural Questions, TriviaQA, PopQA) and four multi-hop datasets (HotpotQA, 2WikiMQA, MuSiQue, Bamboogle). All methods use the same search engine (E5-base) and corpus (English Wikipedia).
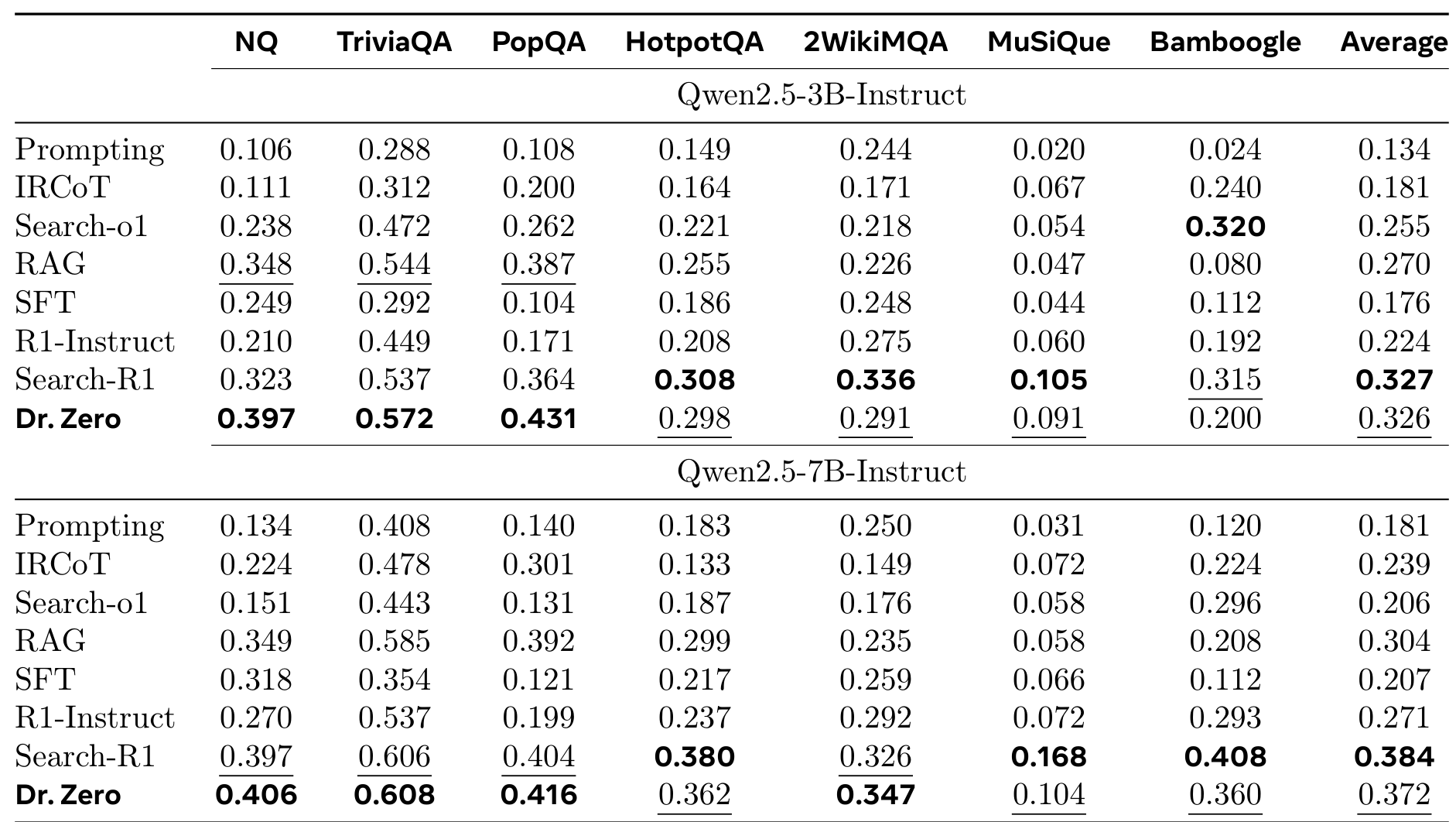 Main ResultsPerformance comparison showing Dr. Zero matching or exceeding Search-R1 on single-hop tasks and achieving competitive results on multi-hop benchmarks, all without using any training data.
Main ResultsPerformance comparison showing Dr. Zero matching or exceeding Search-R1 on single-hop tasks and achieving competitive results on multi-hop benchmarks, all without using any training data.
On single-hop tasks, Dr. Zero with the 3B model outperforms the supervised Search-R1 by 22.9% on Natural Questions, 6.5% on TriviaQA, and 18.4% on PopQA. The 7B variant achieves similar or better results, reaching 0.406 exact match on NQ compared to Search-R1's 0.397.
For complex multi-hop reasoning, the picture is more nuanced. The 7B model achieves approximately 90% of Search-R1's performance on most multi-hop benchmarks and actually exceeds it on 2WikiMQA by 6.4%. However, on the challenging MuSiQue benchmark, which requires compositional reasoning, Dr. Zero still lags behind supervised approaches.
Compared to other zero-data methods, Dr. Zero shows substantial improvements. Against SQLM* and R-Zero* (both augmented with search capabilities), Dr. Zero achieves 39.9% and 27.3% average improvements respectively, demonstrating the effectiveness of its proposer-solver architecture and HRPO training.
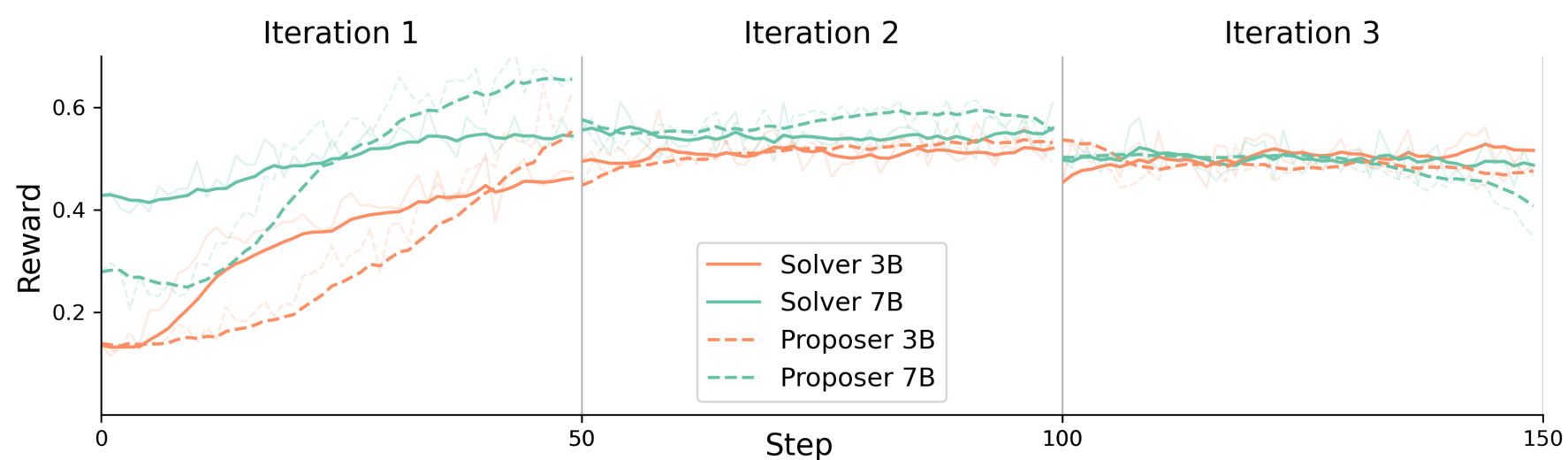 Training DynamicsReward curves showing how proposer and solver co-evolve across three training iterations, with downward shifts in baseline rewards reflecting the increasing challenge level.
Training DynamicsReward curves showing how proposer and solver co-evolve across three training iterations, with downward shifts in baseline rewards reflecting the increasing challenge level.
Research Context
Dr. Zero builds on several strands of prior work. The proposer-solver co-evolution concept comes from R-Zero [2], which demonstrated zero-data self-improvement for mathematical reasoning. Group-based RL methods, including GRPO used for solver training, were developed in DeepSeekMath [3]. The comparison baseline, Search-R1 [1], represents the state of supervised training for search-augmented agents.
What's genuinely new:
- HRPO: A novel optimization method that clusters questions by hop count for efficient single-sample training
- First successful application of zero-data self-evolution to open-domain search agents (prior work focused on math/coding)
- Difficulty-guided reward design that creates optimal challenge levels automatically
Compared to Search-R1, the strongest supervised alternative, Dr. Zero trades slightly lower performance on the most complex multi-hop tasks for complete independence from human-curated data. For scenarios where labeled data is unavailable or expensive, Dr. Zero offers a compelling alternative.
Open questions remain:
- Can the self-evolution plateau observed after 2-3 iterations be overcome with architectural changes?
- How would Dr. Zero perform with live web search instead of static Wikipedia retrieval?
- What prevents larger models (70B+) from benefiting as much as smaller ones from this approach?
Limitations
The authors are transparent about current constraints. Training typically plateaus after 2-3 iterations, suggesting fundamental limits to how much self-evolution can achieve. The 7B model shows more training instability than the 3B variant, with token ID inconsistencies causing occasional failures. Entropy collapse in larger models limits indefinite self-improvement.
Perhaps most importantly, performance on the hardest multi-hop benchmarks like MuSiQue still falls short of supervised methods, indicating that some reasoning capabilities may genuinely require human-curated examples to develop fully.
What This Means
Dr. Zero demonstrates that the gap between supervised and zero-data training for search agents may be smaller than previously thought. For single-hop factual questions, zero-data methods can already match or exceed supervised performance. For complex reasoning, the gap narrows with model scale.
The practical implications are significant. Organizations can now train capable search agents without investing in expensive annotation pipelines. The open-source release, complete with reproduction code and pre-built training scripts, makes this immediately actionable for practitioners.
Check out the Paper and GitHub. All credit goes to the researchers.
References
[1] Jin, B. et al. (2025). Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv preprint. arXiv
[2] Huang, C. et al. (2025). R-Zero: Self-Evolving Reasoning LLM from Zero Data. arXiv preprint. arXiv
[3] Shao, Z. et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv preprint. arXiv


